Introduction
Machine learning projects start by building a proof-of-concept or a prototype. This entails choosing the right dataset (features), the appropriate ML algorithm/model and the hyper-parameters for that algorithm. As a result of a POC, we would have a trained ML model which can do inference on some test dataset.
But having trained a model, with good performance on the test data, does not mean we are done building an application that uses ML; we need to build a pipeline that will enable us to ingest new data as it gets generated, validate the data, retrain the model and validate it, and to make it available for serving. Additionally, when taking the model to production, we need to consider things like:
- Data drift: Depending on the application, the data that we have trained the initial model on might change with time. We need to retrain the model regularly as new data becomes available.
- Data quality: With the need to retrain the model regularly comes the need to check for possible issues in the new data, such as missing data or anomalies. This might creep up due to problems with the source which is generating the data, such as a sensor malfunction.
- Training-serving skew: We must be sure that whatever transformations we make during the model training are also made on the new input data during inference.
Since we are talking about running the application in production, the steps above need to be automated, so our production infrastructure needs to enable:
- Scalability: We need to be able to handle as much data as needed for the specific application.
- Orchestration: The application must execute all the steps without human intervention.
This is where TFX comes into play: enabling you to build the pipeline with predefined components needed for each step mentioned above.
TensorFlow Extended is the framework that enables us to take these steps in order to push out POC to production while avoiding writing a lot of additional boilerplate code typically needed to ensure we take the necessary steps mentioned above. In short, TFX automates the process of retraining an ML model on new data. TFX is useful for the sole purpose of putting an already trained ML model into production—after we have decided on the features we want to use, we have chosen which type of model we will use as well as perform the hyper-parameter tuning.
TFX components
TFX is a library of components that correspond to the best practices for putting ML systems to production together with a predefined way on how to orchestrate these components into an end-to-end pipeline.
TFX comprises several different components, each with a specific function needed in a prediction ML environment. They handle things like reading data from different sources, gathering stats on the dataset, transforming the dataset, doing the actual training and pushing the model for serving. The nice thing is that:
- You don’t need to write the code to execute the specific task for which there is a component.
- If you want to change this like the place you read data from, you can just change the component for reading the data and not touch the rest of the code.
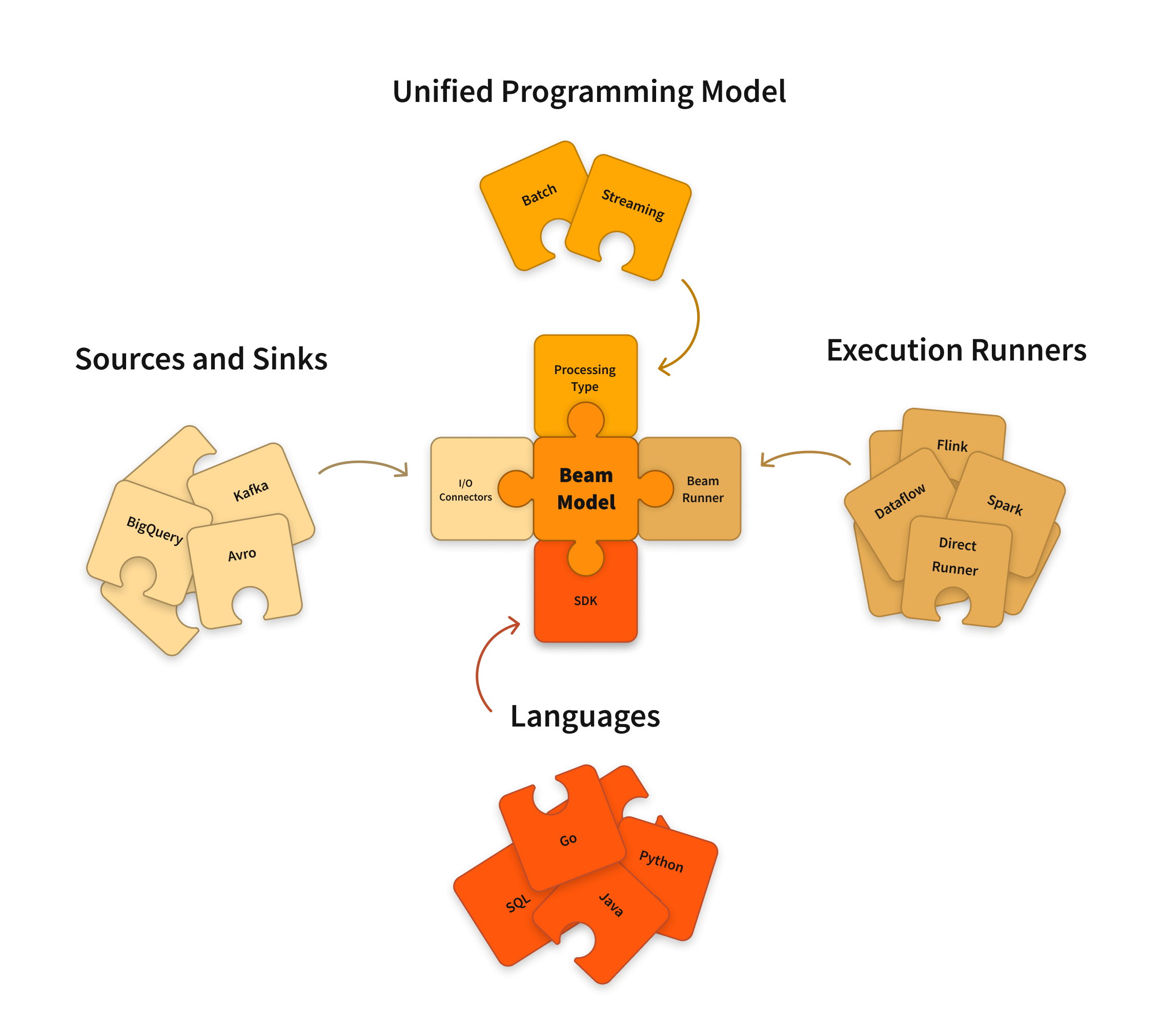
The components are combined into a pipeline which will be executed by an orchestration engine such as Kubeflow, Airflow or Apache Beam.
In order to be scalable, specific components that need to process the data use Apache Beam for the processing, which can operate on different runners such as GCP Dataflow.
One other important aspect that TFX handles and is needed in a production ML pipeline is managing the metadata about the artefacts created in the process. These include things like dataset being used for training, dataset schema, stats, transformed data, trained model, etc. These are important for determining the lineage of trained models. For example, we need to be able to answer questions like:
- What dataset has been used to train the latest model that is pushed to serving?
- What performance metrics did we get from the evaluation?
ExampleGen
The ExampleGen component reads the data. Out of the box it can read CSV files from GCS or read data from BigQuery. It shuffles the data and separates it into training and evaluation splits. As you may notice, it does not create a test split by default, as the idea in TFX is not to develop a new model or tune hyperparameters; you don’t need the final test split to test the model after hyperparameter tuning. The idea is to have the evaluation split just check the newly trained model on part of the new data and to measure its quality.
SchemaGen and StatisticsGen
These are simpler components: SchemaGen deters the feature names and their type, and StatisticsGen collects stats over the dataset. These will be later used during data transformation (preprocessing).
Transform
As the name suggests, this component transforms the data so they can be used for training the model. It is based on a separate library TensorFlow Transform (TFT), which has functions for scaling numerical features and converting categorical features into numerical ones.
The user needs to specify a script based on the TFT library while specifying the transformation on each of the features. Under the hood, the transformations are made using Apache Beam. Apache Beam is a generic library for scalable data processing and an abstraction layer that can run the processing tasks on different runners, depending on the infrastructure we want to use. During testing of the TFX pipeline, we can use a “local” runner—which executes the operations in the current context—such as a Jupyter Notebook, or we can scale the processing by using Google’s Cloud Dataflow as a runner.
The output of the Transform component is not just the preprocessed data but also a TensorFlow transformation graph, which can be used during the inference. This prevents the chance of a divergence between the preprocessing done during training and inference, which can occur if we change the preprocessing script during the training but forget to change the one we use for inference.
Trainer
The Trainer component runs the actual model training. The user specifies a script that the trainer runs either locally as a Kubeflow job or Google Cloud AI Platform job. The training is done using the train split created using the ExampleGen and preprocessed by the Transformer. As an output artefact, we have the trained model.
Evaluator
In order to verify the quality of the new model, the Evaluator component evaluated the model generated by the Trainer using the eval split generated by the ExampleGen. The user can set different thresholds for the metric we get from the evaluation, depending on the model being evaluated and if it is a classification or a regression model. If the evaluator finds that the model exceeds the threshold, it will “bless” the model to be pushed for inference. We can also set up the Evaluator so it compares the performance of the newly trained model with the performance of the previous model, thus making sure we always have a model with optimal performance used for inference.
Pusher
The final step is pushing the model for inference, which depends on if the model has been “blessed” by the Evaluator. If not, we will continue to serve the existing model.
Serving the model is done by TensorFlow Serving, or we can use Google AI Platform Serving as a managed service .
You can find more details about each component here.
Orchestration
Running things in production means we need to execute the TFX components in a specific order every time automatically without (or with minimal) human intervention on a regular basis—i.e. whenever we need to retrain the model on new data. So we need to orchestrate the pipeline.
Out of the box, TFX supports Orchestration by using Kubeflow Pipelines, Apache Airflow or Apache Beam. During testing, you can use the so-called Interactive Context and execute the components one by one. There is a good example and way to start using TFX in this tutorial.
If you run your ML application in Google Cloud, a good way to orchestrate the pipeline would be to run it in the GCP AI Platform pipelines, which is a managed Kubeflow Pipelines environment.
I hope this was helpful. If you have any questions or thoughts, please leave them in the comments.