One of the biggest drivers of cloud adoption is the promise of tightly integrated first-party services. Microsoft applied this idea to the analytics space by crafting and releasing Synapse Analytics back at the end of 2019. With integration as part of the core design drivers of the service, it bundles the SQL MPP, SQL serverless, Spark and data pipeline development experience all in one place.
Moreover, Synapse provides even more points of integration that are sometimes overlooked by data architects when planning their deployments and I wanted to highlight some of these, share links and provide usage ideas in this post. Synapse is a very versatile service and integrates well with third-party services that live in the Azure cloud, such as Snowflake and Databricks as well.
Let’s look at each in detail.
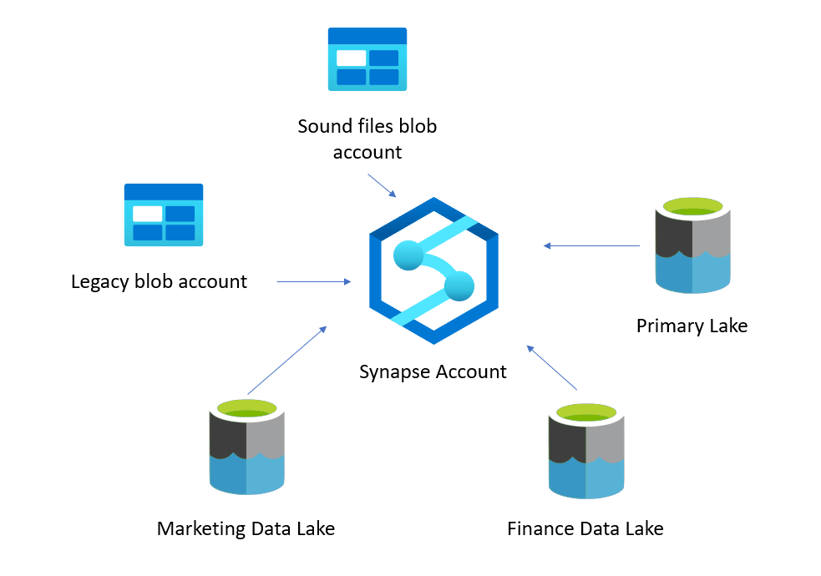
Azure Storage and Synapse
This one is obvious, but hear me out. Every Synapse implementer knows that Synapse works fully integrated with the assigned Azure Data Lake storage account that’s set as its primary storage. However, Synapse–whether primary or not– is very easy to integrate with any storage account This includes not only Azure Data Lake, but also Blob Storage containers.
This enables the implementation of the Data Zone concept and a lightweight version of a data mesh architecture without having to deploy multiple Synapse accounts and deal with the management and overhead cost of doing so.
Cosmos Db and Synapse
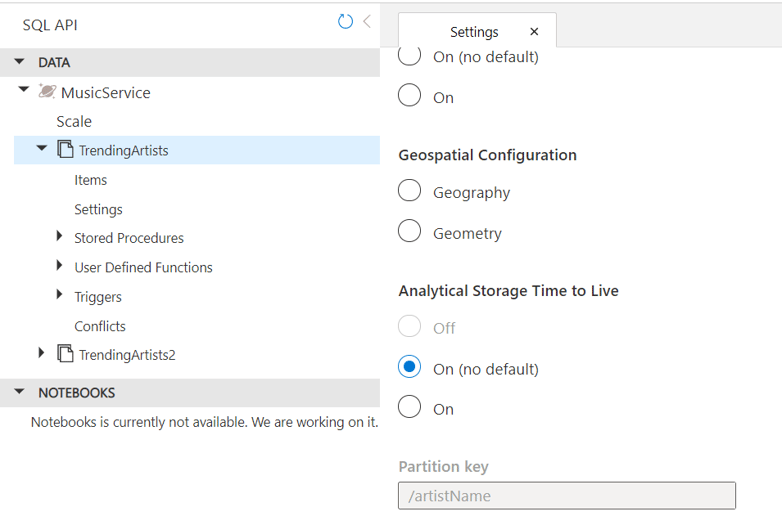
Cosmos Db is a great solution for a no-fuss distributed database with global capabilities. It also has a very cool integration with Synapse through a feature called Synapse Link. It allows you to enable a setting on the Cosmos Db container and from there on, the service will keep a copy of your data in “analytical storage,” a compressed columnar format optimized for analytical queries.
This fully managed analytical storage can then be accessed seamlessly from Synapse, opening the door to near real-time analytics on operational data with zero code, zero ETL and no infrastructure management. On the Cosmos Db side, you pay for the storage consumed by the analytical storage, the compute cost comes from the Synapse side and it doesn’t impact your Cosmos Db workload performance.
The feature is easy to enable on the Cosmos Db portal blade:
Azure Stream Analytics and Synapse
Azure Stream Analytics allows for in-flight querying of streaming data from Blog storage, Data Lake Storage, IoT Hub or Event Hubs. The querying is done through an easily adoptable SQL language and it really speeds up the development of a streaming solution.
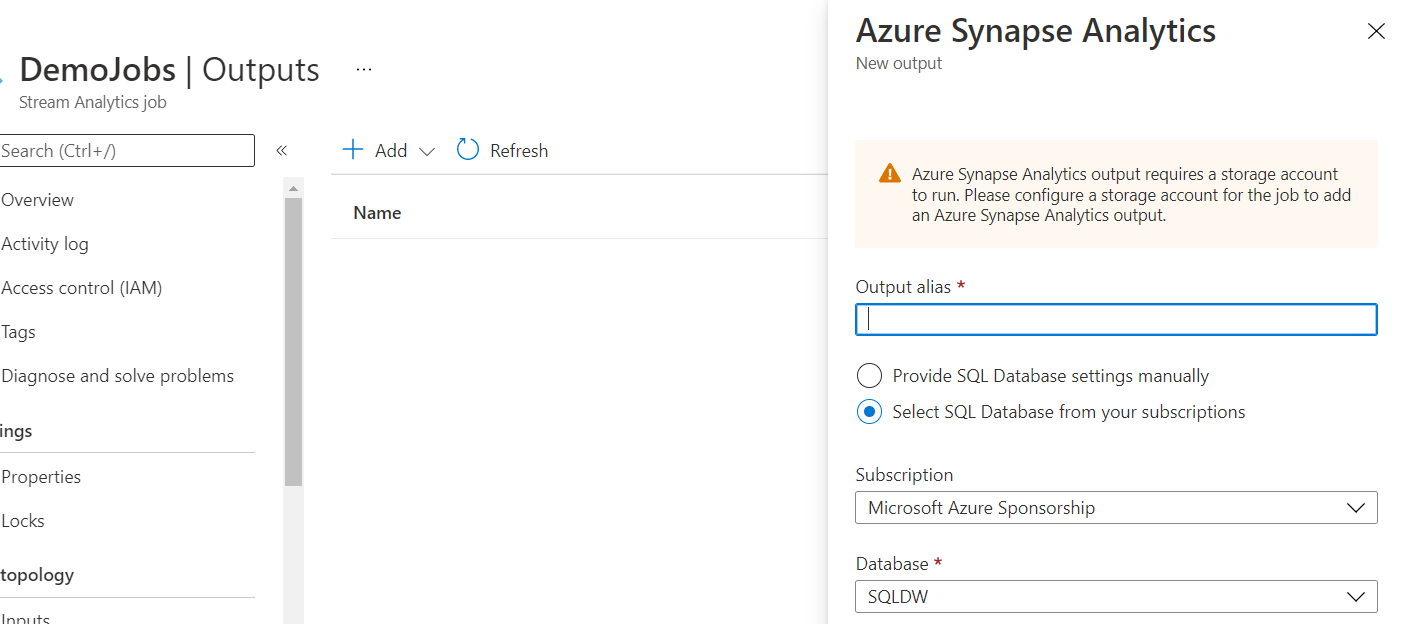
The nice thing here is that Stream Analytics allows the use of a Synapse SQL Pool table as the target for the results of the streaming query. So, this is another way to do near real-time analytics by passing data from a streaming source through a Stream Analytics job and into a Synapse table. You could do this to pre-aggregate data on the fly, score data in real-time, perform real-time calculations over specific time or event windows, etc.
The configuration is very easy and can be done all through the Azure Portal:
Azure Machine Learning and Synapse
As the premier analytics service in Azure, users expect that Synapse should interface with Azure Machine Learning (ML) services and it does so very well.
First, you can use Synapse as the computer provider for your Azure ML needs, whether to train or score. This enables ML to work with volumes of data beyond what’s possible in a data scientist workstation, but also integrates the entire lifecycle of the experiment with the ML Flow capabilities provided by Azure ML in terms of versioning the dataset, the experiment settings and the resulting model.
The Spark capabilities in Synapse have also been augmented to allow for GPU powered clusters, as well as integration with Microsoft’s new ML library called SynapseML.
In addition, the Synapse user experience team has added highly accessible GUI options that lead the user through training a model or scoring with a trained model with Azure ML directly from the Synapse workspace environment:

Snowflake and Synapse
Azure is a great place to run Snowflake and Azure Data Lake Storage is easy to integrate with this very popular data platform service.
Snowflake interacts with cloud storage through the concept of file stages and both Azure Blog Storage and Azure Data Lake are supported as underlying storage locations for file stage:

Once file stages are created, Snowflake supports querying the files directly or defining a schema for External Tables. Either of these options can then be used for writing SQL or even Scala or Python through the Snowpark capability.
Once you’re done with your computations in Snowflake you can easily write back to the Azure stages and this data can be picked up by any of the Synapse engines. The other direction works just as well; use Synapse to write files in the Azure storage that can then be picked up by Snowflake through any of the mechanisms mentioned above.
You might be wondering why you’d need Synapse if you’re using Snowflake. Snowpark is still in preview and doesn’t yet offer the full capabilities found in Apache Spark, which is offered inside Synapse as a way to combine with your Snowflake implementation. Also, Snowflake doesn’t offer an ETL orchestration tool and some scenarios won’t be covered solely with Snowflake tools like Snowpipe. In this case, you could use Synapse Pipelines for ETL processing and still use Snowflake as your main warehousing or data lake engine.
Databricks and Synapse
Databricks and Synapse can integrate quite well through three main points:
- The ability to interact transparently by reading and writing to Data Lake storage accounts. Like Snowflake, this allows for maximum flexibility since you only need to provide a common staging area for both services to share data, as long as you stick to common formats.
- The ability of Synapse’s SQL Serverless pool to support Delta tables. Everyone implementing Databricks is making use of their fantastic Delta tables that bring in many extended capabilities to Spark tables. This type of table is also supported by the Synapse catalogs and serverless pool so they can be queried transparently through T-SQL as well.
- Databricks actually supports interacting directly with Synapse and can authenticate to the SQL pool to read and write data. This is officially documented HERE.
Azure DevOps/GitHub and Synapse
One aspect of Synapse that absolutely stands out is the tight integration with source control and CI/CD capabilities. You have a choice of linking your Synapse code artifacts to either Azure DevOps or GitHub. Once integrated, the Synapse graphical interface allows direct access to committing changes, creating new branches and pulling requests straight from the workspace.
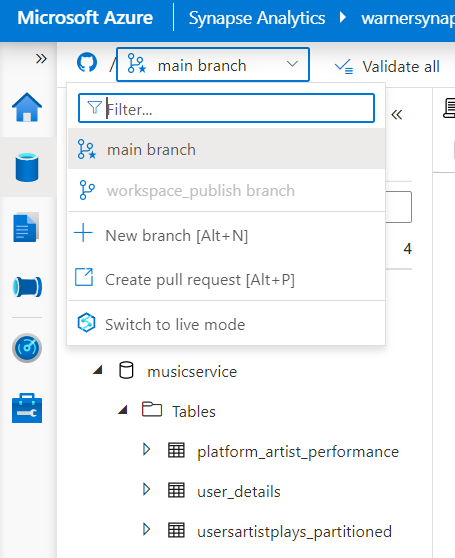
This is a great way to not only enforce versioning and bring DevOps capabilities into your data development, but also allow integration with release jobs for deploying new pipelines, scripts or notebooks to a production environment through Azure Devops pipelines or GitHub actions.
Conclusion
Synapse is a very versatile service that not only provides a tightly integrated experience inside its workspace, but also with a myriad of other Azure and third-party services. The list I provided here isn’t exhaustive (I left out the strong integration with Power BI), but the ability to easily integrate makes it very compelling for building an enterprise data platform.
Have you used Azure Synapse for integrations lately? Drop any questions in the comments and don’t forget to sign up for the next post.
Share this
Share this
Analytics with Limitless Scale on Microsoft Azure - Part 1
