As machine learning becomes more widely used for automated decision-making, we must identify issues of fairness in ML outcomes. Ensuring fairness in ML is important for several reasons; lack of fairness in machine learning can perpetuate or amplify societal biases and discrimination and lead to incorrect or harmful decisions. For example, suppose an ML model used to identify ideal job candidates during hiring is trained on data that is biased away from certain groups of people. In that case, the model may recommend candidates from those groups less often, leading to fewer opportunities and potentially amplifying existing inequalities
Machine learning algorithms are not inherently biased. They are mathematical functions which become models once they are trained on data. Models mirror the data that feed them; if this training uses biased data, then the result could be a biased model. Even so, choices around algorithms could increase or decrease the effect of those biases. Since model predictions can impact people’s lives, we want these predictions to be determined by relevant, appropriate factors.
We know that perfect machine learning models are rare. If every machine learning model is likely to make some mistakes, how can we ensure that no one subgroup in the input data is identified with an undue proportion of these mistakes? We aim to ensure that bias or under-representation in the data doesn’t lead to incorrect causal conclusions, which can result in unjust or prejudiced conclusions. Below we give a snapshot of some methods to tackle this while recognizing that this is a more profound topic and that these methods are an area of ongoing research.
How do we measure fairness?
Here, we present three ways of measuring fairness. We’ll use the notation of Y being the correct label, ? being the label predicted by a model, and A a protected attribute within the input data. For simplicity, we’ll assume that A and Y each consist of two classes labelled 0 and 1. This can be extended to a larger number of classes. We’ll include comments on how each notion of fairness might appear in an imagined employment or lending prediction scenario, with the age of a candidate or user being a protected attribute.
Demographic Parity
Demographic parity is satisfied if predictions do not depend on a protected attribute. That is,
P(Ŷ | A=0) = P(Ŷ | A=1)
The effect of using demographic parity is an increase in inclusion that may not have been historically present.
Example: Predictions for employment or lending do not incorporate information about the age bracket of the person in question.
Equalized Odds
For any particular prediction outcome/label and attribute, the model predicts that outcome/label equally well for all values of that attribute:
P(Ŷ=1 | A=0, Y=y) = P(Ŷ=1 | A=1, Y=y) for y in {0,1}
This means that the accuracy of a prediction model is consistent across all subgroups of interest.
Example: “True positive” predictions for employment or lending are equally accurate regardless of the age bracket of the person in question. “True negative” predictions for employment or lending are also equally accurate irrespective of the age bracket of the person in question.
Equality of Opportunity
For a positive prediction outcome/label and a given attribute, the model predicts that outcome equally well for all attribute values. That is,
P(Ŷ=1 | A=0, Y=1) = P(Ŷ=1 | A=1, Y=1)
Similar to Equalized Odds, but only requires equality when Y takes on the positive value since we often think of the outcome Y=1 as the beneficial or “advantaged” outcome. Equality of opportunity is less restrictive and more relaxed than equalized odds. While it is a weaker notion of fairness, it still has utility in cases that strongly emphasize predicting positive outcomes correctly or if false positives do not carry many detrimental effects.
Example: For people who qualify for employment or lending, positive predictions are equally accurate regardless of the age bracket of the person in question. This is not the same as Equalized Odds since the accuracy of rejecting unqualified users may not be the same regardless of age bracket.
Technique: Countering bias in model output
In the paper “Data Decisions and Theoretical Implications when Adversarially Learning Fair Representations,” the authors develop an adversarial training method to remove information about a sensitive attribute from the representation learned by a neural network. The primary approach is developing a secondary model that detects and predicts a sensitive attribute Z, and for a negative gradient associated with this secondary model to be applied to the original model that predicts the label y. The result is that the primary model learns to predict y with much of the information of Z removed from the latent representation in the internal neural network states.
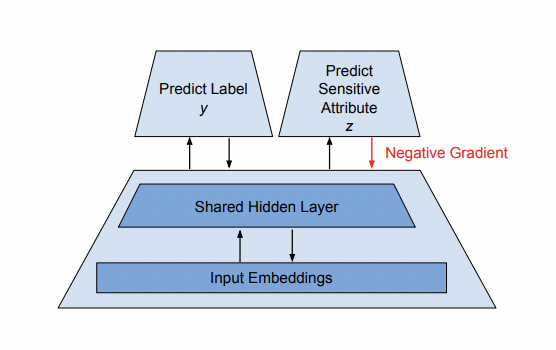
Model for adversarial training
Additional recent approaches
- Winogender: A study of coreference resolution systems with sentences that differ only in the gender of a pronoun.
- CrowS-Pairs: Sentence pairs, one with a stereotype of a marginalized group, one with the group or attribute changed.
- WinoMT: An extension of CrowS-Pairs for machine translation, including some ideas to improve bias by inserting gendered adjectives next to professions the model would otherwise start associating with one gender or the other.
- Model Cards for Model Reporting: Provides analysis alongside trained machine learning models across different demographic groupings, allowing users to identify bias or fairness issues in ML systems.
- Analysis of GPT-3: Includes finding several problems directly (gender-associated professions) and some by applying it to biased datasets (including Winogender).
- StereoSet: Quantitative assessment of stereotypical bias in language models
Share this
Share this
How to Deploy Machine Learning on Google Cloud Platform
