 In today's data-driven world, businesses and individuals rely on cloud services to store, share, and manage their information. Integrating advanced technologies, like natural language processing (NLP) models, into these services has transformed how we interact with data.
In today's data-driven world, businesses and individuals rely on cloud services to store, share, and manage their information. Integrating advanced technologies, like natural language processing (NLP) models, into these services has transformed how we interact with data.
Two such services, "Azure OpenAI Service" and "Azure Cognitive Search," have joined forces to usher in a new era of personalized AI-driven experiences. In this blog post, we'll explore why this integration is essential, delve into the concept of embedding vectors from documents, and distinguish between regular keyword search and semantic search. Finally, we'll leave you with a step-by-step demo of configuring this powerful scenario.
Integrating Search with AI
In the age of information overload, personalization is the key to efficient data handling. Azure OpenAI, hosting the robust ChatGPT model, provides the perfect interface for users to interact with their data, making it more accessible and actionable.
To complement this capability, we have Cognitive Search. It does this by indexing and organizing users' data from cloud storage for rich search experiences. To take it to the next level, it can now leverage this data as context for Azure OpenAI, enabling the AI model to generate highly relevant and personalized responses.
The integration empowers users to extract insights, generate content, and make informed decisions by fusing the power of language models with the richness of their own data.
Creating Embedding Vectors from Documents
Embedding vectors are numerical representations of words or documents that enable multiple different types of algorithms or computations on text (https://en.wikipedia.org/wiki/Word_embedding). These vectors capture semantic meaning, allowing machines to understand the relationships between words and documents.
Cognitive Search uses an embedding model to convert text documents into embedding vectors. This process transforms plain text into mathematical representations, making it easier to compare and analyze documents based on their content. So, the search can measure the distance between documents as well as measure which documents are better fit to answer a particular question.
With document embeddings, users can explore their data in new ways, from finding similar documents to detecting trends and anomalies. This technology forms the foundation for both semantic and keyword-based searches.
The traditional keyword search method relies on matching specific words or phrases within documents. While efficient, it might miss documents that use synonyms or related terms. Cognitive Search's keyword search capability ensures precise matches but might not capture the full context.
Semantic search, on the other hand, takes advantage of document embeddings to understand the context and meaning behind words. It can find documents related to a query even if they don't contain the exact keywords. This enables a more comprehensive and accurate retrieval of information.
The cool thing here is that both Vector-only, vector plus semantic search as well as vector plus simple search are available, so you can use the method that provides the best results for your use case.
This approach is also much more efficient than fine-tuning a massive model like GPT to achieve something similar.
Fine-tuning vs. External Context
If you are familiar with LLMs, you might have heard of the concept of fine-tuning. Fine-tuning is when an LLM model is trained on a specific body of knowledge or sub-task that was not part of its original training data. This can allow the model to exhibit deeper knowledge or new behavior but it comes at a high compute cost since re-training is necessary. Overfitting is also a common issue with fine-tuning, where the model is so focused on the specific re-training area that it loses a large part of its general knowledge.
The “Bring your own data” approach in Azure OpenAI is not fine-tuning. It is bringing external context information to the LLM model as part of the process of answering a message. The benefit of this approach is that you can immediately get the benefits of the new data without having to go through a training process, and you can integrate new data sources very easily. The downside is that you are still working with the general model behind the scenes, which might not be as detailed or exhibit the understanding of this specific data that you would like.
In general, it makes sense to start by trying out the external context approach first since it is faster and less resource-consuming to implement. Ultimately, the choice between doing a full fine-tuning process or just feeding external context to the LLM will depend on your use case for the technology and whether the results meet your expectations.
Demo: Configuring the Integration
I want to show in this post the current experience of using your own data with an LLM model using the Azure AI Studio.
First, you will notice the option of “Bring your own data” as soon as you enter the Azure AI Studio portal. You will also notice that right now, this capability is in preview, so it’s all expected to change and be adjusted as Microsoft makes this generally available.
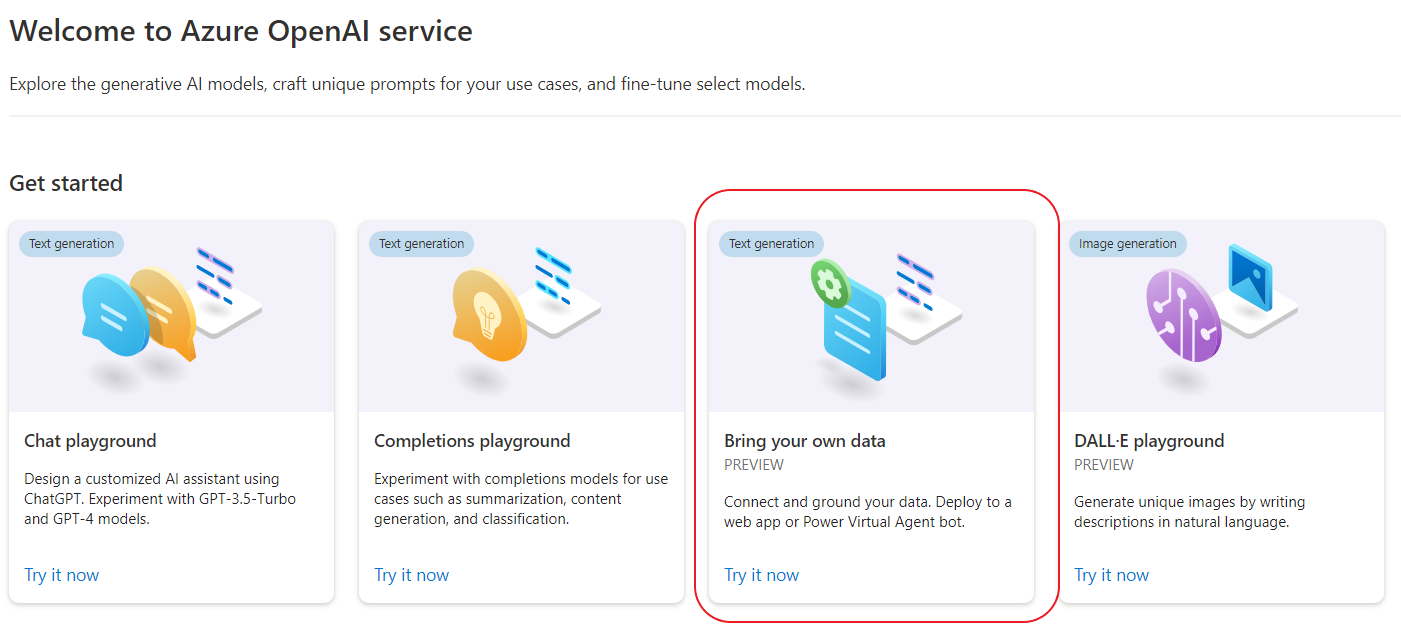
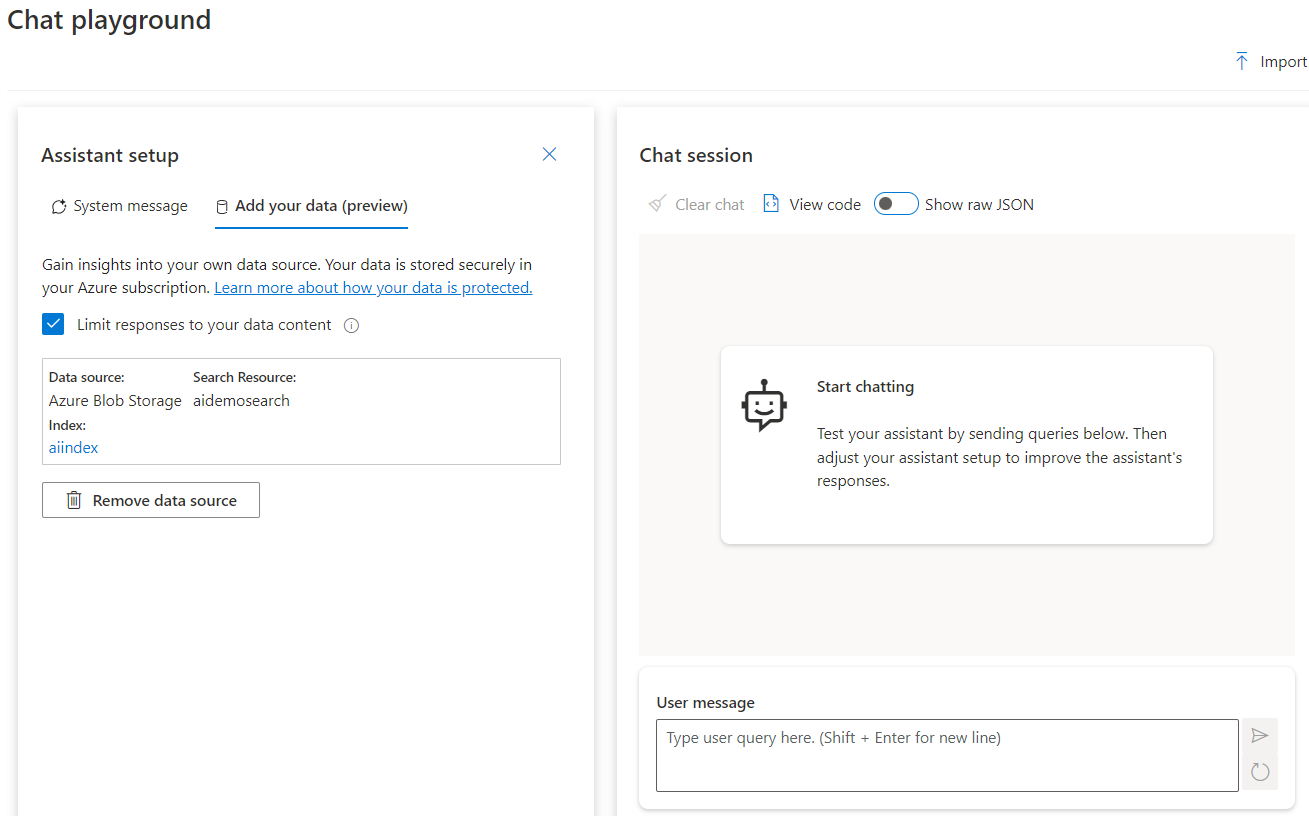
The first step is to provide the data source. Currently, the options are either a Cognitive Search index, an Azure Blob Storage container, or to upload files manually through the portal.
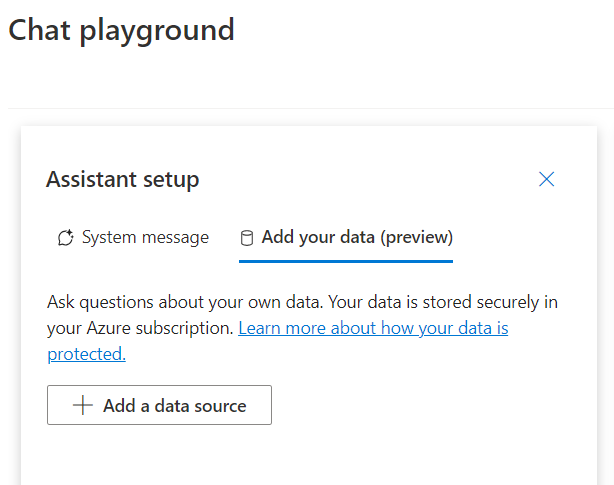
In the image below, you can see the information that is required to make this work. In this scenario, I’m using my own storage account, the service will require a Cognitive Search service to host the index, and if you want to generate vector embeddings, then you need a text embedding model, too.
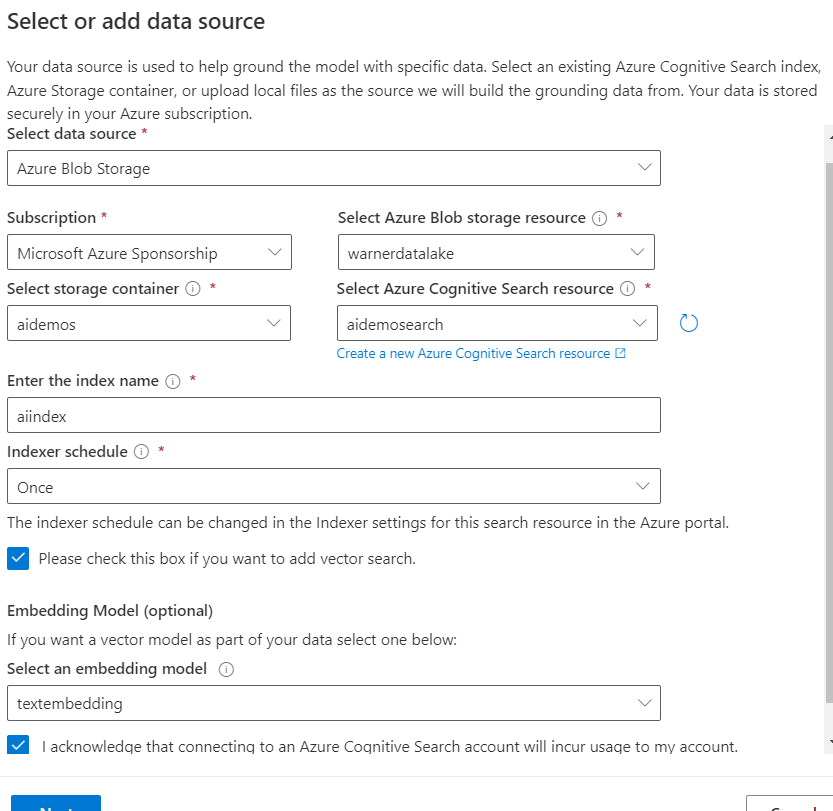
If you do decide to generate vectors, then you have the options of just vector search, vector plus semantic search, and vector plus simple keyword search. The differences between these methods I already covered previously in this post.
Once you have saved the configuration, the service will kick in and create your Cognitive Search index to use with the LLM. You can, of course, access this LLM with the API if you are developing a real application, however, for testing purposes, you can interact right away in a chat session on the web portal.
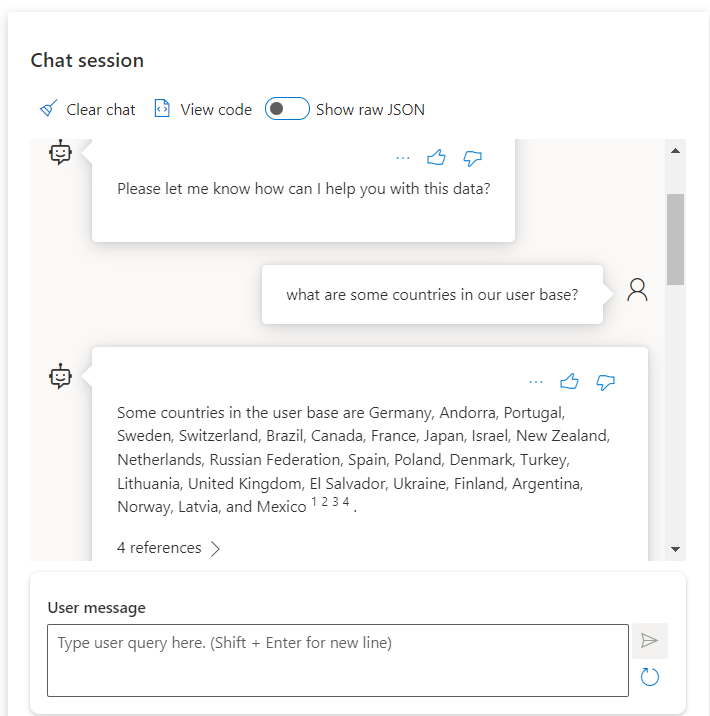
You can see from the screenshot that when I ask a question to the LLM, it gives me an answer, and it even includes the references it has used to generate it.
This portal process is very nice for testing and experimenting and can get someone up and running very quickly. For a true production scenario, we would be looking at a fully automated deployment of all these services and API testing routines with some pre-made interactions with the LLM to ensure that the accuracy is high and the rate of misses or hallucinations is low.
Conclusion
In conclusion, the integration of Azure OpenAI service and Cognitive Search represents a significant leap forward in the world of personalized AI. By harnessing the power of embedding vectors and offering both semantic and keyword-based search capabilities, this integration promises to revolutionize the way we interact with our data and opens the door to all kinds of soon-to-exist advanced user text and chat capabilities.
Share this
Share this

Architecting and Building Production-Grade GenAI Systems - Part 4: Running Operations & User Experience
Increase your data visualization/reporting velocity and performance with proper semantic layers
