A data lake is a centralized repository for large amounts of structured and unstructured data to enable direct analytics.The above image illustrates multiple functions of a data lake, such as data ingestion, data indexing, data processing, data analytics, machine learning, and data visualization.
Challenges in building data lakes
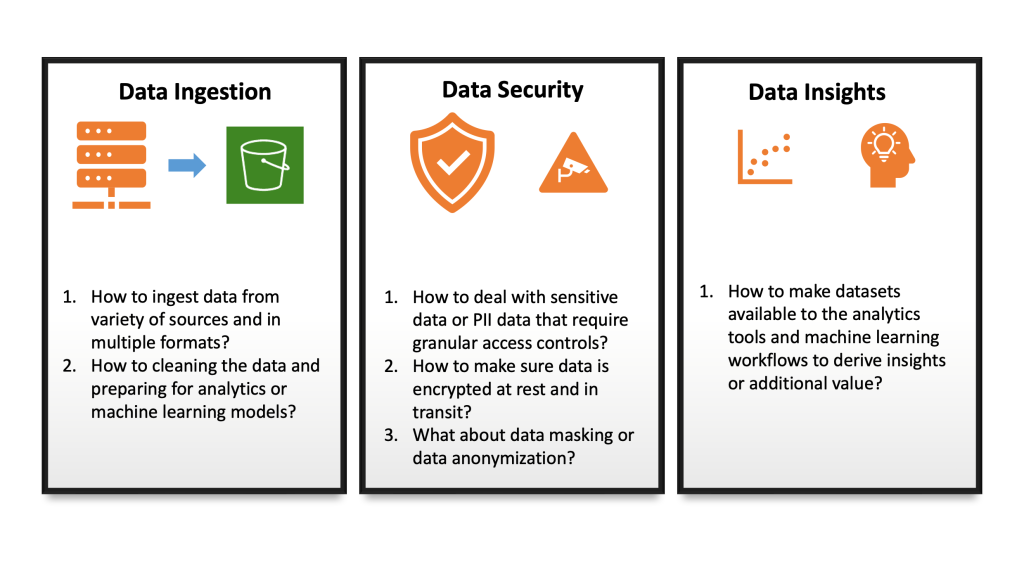
Building a data lake is a time-consuming process and there are multiple challenges that you need to address before creating a data lake. The main challenge with a data lake architecture is that raw data is stored without the oversight of the contents. For a data lake to make data usable, it needs to have defined mechanisms to catalog and secure data. Without these elements, data cannot be found or trusted, resulting in a “data swamp”. Data lakes require governance, semantic consistency, and access controls to meet the needs of wider audiences. Let’s explore these challenges with the below visual representation.
Introducing AWS Lake Formation
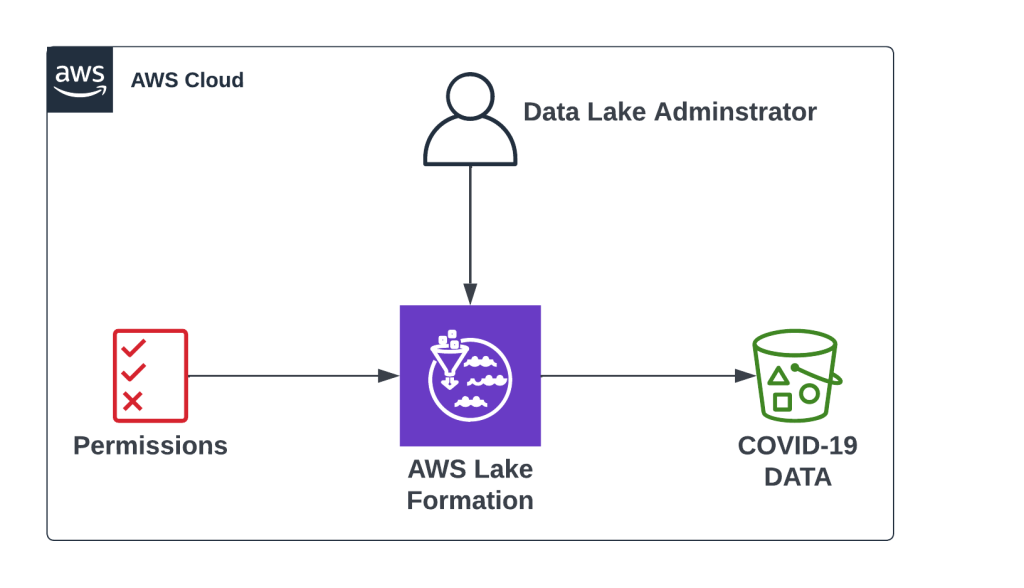
Lake Formation is a fully managed service provided by AWS that enables data engineers, security officers, and data analysts to build, secure, manage, and use data lake.
There are 3 stages to creating your data lake:
Stage 1. Register data lake storage locations.
Stage 2. Create a database in the data lake’s data catalog.
Stage 3. Grant permissions to data lake resources and underlying data.
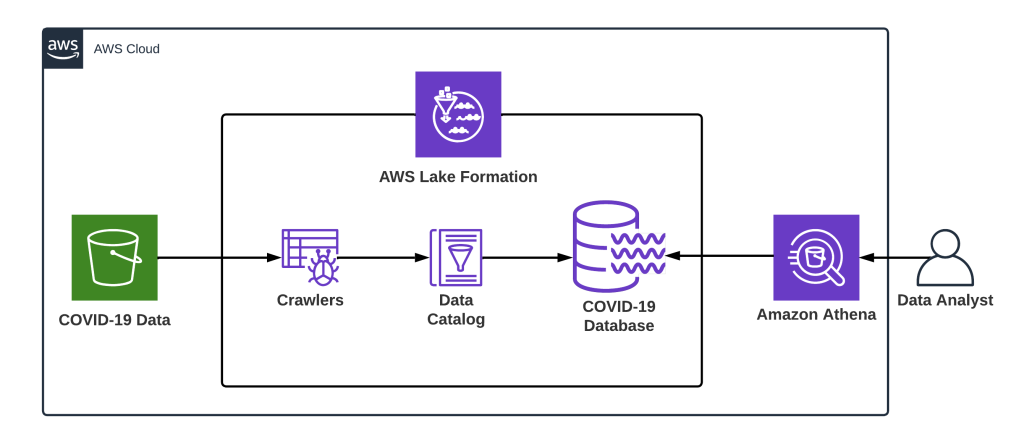
In this post, we’ll build a demo data lake for COVID-19 data using AWS Lake Formation and walk through all the steps involved in building, securing, managing, and using the same. The following resources will be set up in this post:
- Set up a data location with sample files on S3.
- Set up AWS Lake Formation and Create a database.
- Set up Glue Crawler to collect table metadata.
- Query data using Athena.
1. Set up a raw data location in a S3 bucket
We’ll now create a sample bucket to store raw data for COVID-19. Bing COVID-19 data includes confirmed, fatal, and recovered cases from all regions, updated daily. This data is reflected in the Bing COVID-19 Tracker.
The data set can be downloaded here. Following is the list of columns and their sample values:
| Name | Data type | Unique | Values (sample) | Description |
|---|---|---|---|---|
| admin_region_1 | string | 864 | Texas Georgia | Region within country_region |
| admin_region_2 | string | 3,143 | Washington County Jefferson County | Region within admin_region_1 |
| confirmed | int | 120,692 | 1 2 | Confirmed case count for the region |
| confirmed_change | int | 12,120 | 1 2 | Change of confirmed case count from the previous day |
| country_region | string | 237 | United States India | Country/region |
| deaths | int | 20,616 | 1 2 | Death case count for the region |
| deaths_change | smallint | 1,981 | 1 2 | Change of death count from the previous day |
| id | int | 1,783,534 | 742546 69019298 | Unique identifier |
| iso_subdivision | string | 484 | US-TX US-GA | Two-part ISO subdivision code |
| iso2 | string | 226 | US IN | 2 letter country code identifier |
| iso3 | string | 226 | USA IND | 3 letter country code identifier |
| latitude | double | 5,675 | 42.28708 19.59852 | Latitude of the centroid of the region |
| load_time | timestamp | 1 | 2021-04-26 00:06:34.719000 | The date and time the file was loaded from the Bing source on GitHub |
| longitude | double | 5,693 | -2.5396 -155.5186 | Longitude of the centroid of the region |
| recovered | int | 73,287 | 1 2 | Recovered count for the region |
| recovered_change | int | 10,441 | 1 2 | Change of recovered case count from the previous day |
| updated | date | 457 | 2021-04-23 2021-04-22 | The as at date for the record |
Copy the file to S3 using AWSCLI,
aws s3 cp bing_covid-19_data.parquet s3://[BUCKET_NAME]/source
Note: I am using s3://sa-proj-datalake bucket and my IAM user sandeep.arora in my Personal AWS account for this entire walkthrough. Please update the placeholders if you intend to recreate the steps in your environment. The user and bucket have been removed after recording the steps.
2. Set up AWS Lake Formation
To set up a data lake we will do the following:
- Define one or more administrators who will have full access to Lake Formation and they will be responsible for controlling initial data configuration and access permissions.
- Register the S3 path.
- Create a database.
- Provide necessary permissions for the users to access the data lake.
2.1 Define Administrators of Data Lake Formation System
1. Navigate to the AWS Lake Formation and under the Permissions section choose Administrative roles and tasks:
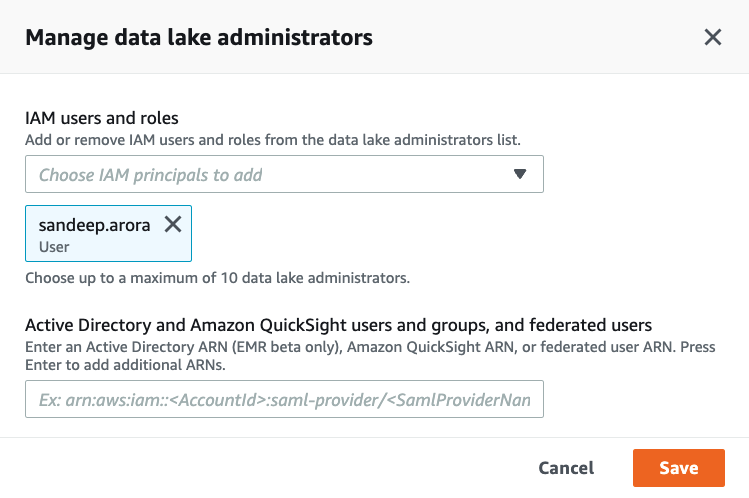
2. Under the Data lake administrators section add your user that you are logged in with and select additional IAM Users or Roles that you want to promote to Lake Formation administrators:

I have added my IAM user as Administrator to Lake Formation system as shown below:
3. In the Data Creators section ensure that IAMAllowedPrincipals Group is granted Create database permissions:
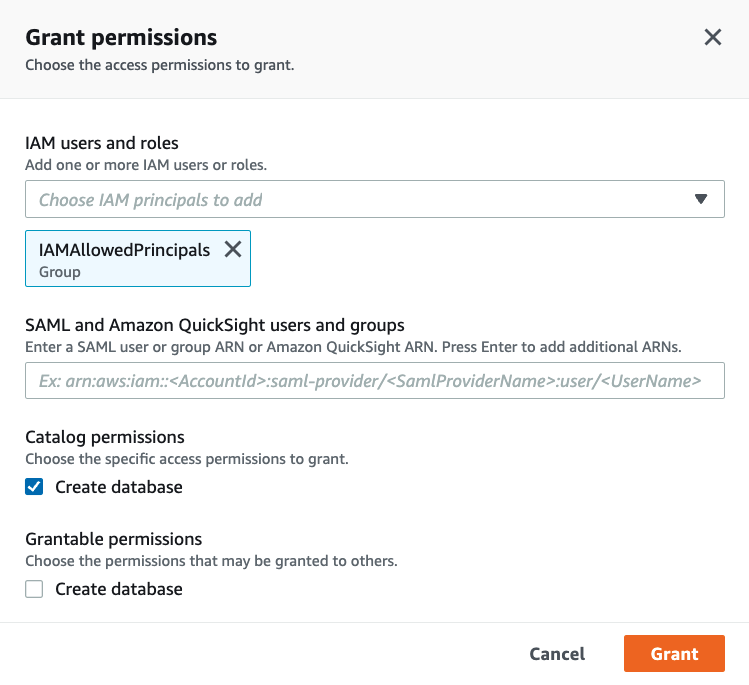
Now that we have successfully set up Administrators for the Lake Formation system we will proceed with registering the S3 location.
2.2 Register S3 Location
Now we will register the location on S3 where we have our raw data set stored.
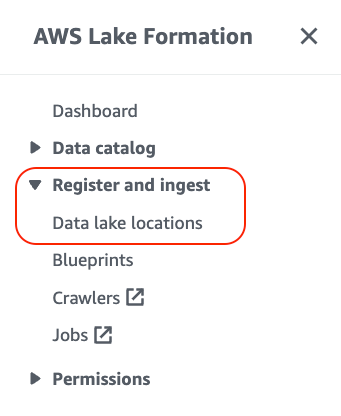
1. Navigate to Data Lake Locations and then from Register and ingest section in the Lake Formation console:
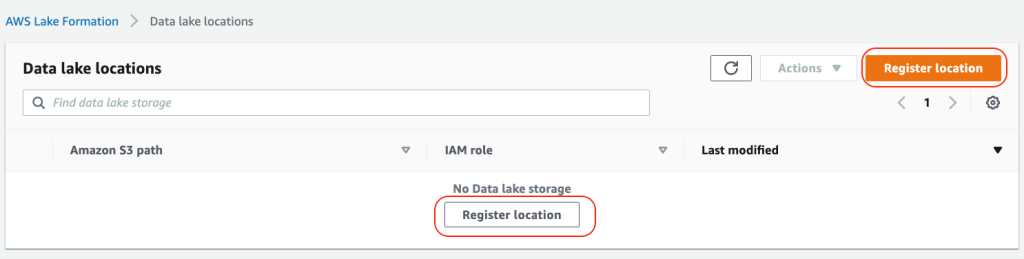
2. Choose Register location to include the S3 storage location as a part of the data lake:
3. Register the data set source location in Lake Formation and use the service-linked role. You must have permission to create\modify IAM roles to use the service-linked role:
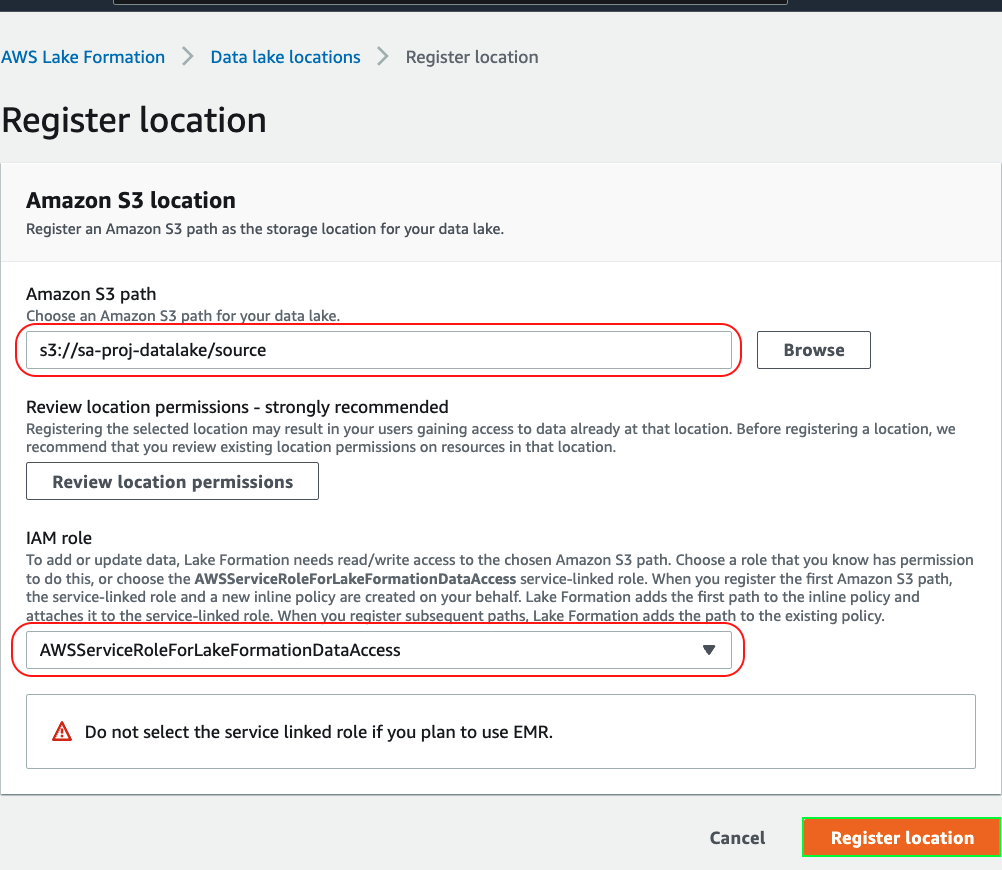
4. Navigate to IAM console, search for the IAM role and view its attached policies:
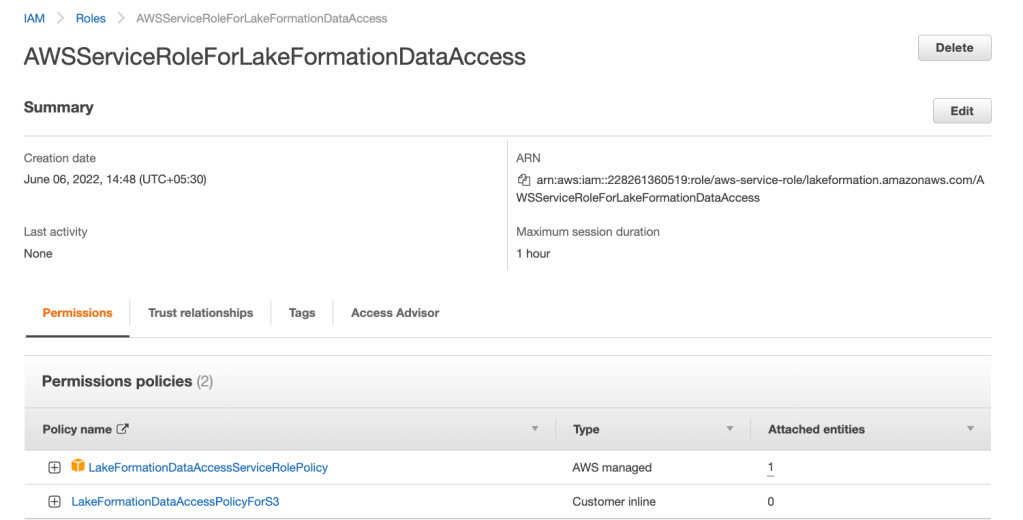
5. When we registered the location in Lake Formation it automatically created the following inline policy and attached it to the service-linked role and this inline policy is managed by Lake Formation:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LakeFormationDataAccessPermissionsForS3",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::sa-proj-datalake/source/*"
]
},
{
"Sid": "LakeFormationDataAccessPermissionsForS3ListBucket",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::sa-proj-datalake"
]
}
]
}
6. Ensure that the location has been registered successfully as shown below:
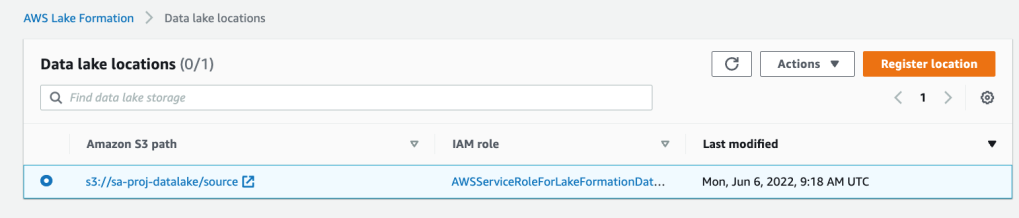
2.3 Grant access to data location and validate permissions
1. Navigate to Data location > Permissions section:
2. Lake Formation allows you to manage access for users, roles, external accounts and etc. We are going to grant permissions to data location to the current user:

3. Grant your current user that you are logged in with permissions to data location as shown below:
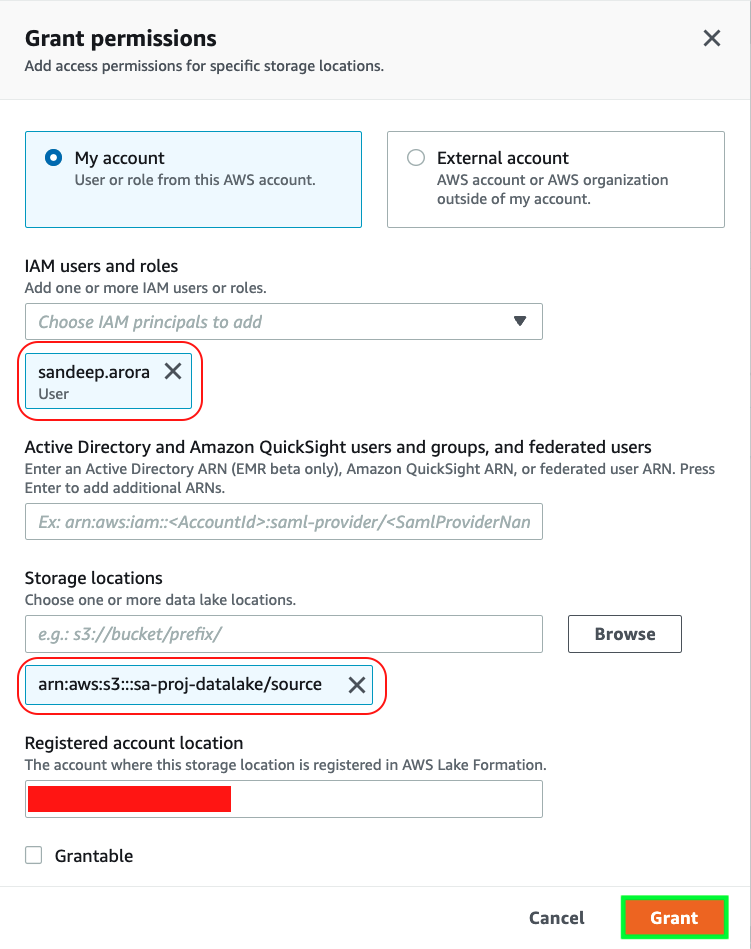
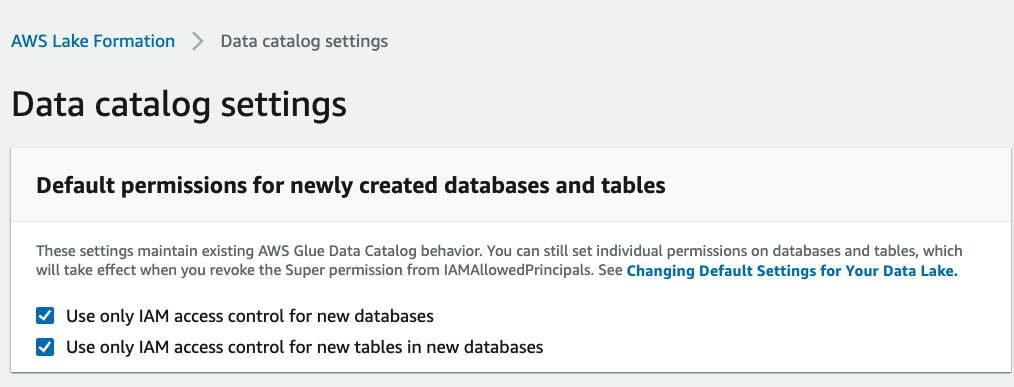
4. Validate permissions for databases and tables. Navigate to Data Catalog > Settings and check if IAM access control is enabled for databases and tables:
2.4 Create a database
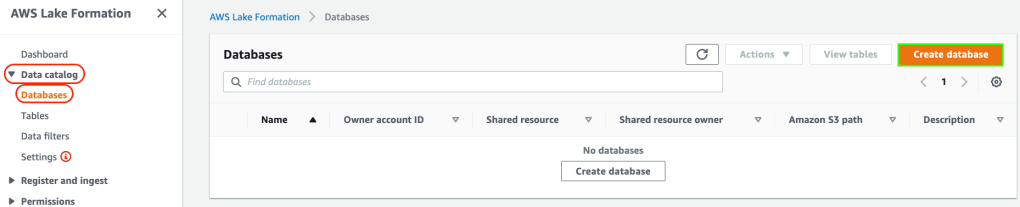
1. To generate metadata and store them in a data catalog we need to create a database. To create a database using the Lake Formation console, you must be signed in as a data lake administrator or database creator. Navigate to Data catalog > Databases and then create a database:
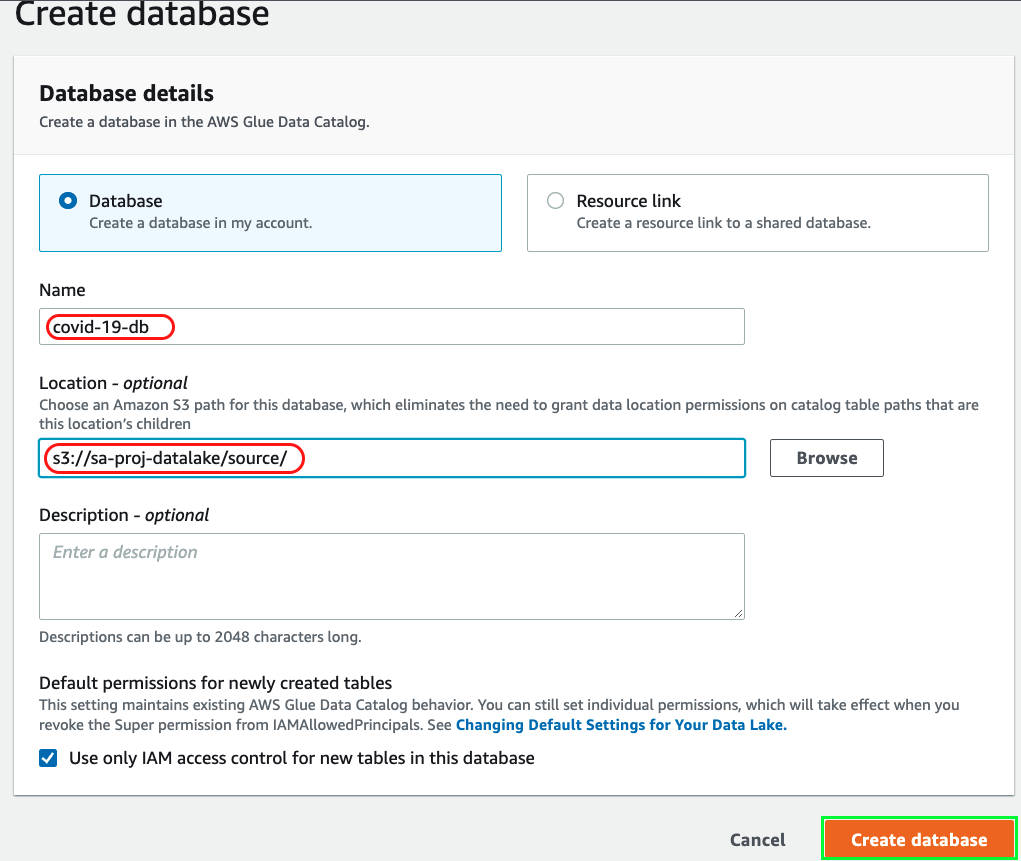
2. Provide the source S3 location and database name as shown below and create the database:
3. Set up crawler to determine schema of the table using AWS Glue:
We’ll set up a crawler in AWS Glue to connect to the data store, determine the schema and create metadata table(s) in the data catalog.
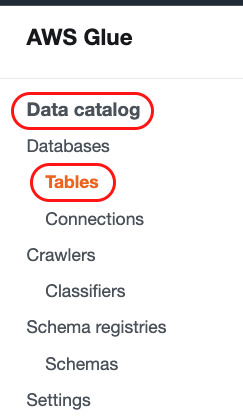
1. Navigate to AWS Glue and from the navigation pane choose Tables from the Data Catalog section:
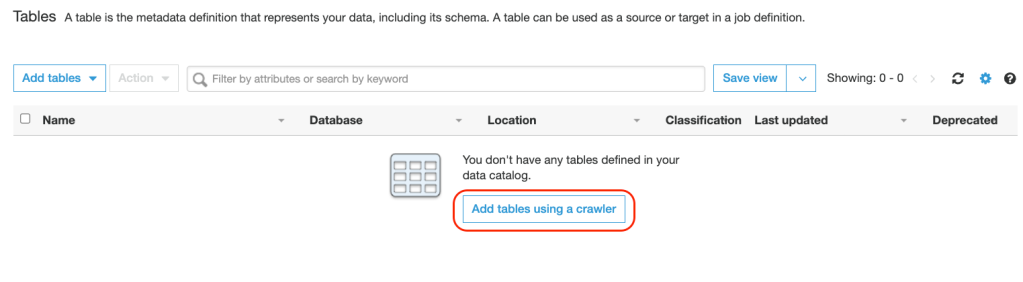
2. Add tables using a crawler and this will create metadata tables in the data catalog:
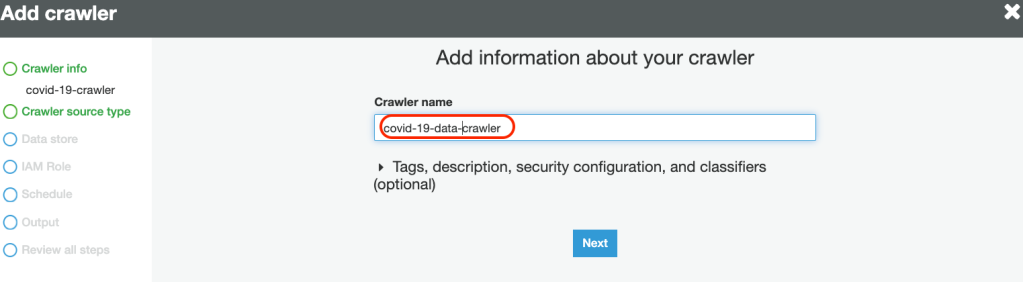
3. Provide a Crawler Name:
4. Specify the Source type as data stores:
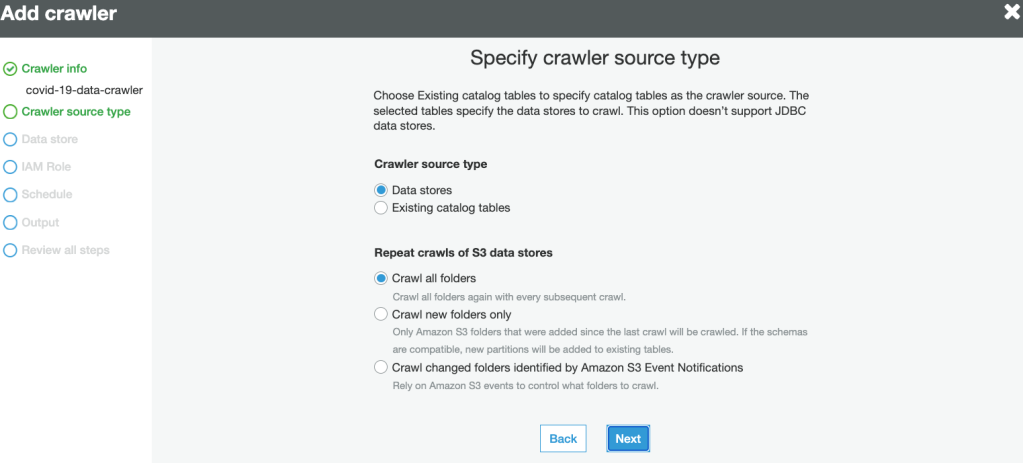
5. Specify the data source path to crawl data:
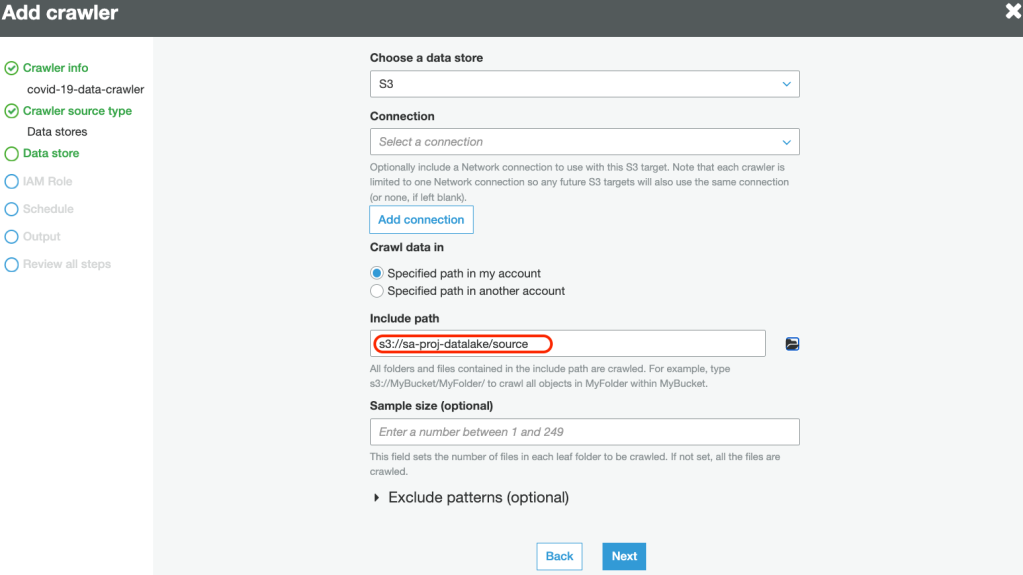
6. Create a new service-linked role with necessary permissions to crawl the data source:
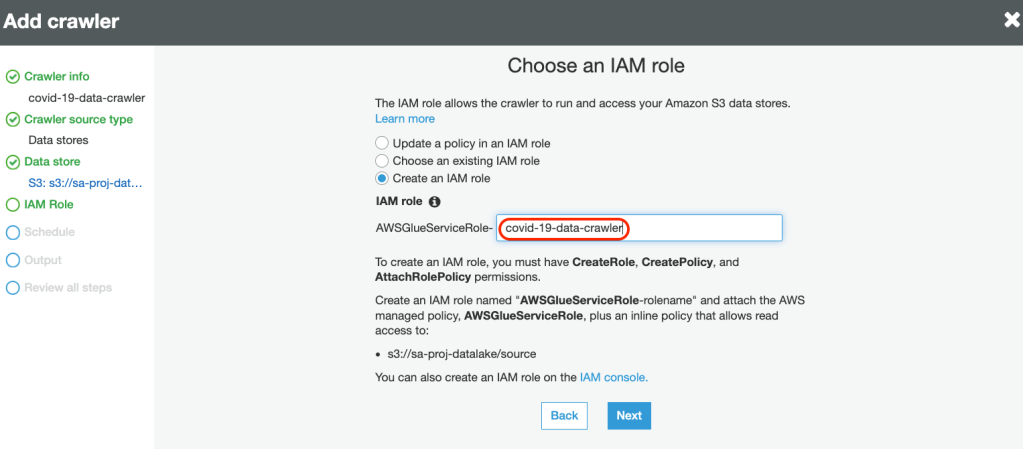
7. Define the Frequency for the crawler to run:
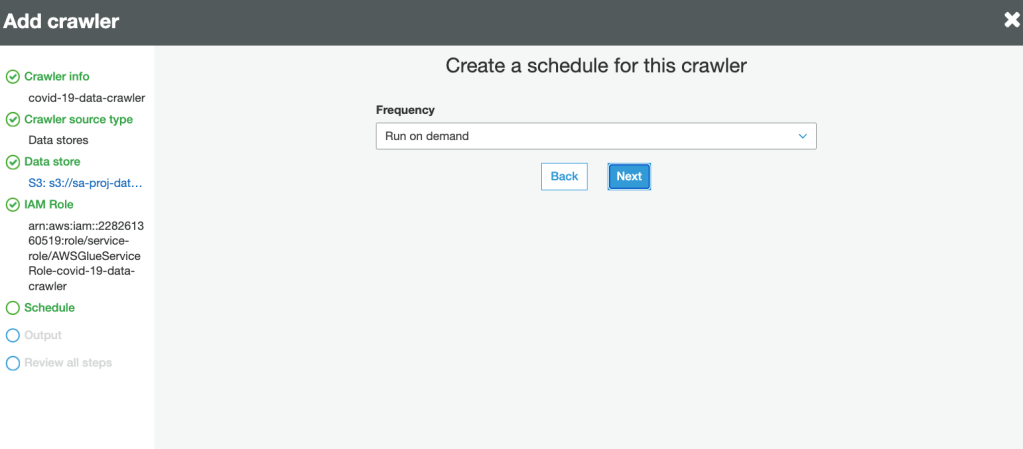
8. Select the database for crawler output. This is the same database created in Lake Formation earlier:
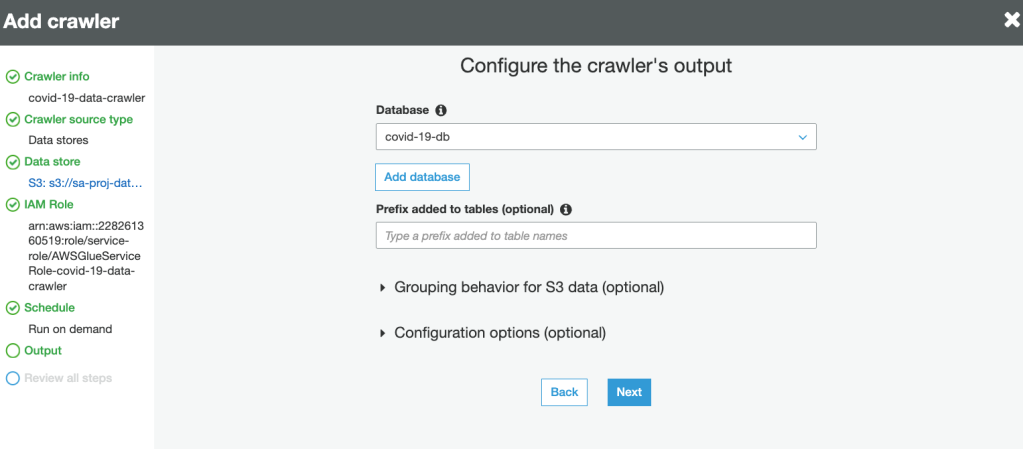
9. Review and create the crawler.
10. Run the crawler:
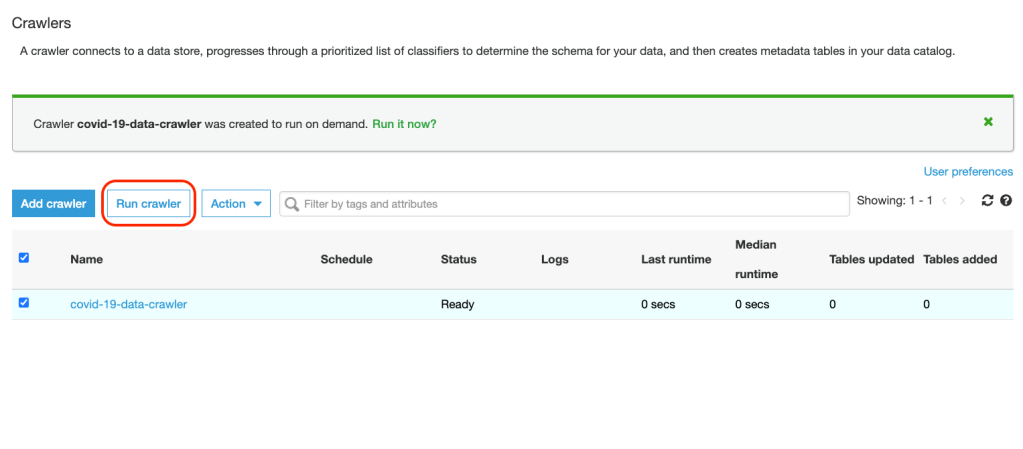
11. Wait for the Tables added column (as shown below) to change to 1 and that would signal the completion of the crawler task and table schema being updated in the catalog. Any tables updated or added by Crawler in the catalog are represented by these columns in the console:

12. Navigate back to Lake Formation and Data Catalog > Tables. The table should be been added by the crawler and its schema must also be populated:
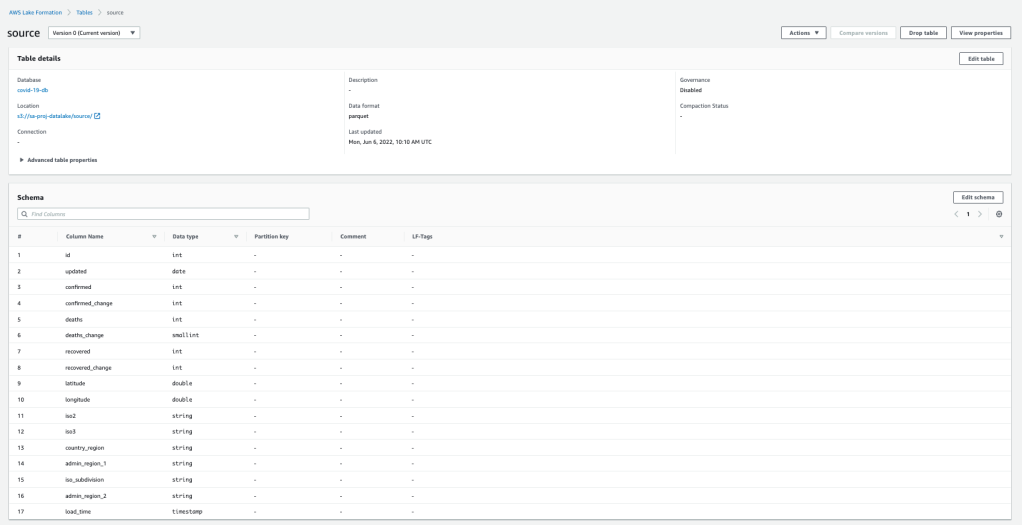
Note: The name of the table is selected by the catalog table naming algorithm and you can’t change it later in the console. You can manually add tables if you need to manage names for tables in the console. To do this, when you define a crawler, instead of specifying one or more data stores as the source of a crawl, you specify one or more existing data catalog tables. The crawler then crawls the data stores specified by the catalog tables. In this case, no new tables are created; instead, your manually created tables are updated.
4. Query the data using Athena
1. Navigate to AWS Athena and go to settings and update the query result location path for S3 as shown below:

2. Select the database and run the query view results of the table:
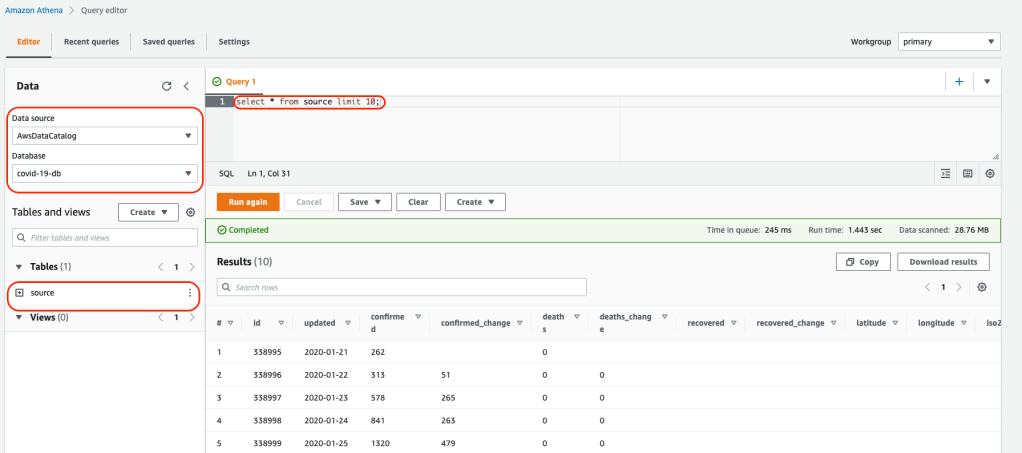
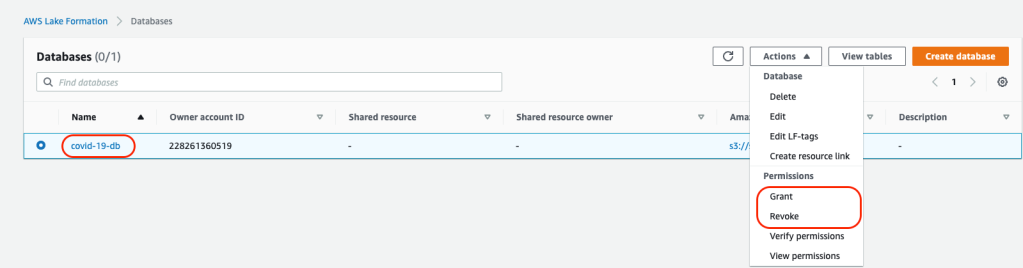
Manage permissions to data
Database Level Permissions: You can grant or revoke permissions to IAM users or roles to databases in Lake Formation using the console:
New users, roles, external users, or active directory users can be added and database permissions can be granted to the level of access needed to the database. See the below image for reference:
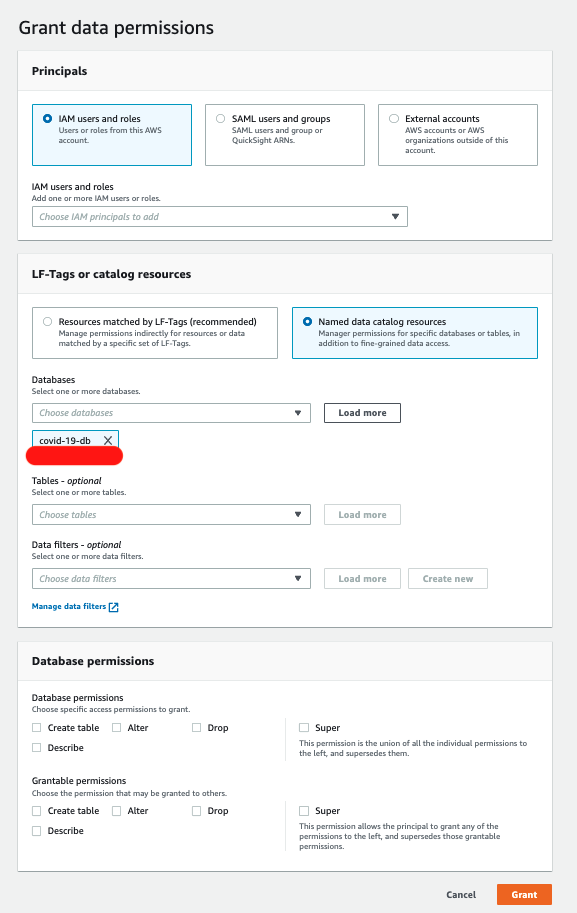
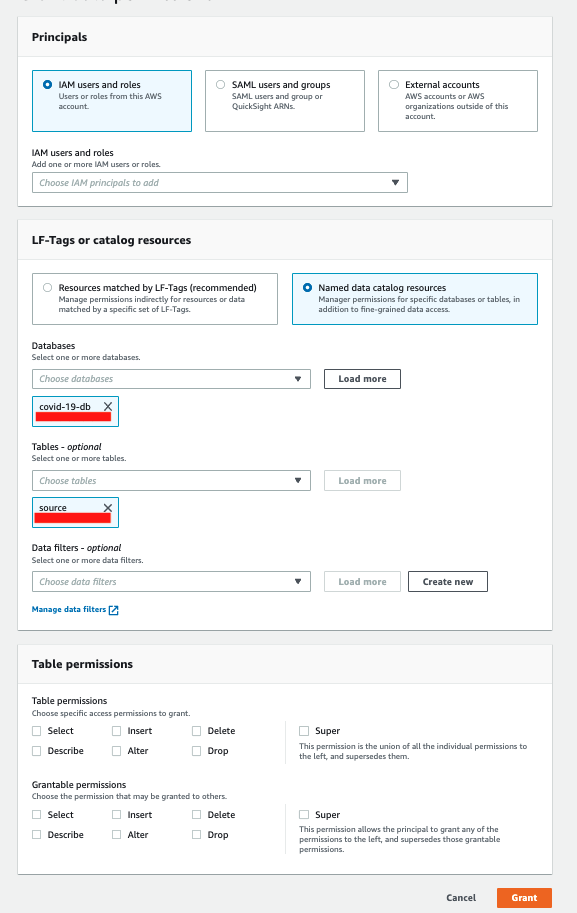
Table Level Permissions: You can grant or revoke permissions to IAM users to tables using the console. Table level permissions can be granular level and you can define select\insert\delete access to the table. See the below image for reference:
Summary
We have successfully set up a data lake, database and data catalog using Lake Formation. Lake Formation also allows us to manage access to data lake resources at the database and at the table level which helps manage permissions for data lake resources. Overall, Lake Formation simplifies the process of setting up data lakes in AWS.
Data Analytics Consulting Services
Ready to make smarter, data-driven decisions?