Here we go again
Hello, and welcome to this second part of my “Replicating MySQL to Snowflake” series. If you landed here from a web search and missed part one, you can take a look here: part one.
What’s up?
In this second part, I’ll be demonstrating how to ingest data from Kafka into Snowflake using the Snowflake Connector for Kafka.
In part one I showed the diagram for this architecture and how to implement the first half of it.

A reminder on the environment:
- OS: Ubuntu 20.04.2 LTS
- MySQL: Ver 8.0.24 for Linux on x86_64 (MySQL Community Server—GPL)
- ZooKeeper: Apache ZooKeeper, version 3.7.0 2021-03-17 09:46 UTC
- Kafka: 2.8.0
- Scala (included with Kafka): 2.8.0
- Debezium: 2.13 final
- Snowflake Kafka connector (OSS version): 1.5.2 (Maven)
- Snowflake: Enterprise edition (AWS)
This time I’ll be showing the second piece of the puzzle which includes installing and configuring the Snowflake Connector for Kafka and the creation of the Snowflake pieces to ingest the data.
Snowflake target database
For this POC (proof of concept), I used my AWS-hosted trial account that includes one month of access and 400USD in credits. I’ve chosen the Enterprise Edition, but a Standard Edition should be good enough for a similar POC.
I created a dedicated database and schema along with a warehouse. This allows me to easily clean up once I’m done. These come with a newly created role and user dedicated solely for data ingestion purposes.
Having dedicated resources for particular activities is a best practice not only for Snowflake but also for any other database you may be working with. It makes things a lot easier to maintain and audit.
I followed the instructions provided by Snowflake to determine the bare minimum grants this new role requires. As you probably know, this is another best practice.
And here’s the script:
use role sysadmin;
create warehouse if not exists wh_ingest warehouse_size = xsmall;
create database if not exists mysql_ingest;
create schema if not exists mysql_ingest.landing;
use role securityadmin;
create role if not exists r_mysql_rep;
grant all on database mysql_ingest to role r_mysql_rep;
grant all on schema mysql_ingest.landing to role r_mysql_rep;
grant all on warehouse wh_ingest to role r_mysql_rep;
create user if not exists mysql_rep identified by 'XXXXXXXXXXXXXXXXX';
grant role r_mysql_rep to user mysql_rep;
grant role r_mysql_rep to role accountadmin;
grant role r_mysql_rep to role sysadmin;
alter user mysql_rep set DEFAULT_WAREHOUSE=wh_ingest;
alter user mysql_rep set DEFAULT_NAMESPACE=mysql_ingest.landing;
alter user mysql_rep set default_role=r_mysql_rep;
That’s it—nothing else is required.
You’ll notice that I haven’t created any tables. While there’s an option to point the connector to write into an existing table I kept to my simplicity motto for this POC and let the connector create the tables for me.
I’ll review the landing table structure later on.
Installing the Snowflake Connector for Kafka
I followed the instructions provided in the Snowflake documentation.
The connector requires Kafka and a JDK (Java Development Kit)—Standard Edition is good enough. These two elements are already installed for the CDC (change data capture) part of the process (see part one of the series) so I won’t install them again.
This POC will fully run on a single virtual machine but a real production scenario may require a different configuration to deal with the higher amount of data to process.
The connector itself is just a JAR (Java archive) file available in the Maven repository: https://mvnrepository.com/artifact/com.snowflake/snowflake-kafka-connector.
Simply download both the JAR and its corresponding MD5 files:
jose@localhost:~$ wget https://repo1.maven.org/maven2/com/snowflake/snowflake-kafka-connector/1.5.2/snowflake-kafka-connector-1.5.2.jar jose@localhost:~$ wget https://repo1.maven.org/maven2/com/snowflake/snowflake-kafka-connector/1.5.2/snowflake-kafka-connector-1.5.2.jar.md5
Verify that the MD5 sum of the downloaded file matches with the reported MD5 sum stored in the Maven repository.
I’ll be using an encrypted private key for authentication, so I need the Bouncy Castle plugin, available in Maven as well.
jose@localhost:~$ wget https://repo1.maven.org/maven2/org/bouncycastle/bc-fips/1.0.1/bc-fips-1.0.1.jar jose@localhost:~$ wget https://repo1.maven.org/maven2/org/bouncycastle/bc-fips/1.0.1/bc-fips-1.0.1.jar.md5 jose@localhost:~$ wget https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-fips/1.0.3/bcpkix-fips-1.0.3.jar jose@localhost:~$ wget https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-fips/1.0.3/bcpkix-fips-1.0.3.jar.md5
Again, don’t forget to check the MD5 sum values. This is your data potentially going out into the wild, wild Internet and you want the maximum protection possible, which starts with installing untainted software.
Note: Debezium generates JSON (JavaScript Object Notation) data in the Kafka topic so I’m skipping everything Avro-related in the documentation.
All these files must exist in the <kafka_dir>/libs folder so make sure you copy them into there.
The following is from the documentation and it’s important for a production system with a multinode Kafka cluster: “The Kafka Connect framework broadcasts the configuration settings for the Kafka connector from the master node to worker nodes. The configuration settings include sensitive information (specifically, the Snowflake username and private key). Make sure to secure the communication channel between Kafka Connect nodes. For instructions, see the documentation for your Apache Kafka software.”
The connector uses key pair authentication to connect to Snowflake so I’m going to need a 2048-bit (minimum) RSA key pair.
I created an encrypted private key file with the following command:
jose@localhost:~$ openssl genrsa 2048 | openssl pkcs8 -topk8 -v2 aes256 -inform PEM -out rsa_key.p8 Generating RSA private key, 2048 bit long modulus (2 primes) .............................................................................+++++ ......................+++++ e is 65537 (0x010001) Enter Encryption Password: Verifying - Enter Encryption Password:
Remove the header, footer and line breaks from the key to use it in the configuration file (snowflake-connector-animals.properties):
jose@localhost:~$ grep -v PRIVATE rsa_key.p8 | sed ':a;N;$!ba;s/\n/ /g'
Generate the public key out of the private one with the following command:
jose@localhost:~$ openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub Enter pass phrase for rsa_key.p8: writing RSA key
As before, trim the public key file to use it to enable our Snowflake user to connect using a private key pair like so:
jose@localhost:~$ grep -v PUBLIC rsa_key.pub | sed ':a;N;$!ba;s/\n//g'
Connect to your Snowflake database and execute the following SQL using the result of the previous command:
alter user mysql_rep set rsa_public_key='---REDACTED---'
This is a POC but these files still grant access to a live Snowflake account so make sure you secure them with proper permissions—typically 600 in Linux—and in a separate folder. Especially if you use Git or similar, don’t include these files in the repository. The Snowflake documentation suggests the use of an externalized secret store like AWS Key Management Service (KMS), Microsoft Azure Key Vault or HashiCorp Vault, which sounds like a very good idea for a production environment, if you ask me.
This is how the user looks in Snowflake:
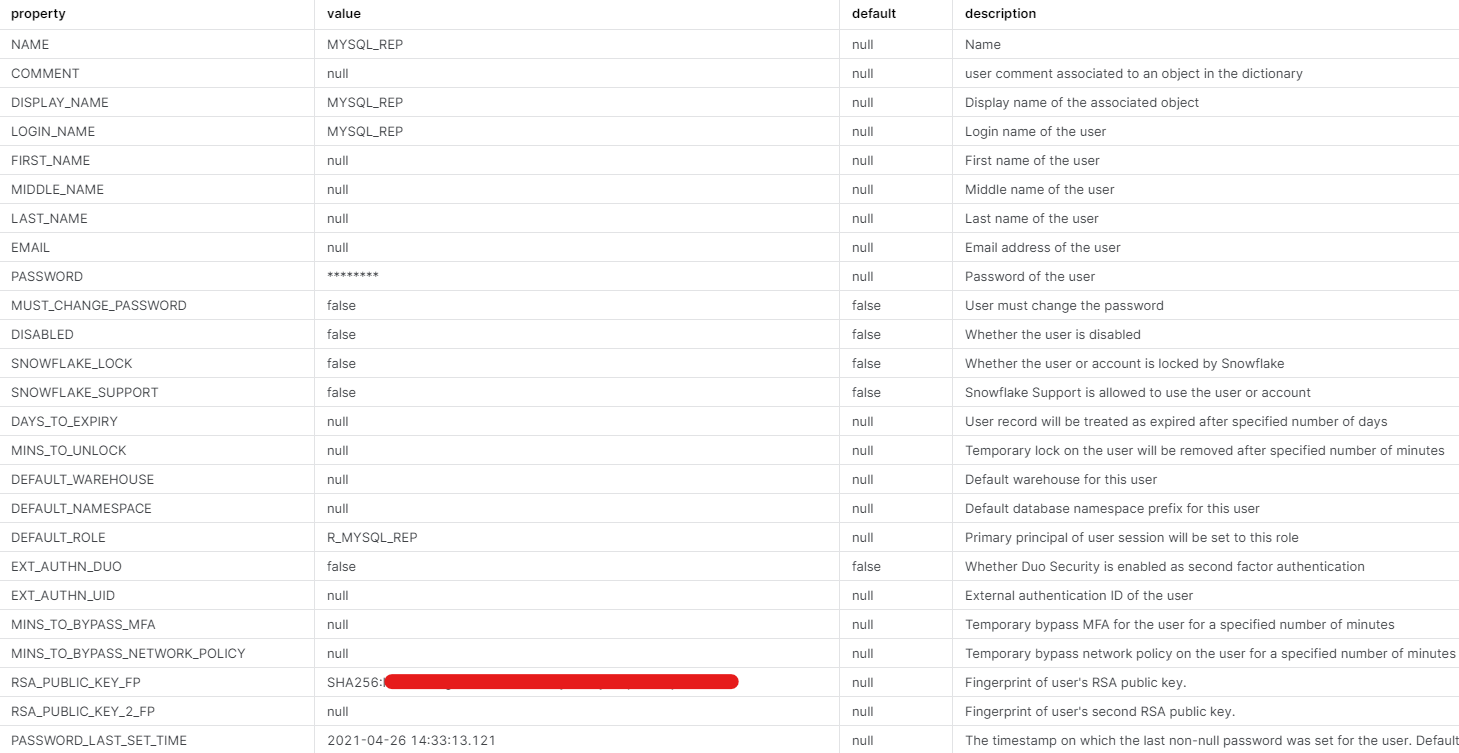
show user command results
Connector configuration
A connector configuration file specifies the source tables and corresponding Kafka topics. These tables must reside in the same database and schema in the source system. So, I created a single file for my single replicated table.
The file is stored in the Kafka config directory as snowflake-connector-animals.properties.
name=mysql_animals connector.class=com.snowflake.kafka.connector.SnowflakeSinkConnector tasks.max=2 topics=snowflake_source.snowflake_source.animals buffer.count.records=10000 buffer.flush.time=60 buffer.size.bytes=5000000 snowflake.url.name=https://XXXXXX.ca-central-1.snowflakecomputing.com snowflake.user.name=mysql_rep snowflake.private.key=---REDACTED--- snowflake.private.key.passphrase=---REDACTED--- snowflake.database.name=mysql_ingest snowflake.schema.name=landing key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=com.snowflake.kafka.connector.records.SnowflakeJsonConverter
Warning: Although the documentation clearly states that the HTTPS:// and port number are optional in the snowflake.url.name parameter, this doesn’t seem to be the case. I learned this the hard way after a long hour trying to figure out why my configuration was wrong. So, use the full account URL in the configuration file.
There’s also another caveat with Snowflake account URLs. Depending on the cloud provider you’ve chosen, it may or may not include a cloud “identifier” in the url. For example the trial account URL I’m using for this POC includes “aws” as it is in my browser.
https://XXXXX.ca-central-1.aws.snowflakecomputing.com
This URL returns an error when I remove the “aws” part and try to access my account with it. But—and this is a big but—the URL I have to use to get the connector to work is the one without that piece:
https://XXXXX.ca-central-1.snowflakecomputing.com:443
Yes, exactly, it doesn’t include the “aws” portion. In a different POC I was using a GCP-hosted account and I hit the issue the other way round. My program wouldn’t connect unless I added the “gcp” piece to the URL.
This was quite confusing and a source of long troubleshooting hours for initial setups, at least for me.
For future reference, if you find this error message in the Kafka Connector, just start fiddling with the URL until you make it right. Sorry, I can’t be of more help than that.
Caused by: org.apache.kafka.connect.runtime.rest.errors.BadRequestException: Connector configuration is invalid and contains the following 3 error(s): snowflake.url.name: Cannot connect to Snowflake snowflake.user.name: Cannot connect to Snowflake snowflake.private.key: Cannot connect to Snowflake
| DISCLAIMER: While the issue above was present during my testing, at the moment of finishing this post it was no longer present and the correct URL is the one including the “aws” part. Snowflake deploys new versions every Friday so it may be the case that they changed something that has now made this behavior consistent. I decided to leave the information in the post in case a similar issue arose somewhere else. |
While I’m using a single Kafka installation for both the Debezium (CDC) and the Snowflake connectors I need different configuration files to avoid port collisions.
So I created a standalone connector configuration file connect-standalone-write.properties as a copy of connect-standalone.properties adding a custom rest.port of 8084. This isn’t a port we’ll be using in this POC but I had to change it anyway.
jose@localhost:~$ grep -v ^# ./kafka_2.13-2.8.0/config/connect-standalone-write.properties bootstrap.servers=localhost:9092 rest.port=8084 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.file.filename=/tmp/connect_write.offsets offset.flush.interval.ms=10000 plugin.path=/Pythian/Pythian-internal/SnowFlake_dev/MySQL-SF-replication/kafka-plugins topic.creation.enable=true
As I explained in part one, all the connectors brought up in a single Kafka deployment will share the same log file, making it very difficult to troubleshoot any issues.
To avoid this I use the following command to direct the collector output to a log file defined by me:
jose@localhost:~$ nohup ./kafka_2.13-2.8.0/bin/connect-standalone.sh ./kafka_2.13-2.8.0/config/connect-standalone-write.properties ./kafka_2.13-2.8.0/config/snowflake-connector-animals.properties > snowflake_connector_`date "+%F_%H-%M"`.log 2>&1 &
And this is the final output expected:
[2021-04-28 13:51:07,698] INFO Started o.e.j.s.ServletContextHandler@30ec7d21{/,null,AVAILABLE} (org.eclipse.jetty.server.handler.ContextHandler:916)
[2021-04-28 13:51:07,699] INFO REST resources initialized; server is started and ready to handle requests (org.apache.kafka.connect.runtime.rest.RestServer:319)
[2021-04-28 13:51:07,699] INFO Kafka Connect started (org.apache.kafka.connect.runtime.Connect:57)
Showing off (AKA testing)
After all this is set up it’s time to demonstrate how the end-to-end replication works.
In part one I showed what a Kafka message looks like when the CDC starts up for the first time and Debezium collects a snapshot of the tables to be replicated.
Beware of this behavior in heavily used production systems as the overall performance of the system may be impacted.
I have the following list of commands to start the replication end to end. I don’t call this a script because it can’t be executed as-is to start the whole system due to the time it takes for Kafka to be up and running. So, if you run it and hit some weird error messages, just give Kafka a few minutes to finish starting up, verify that it is up and running then start the collectors.
#start replication pieces in order # Start zookeeper sudo ./apache-zookeeper-3.7.0-bin/bin/zkServer.sh start # Test it is up and running # apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 127.0.0.1:2181 # Start Kafka broker ./kafka_2.13-2.8.0/bin/kafka-server-start.sh -daemon ./kafka_2.13-2.8.0/config/server.properties # List topics as validation # kafka_2.13-2.8.0/bin/kafka-topics.sh --list --zookeeper localhost:2181 # Start Debezium MySQL connector - Not using the -daemon option to get different log files. nohup ./kafka_2.13-2.8.0/bin/connect-standalone.sh ./kafka_2.13-2.8.0/config/connect-standalone.properties ./kafka_2.13-2.8.0/config/mysql-debezium.properties > debezium_connector_`date "+%F_%H-%M"`.log 2>&1 & # Start Snowflake Kafka connector nohup ./kafka_2.13-2.8.0/bin/connect-standalone.sh ./kafka_2.13-2.8.0/config/connect-standalone-write.properties ./kafka_2.13-2.8.0/config/snowflake-connector-animals.properties > snowflake_connector_`date "+%F_%H-%M"`.log 2>&1 & # View Kafka topic contents # ./kafka_2.13-2.8.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic snowflake_source.snowflake_source.animals
Once everything’s running, we can see the following messages in the Debezium collector log file:
[2021-05-03 10:43:33,423] INFO WorkerSourceTask{id=mysql-connector-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:487)
They basically say that there’s no work to be done.
There will be references to the initial snapshot being made if a new table has been added to the replication.
In the Snowflake Connector we can see how the new connector is created, along with the pipes, stages and landing tables corresponding to each of the source tables:
(...) [2021-05-03 10:02:07,225] INFO Finished creating connector mysql_animals (org.apache.kafka.connect.runtime.Worker:310) (...) [2021-05-03 10:02:09,098] INFO [SF_KAFKA_CONNECTOR] initialized the pipe connector for pipe mysql_ingest.landing.SNOWFLAKE_KAFKA_CONNECTOR_mysql_animals_PIPE_snowflake_source_snowflake_source_puppies_741515570_0 (com.snowflake.kafka.conne [2021-05-03 10:02:09,100] INFO (...) [2021-05-03 10:02:10,599] INFO [SF_KAFKA_CONNECTOR] Creating new stage SNOWFLAKE_KAFKA_CONNECTOR_mysql_animals_STAGE_snowflake_source_snowflake_source_puppies_741515570. (com.snowflake.kafka.connector.internal.SnowflakeSinkServiceV1:79) (...) [2021-05-03 10:02:11,915] INFO [SF_KAFKA_CONNECTOR] Creating new table snowflake_source_snowflake_source_animals_106896695. (com.snowflake.kafka.connector.internal.SnowflakeSinkServiceV1:79)
And the actual objects as seen from Snowflake. The funny names are automatically generated by the connector.
mysql_rep#WH_INGEST@MYSQL_INGEST.LANDING>show PIPES;
+-------------------------------+----------------------------------------------------------------------------------------------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+----------------------+---------+-------------+---------+
| created_on | name | database_name | schema_name | definition
| owner | notification_channel | comment | integration | pattern |
|-------------------------------+----------------------------------------------------------------------------------------------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+----------------------+---------+-------------+---------|
| 2021-05-03 01:02:13.943 -0700 | SNOWFLAKE_KAFKA_CONNECTOR_MYSQL_ANIMALS_PIPE_SNOWFLAKE_SOURCE_SNOWFLAKE_SOURCE_ANIMALS_106896695_0 | MYSQL_INGEST | LANDING | copy into snowflake_source_snowflake_source_animals_106896695(RECORD_METADATA, RECORD_CONTENT) from (select $1:meta, $1:content from @SNOWFLAKE_KAFKA_CONNECTOR_mysql_animals_STAGE_snowflake_source_snowflake_source_animals_106896695 t) file_format = (type = 'json') | R_MYSQL_REP | NULL | | NULL | NULL |
+-------------------------------+----------------------------------------------------------------------------------------------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+----------------------+---------+-------------+---------+
1 Row(s) produced. Time Elapsed: 1.037s
mysql_rep#WH_INGEST@MYSQL_INGEST.LANDING>show STAGES;
+-------------------------------+---------------------------------------------------------------------------------------------------+---------------+-------------+-----+-----------------+--------------------+-------------+---------+--------+----------+-------+----------------------+---------------------+
| created_on | name | database_name | schema_name | url | has_credentials | has_encryption_key | owner | comment | region | type | cloud | notification_channel | storage_integration |
|-------------------------------+---------------------------------------------------------------------------------------------------+---------------+-------------+-----+-----------------+--------------------+-------------+---------+--------+----------+-------+----------------------+---------------------|
| 2021-05-03 01:02:13.413 -0700 | SNOWFLAKE_KAFKA_CONNECTOR_MYSQL_ANIMALS_STAGE_SNOWFLAKE_SOURCE_SNOWFLAKE_SOURCE_ANIMALS_106896695 | MYSQL_INGEST | LANDING | | N | N | R_MYSQL_REP | | NULL | INTERNAL | NULL | NULL | NULL |
+-------------------------------+---------------------------------------------------------------------------------------------------+---------------+-------------+-----+-----------------+--------------------+-------------+---------+--------+----------+-------+----------------------+---------------------+
1 Row(s) produced. Time Elapsed: 0.890s
mysql_rep#WH_INGEST@MYSQL_INGEST.LANDING>show TABLES;
+-------------------------------+-----------------------------------------------------+---------------+-------------+-------+---------+------------+------+-------+-------------+----------------+----------------------+-----------------+---------------------+------------------------------+---------------------------+-------------+
| created_on | name | database_name | schema_name | kind | comment | cluster_by | rows | bytes | owner | retention_time | automatic_clustering | change_tracking | search_optimization | search_optimization_progress | search_optimization_bytes | is_external |
|-------------------------------+-----------------------------------------------------+---------------+-------------+-------+---------+------------+------+-------+-------------+----------------+----------------------+-----------------+---------------------+------------------------------+---------------------------+-------------|
| 2021-05-03 01:02:12.769 -0700 | SNOWFLAKE_SOURCE_SNOWFLAKE_SOURCE_ANIMALS_106896695 | MYSQL_INGEST | LANDING | TABLE | | | 10 | 34816 | R_MYSQL_REP | 1 | OFF
| OFF | OFF | NULL | NULL | N |
+-------------------------------+-----------------------------------------------------+---------------+-------------+-------+---------+------------+------+-------+-------------+----------------+----------------------+-----------------+---------------------+------------------------------+---------------------------+-------------+
1 Row(s) produced. Time Elapsed: 1.136s
Now here comes the real thing.
I start with a table with a few rows in it:
jose@localhost:[snowflake_source]> select * from animals;
+----+---------+
| id | name |
+----+---------+
| 1 | dog |
| 2 | cat |
| 3 | penguin |
| 4 | lax |
| 5 | whale |
| 6 | ostrich |
| 7 | newt |
| 8 | snake |
| 9 | frog |
| 10 | dragon |
+----+---------+
10 rows in set (0,00 sec)
jose@localhost:[snowflake_source]> insert into animals (name) values ('lizard');
Query OK, 1 row affected (0,00 sec)
jose@localhost:[snowflake_source]> select * from animals;
+----+---------+
| id | name |
+----+---------+
| 1 | dog |
| 2 | cat |
| 3 | penguin |
| 4 | lax |
| 5 | whale |
| 6 | ostrich |
| 7 | newt |
| 8 | snake |
| 9 | frog |
| 10 | dragon |
| 11 | lizard |
+----+---------+
11 rows in set (0,00 sec)
Which is immediately captured by the MySQL connector as shown in the log:
[2021-05-03 10:58:36,158] INFO 1 records sent during previous 00:57:03.353, last recorded offset: {transaction_id=null, ts_sec=1620032315, file=binlog.000058, pos=235, row=1, server_id=1, event=2} (io.debezium.connector.common.BaseSourceTask:182)
And sent over to Snowflake by the writer:
[2021-05-03 10:58:43,367] INFO Created Insert Request : https://XXXXXX.west-us-2.azure.snowflakecomputing.com:443/v1/data/pipes/mysql_ingest.landing.SNOWFLAKE_KAFKA_CONNECTOR_mysql_animals_PIPE_snowflake_source_snowflake_source_animals_106896695_0/insertFiles?requestId=0f10041c-817c-4cd1-a6ce-bc1ef1b609ec&showSkippedFiles=false (net.snowflake.ingest.connection.RequestBuilder:471)
The Kafka message is JSON and it contains two main parts: SCHEMA and PAYLOAD. Note the PAYLOAD section does not include data in the BEFORE entry. An update will include this information for further processing once in Snowflake.
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "name"
}
],
"optional": true,
"name": "snowflake_source.snowflake_source.animals.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "name"
}
],
"optional": true,
"name": "snowflake_source.snowflake_source.animals.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false"
},
"default": "false",
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "sequence"
},
{
"type": "string",
"optional": true,
"field": "table"
},
{
"type": "int64",
"optional": false,
"field": "server_id"
},
{
"type": "string",
"optional": true,
"field": "gtid"
},
{
"type": "string",
"optional": false,
"field": "file"
},
{
"type": "int64",
"optional": false,
"field": "pos"
},
{
"type": "int32",
"optional": false,
"field": "row"
},
{
"type": "int64",
"optional": true,
"field": "thread"
},
{
"type": "string",
"optional": true,
"field": "query"
}
],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"field": "total_order"
},
{
"type": "int64",
"optional": false,
"field": "data_collection_order"
}
],
"optional": true,
"field": "transaction"
}
],
"optional": false,
"name": "snowflake_source.snowflake_source.animals.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 11,
"name": "lizard"
},
"source": {
"version": "1.5.0.Final",
"connector": "mysql",
"name": "snowflake_source",
"ts_ms": 1620032315000,
"snapshot": "false",
"db": "snowflake_source",
"sequence": null,
"table": "animals",
"server_id": 1,
"gtid": null,
"file": "binlog.000058",
"pos": 395,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1620032315737,
"transaction": null
}
}
These two parts are inserted as two different columns in the target table:
mysql_rep#WH_INGEST@MYSQL_INGEST.LANDING>desc TABLE SNOWFLAKE_SOURCE_SNOWFLAKE_SOURCE_ANIMALS_106896695; +-----------------+---------+--------+-------+---------+-------------+------------+-------+------------+---------+-------------+ | name | type | kind | null? | default | primary key | unique key | check | expression | comment | policy name | |-----------------+---------+--------+-------+---------+-------------+------------+-------+------------+---------+-------------| | RECORD_METADATA | VARIANT | COLUMN | Y | NULL | N | N | NULL | NULL | NULL | NULL | | RECORD_CONTENT | VARIANT | COLUMN | Y | NULL | N | N | NULL | NULL | NULL | NULL | +-----------------+---------+--------+-------+---------+-------------+------------+-------+------------+---------+-------------+ 2 Row(s) produced. Time Elapsed: 1.111s
As you can see, the data type for both columns is VARIANT as expected when inserting JSON data into Snowflake.
This data type requires some fancy SQL to be used to extract relevant information. A very basic query using the FLATTEN function follows:
select f.path,f.value from "MYSQL_INGEST"."LANDING"."SNOWFLAKE_SOURCE_SNOWFLAKE_SOURCE_ANIMALS_106896695" p, lateral flatten(input => p.RECORD_CONTENT:payload, recursive => true) f where f.seq=2
Which returns, in my case, the following information:
| PATH | VALUE |
| after | { “id”: 11, “name”: “lizard” } |
| after.id | 11 |
| after.name | lizard |
| before | null |
| op | r |
| source | { “connector”: “mysql”, “db”: “snowflake_source”, “file”: “binlog.000058”, … |
| source.connector | mysql |
| source.db | snowflake_source |
| source.file | binlog.000058 |
| source.gtid | null |
| source.name | snowflake_source |
| source.pos | 156 |
| source.query | null |
| source.row | 0 |
| source.sequence | null |
| source.server_id | 0 |
| source.snapshot | true |
| source.table | animals |
| source.thread | null |
| source.ts_ms | 1620028850302 |
| source.version | 1.5.0.Final |
| transaction | null |
| ts_ms | 1620028850310 |
And that’s it
Well, not really. I haven’t covered DDL (data definition language) which isn’t currently supported out of the box. Handling DDL isn’t trivial and different approaches have been proposed.
I also haven’t provided any ideas on how to leverage the ingested data, but a very simple way would be to create a pipe triggered on new CDC data arriving into the landing table and populating a slowly changing dimension like a table. Should you need such help don’t hesitate to reach out to our sales team.
Finally, if you read all the way to the end, thank you and don’t forget to comment if you find any issues or something is missing or wrong.
Enjoy!
Share this
Share this
Replicating MySQL to Snowflake with Kafka and Debezium—Part One: Data Extraction
