Share this
by Scott McCormick on May 4, 2021 12:00:00 AM
This post is part two of describing (near) real-time data processing for BigQuery. In this post, I will use Dataform to implement transforms as well as ASSERTS on the data and unit testing of BigQuery code and SQL statements.
Part one of these blog posts is here, and it describes loading data using Google Workflows.
As a reminder:
GCP Workflows
GCP Workflows were developed by Google and are fully integrated into the GCP console. They’re meant to be used to orchestrate and automate Google Cloud and HTTP-based API services with serverless workflows. This means when you’re working with something which is mostly API calls to other services, Workflows is your tool of choice.
Workflows are declarative YAML. So you simply define the process you want to happen, and the workflow will take care of all the underlying effort to implement it.
Dataform
Dataform is a SaaS company that Google purchased and currently all development must still happen on their website. It’s used to develop SQL pipelines to transform data within BigQuery without writing code.
With Dataform, you define the SQL statements you want to run. After that, they handle creating tables, views, ordering and error handling.
For a tutorial on Dataform, see the documentation.
Real-time processing of flat files into BigQuery
We make use of these two tools along with existing GCP infrastructure to develop a pipeline which will immediately ingest a file into BigQuery and do all the translations needed for reporting. In addition, the pipeline will validate the data’s uniqueness and formatting. Finally, I will demonstrate how to perform unit testing of the data.
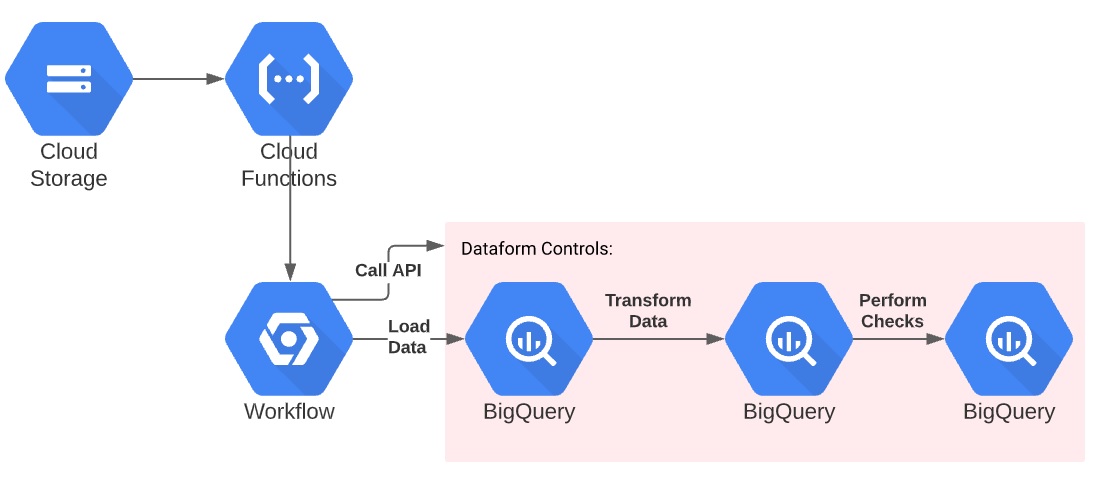
Data load
We’ll be using these three files for transforming the data. You can use the workflow developed in Part One to load them into BigQuery!
After loading these files into BigQuery, you will have three tables in a dataset. You can then run a set of transformations on the tables using Dataform.
Transformations
It’s important to note that all the next steps are being done in the Dataform SaaS UI. They’re owned by Google, but the UI has not yet been integrated with the GCP console.
Create source tables
First, we create the source tables. These are simply pointers to the tables we loaded earlier. Each config block is placed in its own file.
Create a file named bank_location.sqlx:
config {
type: "declaration",
database: "mcc-pythian-presales",
schema: "dataform",
name: "bank_location"
}
Next, create a file named expense_group.sqlx:
config {
type: "declaration",
database: "mcc-pythian-presales",
schema: "dataform",
name: "expense_group"
}
Finally, create a file named transaction.sqlx:
config {
type: "declaration",
database: "mcc-pythian-presales",
schema: "dataform",
name: "transaction"
}
Create transformations
After defining our sources, we next create the transformations that will run. Note that the references to the files define the running order of the transformations.
This first block creates a view which performs some clean up on the “amount” column by removing anything that isn’t a number.
Create a file named cleaned_transaction.sqlx with the following code:
config {
type: "view"
}
WITH AMOUNTS AS
(SELECT ID, EXPENSE_GROUP_ID, BANK_ID, TRANSACTION_DATETIME, IS_DEBIT, REGEXP_EXTRACT_ALL(AMOUNT, "[0-9]+") AS AMOUNT_PIECE FROM ${ref("transaction")})
SELECT ID, EXPENSE_GROUP_ID, BANK_ID, TRANSACTION_DATETIME,
CASE WHEN IS_DEBIT = 0 THEN -1*CAST(ARRAY_TO_STRING(AMOUNT_PIECE, "") AS NUMERIC)
ELSE CAST(ARRAY_TO_STRING(AMOUNT_PIECE, "") AS NUMERIC)
END AS AMOUNT
FROM
AMOUNTS A
Next, we create a table which references the view just created. It’s a simple sum of the balance in each bank, but note the assertions at the top. When the pipeline runs, an error will be thrown if any value is null or if the balance amount is greater/less than 10,000,000,000/10,000,000,000.
Create a file named current_balance.sqlx with the following code:
config {
type: "table",
assertions: {
nonNull: ["BANK_ID", "BALANCE"],
rowConditions: [
'BALANCE BETWEEN -10000000000 AND 10000000000'
]
}
}
SELECT
BANK_ID,
SUM(AMOUNT) BALANCE
FROM
${ref("cleaned_transaction")}
GROUP BY
BANK_ID
Finally, we’ll create a couple of reporting views for our end users to use.
Create a file named bank_geolocations.sqlx with the following code:
config {
type: "view"
}
SELECT
NAME, ADDRESS, dataform.get_geopoint(ADDRESS) GEOLOCATION
FROM
${ref("bank_location")}
And a file name bank_balance:
config {
type: "view"
}
SELECT
bl.NAME,
bl.ADDRESS,
cb.BALANCE
FROM
${ref("bank_location")} bl INNER JOIN
${ref("current_balance")} cb ON bl.id = cb.bank_id
Assertions
At this point, we have a pipeline which will take our source data, perform some basic cleaning, and make it available for reporting. The current_balance table also has some simple assertions which will cause the pipeline to fail if bad data is introduced.
We can also do more complex assertions.
This assertion will check that no bank is listed in the current_balance table more than once.
Create a file named current_balance_upi.sqlx with the following code:
config {
type: "assertion"
}
WITH BASE AS (
SELECT
COUNT(BANK_ID) COUNT_BANK_ID,
FROM ${ref("current_balance")}
GROUP BY BANK_ID
HAVING COUNT(BANK_ID) > 1
)
SELECT * FROM BASE WHERE COUNT_BANK_ID > 1
And this assertion verifies that no expense_group_id in the transaction table isn’t between one and six, or null. If you’re using the sample data, this should fail.
Create a file named current_balance_upi.sqlx with the following code:
config {
type: "assertion"
}
select *
from
${ref("transaction")}
where
cast(EXPENSE_GROUP_ID as numeric) NOT IN (1,2,3,4,5,6) OR
EXPENSE_GROUP_ID IS NULL
Unit testing
Lastly, let’s do some unit testing. You may have noticed that the bank_geolocations view is calling a function name get_geopoint. This unit test will pass in some test values and verify the returning value is what’s expected.
First, create the function in BigQuery. This is just a dummy I faked up.
CREATE OR REPLACE FUNCTION `[PROJECT_ID].dataform.get_geopoint`(p STRING) AS ( (SELECT "1234.3435" as geopoint) );
Next, create the unit test itself.
In the bank_geolocations view definition, we have a reference to “bank_location.” So, in our unit test, we need to define the test values for a row in the bank_location query. Then we define the expected output.
config {
type: "test",
dataset: "bank_geolocations"
}
input "bank_location" {
SELECT "TestBank" as NAME, "TestAddress" as ADDRESS, "TestAddress" as GEOLOCATION
}
SELECT "TestBank" as NAME, "TestAddress" as ADDRESS, "1234.3435" as GEOLOCATION
Validate pipeline
Let’s see what we have! At this point, you should be able to see the following in the Dataform dependency tree. Don’t forget to push your changes to master.

We don’t use expense_group in our pipeline, so it’s lonely. All the rest are tied together automatically using the references in our code.
You can run the pipeline from the Dataform UI, or schedule it to run here also. This will fail on the assertions and is expected, but it’s a nice way to see what will happen.
Run pipeline
Because we want to run this pipeline immediately after the data is loaded by the workflow, we will call it using the Dataform REST API.
It’s a simple API that only needs an API token in the header for authentication. You can generate an API token under your Dataform project settings.
First though, we need to update the GCP workflow to call the Dataform API.
We will be adding this logic to the workflow. You can find the Dataform Project ID in your Dataform URL. It’s a long string of numbers.
- run_transformation_pipeline:
call: http.post
args:
url: "https://api.dataform.co/v1/project/[DATAFORM_PROJECT_ID]/run"
headers:
Authorization: "Bearer [API TOKEN]"
result: transformation_run_id
The end result of the workflow is:
main:
params: [args]
#Parameters:
#
# bucket: GCS Bucket Name (no gs://)
# file: File Name. Can have wildcard
# datasetName: Dataset Name
# tableName: Table Name
#
# {"bucket":"bucket-name","file":"filename.csv","datasetName":"BQDatasetName","tableName":"BQTableName"}
# {"bucket":"staging-ingest","file":"categories.csv","datasetName":"dataform","tableName":"categories"}
steps:
# Only ten variables per assign block
- environment_vars:
# Built-in environment variables.
assign:
# Mostly not used in this code, but here to show the list of what exists
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- project_num: ${sys.get_env("GOOGLE_CLOUD_PROJECT_NUMBER")}
- workflow_location: ${sys.get_env("GOOGLE_CLOUD_LOCATION")}
- workflow_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_ID")}
- workflow_revision_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_REVISION_ID")}
- global_vars:
# Global variables
assign:
- job_id:
- bigquery_vars:
# BigQuery job configuration
assign:
- request_body:
configuration:
load: {
destinationTable: {
datasetId: "${args.datasetName}",
projectId: "${project_id}",
tableId: "${args.tableName}"
},
sourceUris: [
"${ \"gs://\" + args.bucket + \"/\" + args.file}"
],
sourceFormat: "CSV",
autodetect: "true",
nullMarker: "NA",
createDisposition: "CREATE_IF_NEEDED",
writeDisposition: "WRITE_APPEND",
fieldDelimiter: ","
}
- log_config_state:
call: sys.log
args:
text: ${"BigQuery job configuration " + json.encode_to_string(request_body)}
severity: INFO
- load_bigquery_job:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + project_id + "/jobs"}
body:
${request_body}
headers:
Content-Type: "application/json"
auth:
type: OAuth2
result: job_response
- set_job_id:
assign:
- job_id: ${job_response.body.jobReference.jobId}
- monitor_bq_job:
try:
steps:
- get_bq_job_status:
call: http.request
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + project_id + "/jobs/" + job_id + "?location=" + workflow_location}
method: GET
auth:
type: OAuth2
result: bq_job_status
- induce_backoff_retry_if_state_not_done:
switch:
- condition: ${bq_job_status.body.status.state != "DONE"}
raise: ${bq_job_status.body.status.state} # a workaround to pass job_state value rather that a real error
retry:
predicate: ${job_state_predicate}
max_retries: 10
backoff:
initial_delay: 1
max_delay: 60
multiplier: 2
- tag_source_object:
call: http.put
args:
url: "${\"https://storage.googleapis.com/storage/v1/b/\" + args.bucket + \"/o/\" + args.file }"
body:
metadata:
"status": "loaded"
"loadJobId": ${job_id}
headers:
Content-Type: "application/json"
auth:
type: OAuth2
- get_load_results:
steps:
- get_final_job_status:
call: http.request
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + project_id + "/jobs/" + job_id + "?location=" + workflow_location}
method: GET
auth:
type: OAuth2
result: load_response
- log_final_job_state:
call: sys.log
args:
text: ${"BigQuery job final status " + json.encode_to_string(load_response)}
severity: INFO
- raise_error_on_failure:
switch:
- condition: ${("errorResult" in load_response.body.status)}
raise: ${load_response.body.status.errors}
- run_transformation_pipeline:
call: http.post
args:
url: "https://api.dataform.co/v1/project/[DATAFORM_PROJECT_ID]/run"
headers:
Authorization: "Bearer [API TOKEN]"
result: transformation_run_id
- return_result:
return: >
${"Files processed: " + load_response.body.statistics.load.inputFiles +
". Rows inserted: " + load_response.body.statistics.load.outputRows +
". Bad records: " + load_response.body.statistics.load.badRecords
}
job_state_predicate:
params: [job_state]
steps:
- condition_to_retry:
switch:
- condition: ${job_state != "DONE"}
return: True # do retry
- otherwise:
return: False # stop retrying
With this logic, we are now ingesting a file into BigQuery and performing transformations on the data with checks on the data and unit testing. Here’s the final result of the pipeline after running it from the GCP workflow (the assertion failures are expected):
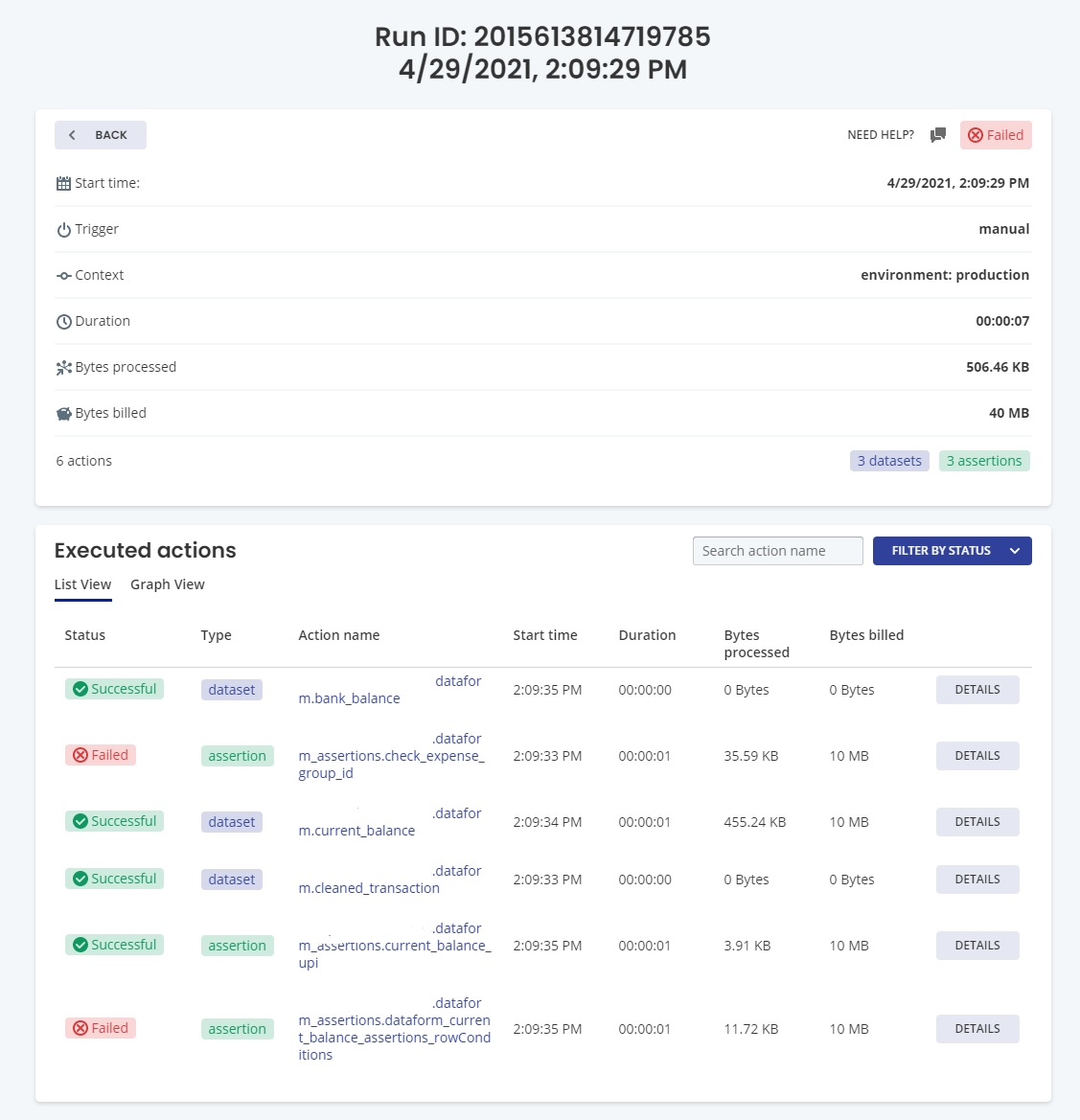
I hope this was helpful. If you have any questions or thoughts, please leave them in the comments.
Click here to read “Near Real-Time Data Processing For BigQuery: Part One.”
No Comments Yet
Let us know what you think