On this page
Share this
Share this
Basho Technologies and PalominoDB Partner to Offer Enhanced Support and Monitoring Services for Riak Installation and Management
![]()
Basho Technologies and PalominoDB Partner to Offer Enhanced Support and Monitoring Services for Riak Installation and Management
Jul 25, 2012 12:00:00 AM
2
min read
Monitoring apache Cassandra metrics with Graphite and Grafana
![]()
Monitoring apache Cassandra metrics with Graphite and Grafana
Jun 30, 2016 12:00:00 AM
8
min read
Cassandra as a time series database
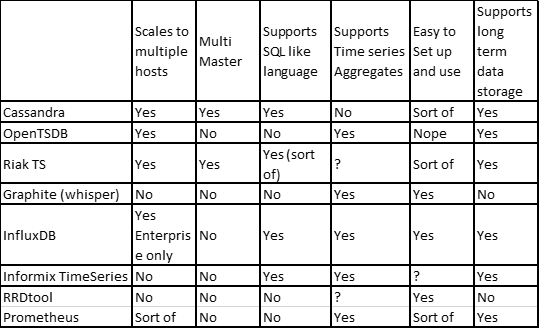
Cassandra as a time series database
Mar 23, 2018 12:00:00 AM
6
min read