Share this
by Pythian Marketing on Jan 4, 2018 12:00:00 AM
“The transformation of the superstructure, which takes place far more slowly than that of the substructure, has taken more than half a century to manifest in all areas of culture the change in the conditions of production. Only today can it be indicated what form this has taken.” - Walter Benjamin, The Work of Art in the Age of Mechanical Reproduction, 1936While Benjamin was actually lamenting the progression of media technology for use in neo-fascist propaganda, he was also describing the critical points where technical evolution produces radical cultural changes, such as what is occurring with serverless computing and cloud services right now. While “serverless computing” hasn’t taken half a century, anyone working in the industry for the past decade at least can appreciate the steady progression from virtualization to containers to serverless architectures. Add to this the convergence of distributed data processing and storage and you have a powerful combination of technologies that are both cost-effective and easy to use for everyone. The top cloud providers all have mature platform and software service offerings that eliminate or at least drastically reduce the need to focus on infrastructure, allowing all sizes of business to spend their time focusing on providing value rather than maintaining technology. In part 1 of this 3-part series, I’ll walk through what cutting-edge serverless and modern cloud services can provide in terms of an analytical data platform and provide suggestions on how to make the technology choices. When considering any data platform the end result, which we will refer to as the data products, has to be the key motivator of all decisions. When we refer to data products, we speak of regular analytic reporting, automated decision making through machine learning, or specifically identified business decisions supported by ad hoc data analysis. To be clear about what technologies we are referring to, please see the candidate technical stack below with representative services from three of the most prominent cloud providers.
Serverless options on the cloud
Common architecture components in the technical stack. While there are obviously going to be differences in the functionality and maturity in the various cloud services listed, they are, for our considered use cases, functionally equivalent.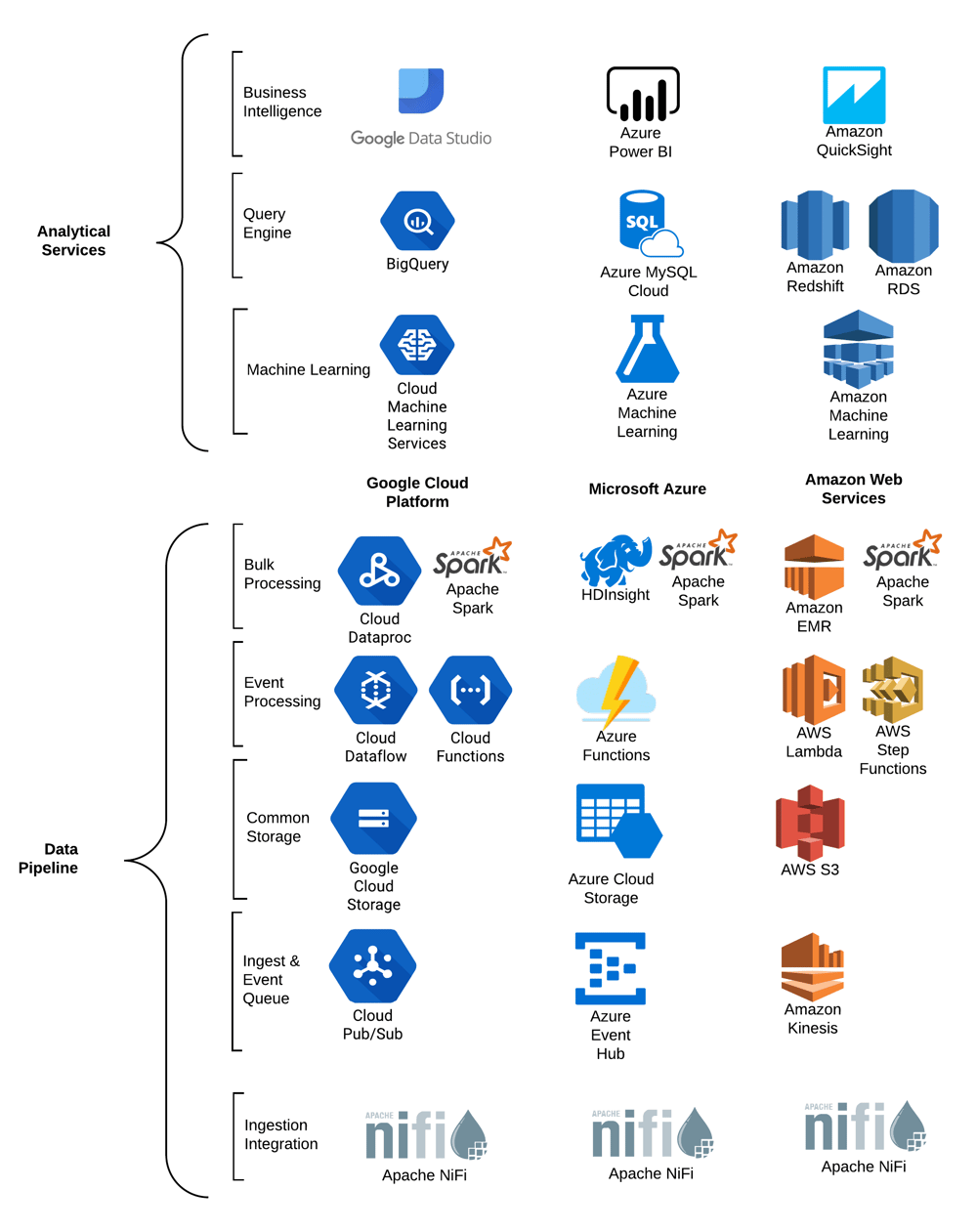
Data Pipeline:
Ingestion Integration
This component is responsible for collecting data from a multitude of sources, pushing it onto the event queue, and/or pushing it into the cloud storage layer. This represents the glue to the rest of the enterprise or other external data sources. While there are other cloud service options, this solution remains superior for a general ingestion framework. It is worth noting that this has not yet been absorbed into a cloud service so this solution requires deployment in docker containers on container management services, available on all 3 of the listed cloud providers.Ingest & Event Queue
This is the distributed queue mechanism that represents the heart of an event-driven data platform. What differentiates these services from regular queues is that they are distributed and they are capable of serving many concurrent consumers using the same stream. These services are functionally equivalent to Apache Kafka, but are Platform As A Service (PaaS) removing the need to manage the Linux OS and Kafka daemons. All of the cloud services tend to have excellent integrations with stream and cloud function components making integration extremely easy.Common Storage
This is highly available and scalable cloud object storage, of which AWS’s S3 is the most famous example (despite Google File System preceding S3 by a few years). In a cloud-based architecture this functionally equivalent to Hadoop’s HDFS filesystem and is used in place of it in this architecture. This serves as the file storage for nearly all of the cloud service components.Event Processing
Working off of the Ingest & Event Queue, event processing is the heart of the data pipeline. This includes, but is not limited to, data cleansing, feature/prediction creation, and aggregations. Since many, if not most, of these operations tend to be atomic (one operation per one event of data), serverless cloud functions are used to high efficiency. The cloud functions are simply snippets of code that are executed for every record read from the Event Queue, there is no need to worry about running clusters of servers to handle the workload, this is all done by the cloud service itself. In the event that more complicated streaming operations are needed, such as aggregations over multiple records (counts, averages, quantiles) for real-time analytics, we can use more complicated event processing engines available in the cloud services. In very complicated event processing scenarios that do not tight time constraints on the reporting end, we can push this work to bulk processing.Bulk Processing
Generally, this is the more traditional batch-based processing of multiple records from either the Ingest & Event Queue or directly from Common Storage. This is technology service is typically everyone’s favorite distributed data processing weapon of choice: Apache Spark. Spark can be used in batch and micro-batch stream processing and also contains a decent Machine Learning library. The best way to use Spark in a cloud server architecture is to create clusters dynamically when data is available to process, process the data, then tear down the cluster automatically. This ensures that there is no excessive cost from an idle cluster. We all wait with bated breath as cloud services mature to a completely serverless (from the user’s perspective) implementation of Apache Spark where there is no need to manage the cluster. As such, we recommend the use of Cloud Functions unless Apache Spark is absolutely needed.Analytical Services:
Machine Learning
This layer may seem mysterious and complicated to some, but in reality this ends up being a moderately complicated set of data pipelines with specialized functions. In fact, a lot of the preliminary work to prepare data for Machine Learning will occur in the Event and Bulk Processing components previously mentioned. Machine Learning is considered separate from the Event Processing because many of the specialized functions are available as cloud services as are the development tools to create and modify the machine learning models. As this is a deep topic we will cover it later blogs, but is enough to know that the cloud services take care of a great deal of infrastructure and development work that your data scientist or machine learning engineers will not be experts at. The end goal in most Machine Learning services is to create insight to be used independently for automated decisions and/or to enhance Business Intelligence reporting.Query Engine
T his is the common relational SQL database optimized for the scale of data required by our analytical use cases. In most cloud services, this is a fully SQL compliant service with a columnar storage engine quietly hidden behind the scenes. In most cloud services, there are multiple options, including MySQL or SQL Server compliant services with scalable architectures. This common starting point allows a multitude of tools to be used over the database as a service. Data arrives here by way of the Event or Bulk Processing engines.Business Intelligence
Typically this component represents reporting and data exploration tools based on SQL data warehouses. While we have only listed the traditional Business Intelligence tools available on the cloud, you could use many other data visualization or data search platforms. Once the data is in place in a SQL database and sufficiently summarized the tools available by the cloud providers or other SaaS vendors is legion.What does a serverless pipeline look like?
That is a lot of technology to absorb so let’s take a look at what an example data flow would like in an hypothetical online retailer. In this case we will use the Google Cloud Platform components to build a platform to support both a data mart and a near-realtime dashboard. In this simplistic example there are three data sources are used:- Product views by user from the online retailer website
- Orders from the online retail order management system
- Product Catalog update information from file uploads
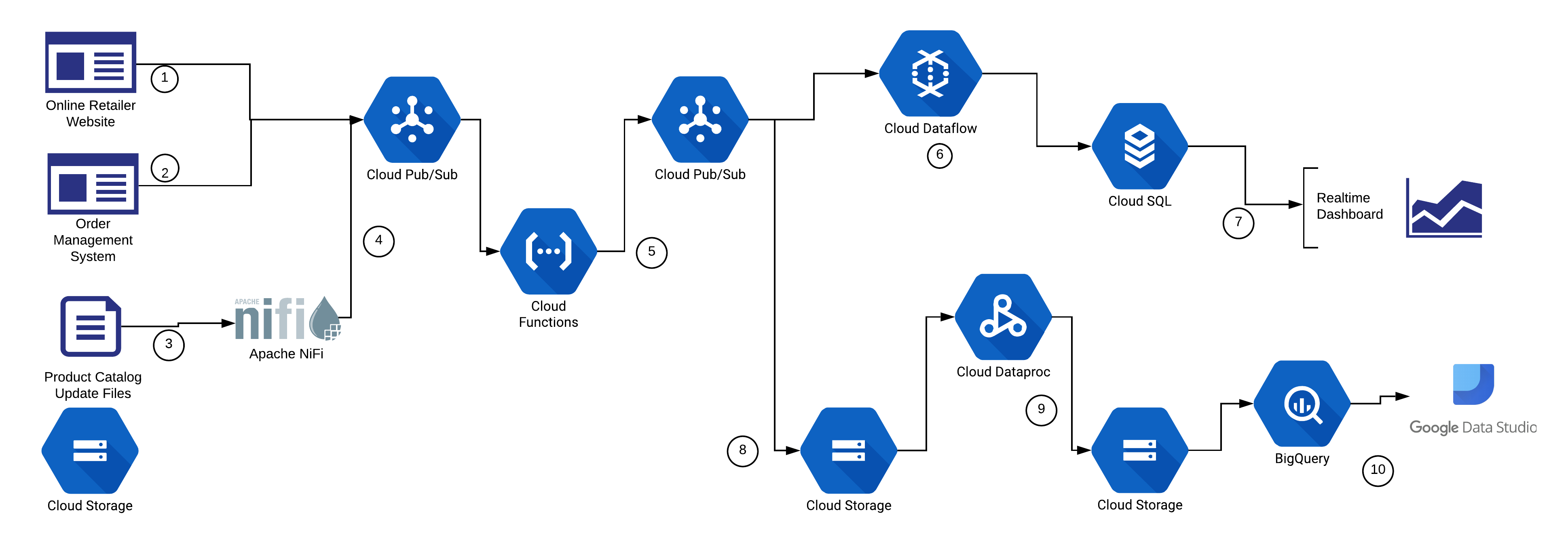 Here’s what’s happening in this example:
Here’s what’s happening in this example:
- The Online Retailer Website application sends event data directly to a Google Cloud Pub/Sub queue through a client embedded in the application.
- The Order Management System application sends event data directly to a Google Cloud Pub/Sub queue.
- Apache NiFi picks up the Product Catalog files automatically from a directory on Google Cloud Storage.
- Apache NiFi parses the Product Catalog update files into events and puts them onto a Google Cloud Pub/Sub queue.
- Cloud Functions are used to cleanse, filter, transform the data. This is written back to another Cloud Pub/Sub queue for downstream consumption.
- Supporting the near-realtime dashboard, a Cloud Dataflow streaming job aggregates the sales for the day and stores the results in a simple Cloud SQL database.
- Completing the near-realtime dashboard use case, a simple web app queries the Cloud SQL database periodically to keep the dashboard up to date.
- Supporting the Data Mart (and potentially other use cases), all data from the processed Cloud Pub/Sub queues in #5 is written to Cloud Storage.
- A set of Cloud Dataproc jobs merges, aggregates, filters, and transforms the combined data into a suitable format for the Data Mart.
- BigQuery reads directly from the files prepared by the Dataproc jobs, allowing analytical SQL jobs to be performed by Business Intelligence tools like Data Studio. Data Studio can be used to compose and regularly query from Bigquery for all Data Warehouse use cases. Data Studio also provides the data visualization features in this example use case.
Why bother with serverless?
So what would compel you to build a data product with the aforementioned technologies? Let’s take at the capabilities this kind of platform delivers and why it is different than what has come before. Here’s our ‘Tight 5’:- Data Engineering and Machine Learning coding efforts will be drastically minimized, allowing for more time for data product innovation.
- Your teams will have easier access to cloud service tools that they did not before. If a team needs critical software, the time to implementation is minutes or hours, not days or weeks. Need a data exploration notebook environment? Spin up a cloud service or a competing SaaS product over your ready data sets.
- Event-based serverless processing reduces the deployment, testing, and maintenance of your infrastructure to a few lines of automation code. This represents a drastic reduction in complexity for getting a working data platform.
- Flexibility. No capital investments. In the leading providers you have per mb/event/second billing. You have completed and immediate control over your environment. If your business needs change then it's completely in your control to alter your environment. Create new products and shelve old ones as fast as your teams can develop them.
- Auxiliary Services: Observability, Orchestration, Authorization/Authentication, Identity/Directory, PCI-DSS, network security, at-rest/in-flight Encryption are already built into the platform. These additional services are often overlooked until implementation but can make or break implementations. It is worth mentioning that a cloud provider usually provides these services for many clients so anything already built into the system has automatically been engineered and tested more than your single organization ever could.
Who adopts serverless?
The initial scenarios for organizations adopting a cloud architecture tend to be:- No existing data platform so there is no transformation cost associated to adopt the latest technologies. This is typical for startups or those rare organizations that have data but have never attempted to extract value from it. This 'greenfield' scenario is also common when you are building a data platform with a mandate to make the data usable, but not a clear understanding how you will extract value from your organization's data.
- Those product or technology leaders in a large organization with a pre-existing data warehouse that cannot provide the capabilities for a new data products or simply cannot keep up with ongoing business needs. In this case we assume that a separate team is looking to extract their organization’s data into a parallel data platform to extract value as quickly as possible and leap-frog forward.
- Those organizations with an existing investment in Hadoop or Spark clusters in on-premise or even cloud-based server instances. Typically these organizations are looking to reduce the time spent on platform maintenance and are looking to utilize analytical services that integrate tightly with the cloud.
Learn more about Pythian’s Cloud Services practice and check out our Analytics as a Service solution (Kick AaaS, a fully-managed end-to-end service that brings your multi-source, multi-format data together in the cloud).
No Comments Yet
Let us know what you think