With the rise of generative AI, graph databases have become a trendy method to store data. Neo4j offers adjacent-free indexing, and ACID-compliance is the leading name in this technology.
Introduction
In this blog, I will walk through the steps of designing and creating a Neo4j database. First, we will define the scope of the database and plan for some initial use cases. In the second step, we will clean the data and import it into a locally hosted database. We will write Cypher queries to answer common use cases for our databases. Finally, we will discuss refactoring the data to accommodate data growth and additional use cases.
Choosing the data and defining use cases
My favorite sport to follow is American football, and I want to create a database to help me answer trivia questions about teams and players' records in the National Football League(NFL). Using data from the 2023 season, we want to be able to answer questions such as:
- What team did a player play for? What was their role?
- How many non-quarterback players throw a touchdown?
- Who was the player with the most interceptions on the Cowboys?
To help me answer these questions, we use the following CSV files provided by pro-football-reference:
Modelling the database
Before discussing this database model, it would be beneficial to discuss some basic concepts in graph theory, and the mathematical theory behind our database. These concepts are:
- Node: a featureless and indivisible entity representing an individual record. Each node in Neo4j has a label. A node label can be thought of as a noun in use cases. For example, players, coaches, and teams can be considered the node labels in our database.
- Relationship: also known as edges, connects between a start node and an end node. Additionally, a relationship has a type that helps us categorize it and determine how two nodes are related to each other. A relationship's type can be considered the verb in use cases. In our example, "played for" or "coached for" are the relationship types in our graph.
- Property: an optional description that can be provided with both nodes and relationships for additional information. For our use case, players' ages and positions can be considered properties.
Additionally, Neo4j recommends the following steps when it comes to graph database design:
- Understand the domain and define the application's specific use cases (questions).
- Develop the initial graph data model
- Test the use cases against the data model.
So far, we performed the first step in the previous section. Here, we perform the second step by considering our initial data model:

Figure 1: Data Model
In Neo4j, primary key is not strictly enforced, therefore we need a way to prevent data duplication in our graph. The "tmdbId" property will serve this purpose for us when we enforce an uniqueness constraint on this property later on after adding this value to our data. Additionally, here is an example of Neo4j best practice for naming objects:
- Node label: we want to use Camelcase for node labels. In our graph, "Player", "Coach", and "Team" are the node labels.
- Relationship: it is recommended to use UPPERCASE for keywords like our relationships here.
- Property: finally, property is recommended to use camelCase for properties.
Cleaning the data
We will use Python's Pandas package to manipulate our existing data. If we break our process down to our ETL(Extract, Transform, Load) pipeline, Pandas would fall under the transformation process. For our purpose here, we plan to import the data in CSV files into Pandas data frames, clean the data, and then re-write the data back into the original CSV file. To do this, consider our sample Python environment:
import pandas as pd
pd.options.display.max_columns = None
# Write the Python function
def add_tmdbID_column(filename, column):
df = pd.read_csv(filename)
tmdbId = []
for row in df[column]:
tmdbId.append(int.from_bytes(row.encode(), 'little'))
df['player_tmdbId'] = tmdbId
df.to_csv(filename,header=True, index=False)
# Call the function
add_tmdbID_column("./Passing.csv", "Tm")
After running the function above, and the other additional functions in our Python script here, we end up with CSV input files that look something like this:
Tm,W,L,W-L%,PF,PA,PD,MoV,SoS,SRS,OSRS,DSRS,Conf,Division,tmdbId,division_winner,wild_card,tm_abrv
Buffalo Bills,11,6,0.647,451,311,140,8.2,-1.8,6.5,4.1,2.3,AFC,East,4805185,True,False,BUF
Miami Dolphins,11,6,0.647,496,391,105,6.2,-1.8,4.4,7.6,-3.1,AFC,East,5002305,False,True,MIA
New York Jets,7,10,0.412,268,355,-87,-5.1,-0.6,-5.8,-6.7,0.9,AFC,East,4997442,False,False,NYF
New England Patriots,4,13,0.235,236,366,-130,-7.6,-0.2,-7.9,-8.5,0.6,AFC,East,4609346,False,False,NWE
Baltimore Ravens,13,4,0.765,483,280,203,11.9,1.2,13.2,6.7,6.5,AFC,North,5390659,True,False,BAL
You can examine the our full dataset after the modification here.
Importing the nodes
In the previous section, we discussed about the creation of a constraint for "tmdbId" and "tm_abrv" to prevent data duplication and to serve as a pseudo primary key. Here it is important to note that "tmdbId" will not be auto-incremented in Neo4j since we added it from an external program. When adding new data to Neo4j, it is recommended to perform auto-incrementation outside of the database. With that said, the following Cypher statement will do so for our database:
CREATE CONSTRAINT tmdbId IF NOT EXISTS
FOR (x:Player)
REQUIRE x.tmdbId IS UNIQUE
/* expected output:
Added 1 constraint, completed after 185 ms. */
CREATE CONSTRAINT tm_abrv IF NOT EXISTS
FOR (x:Team)
REQUIRE x.tm_abrv IS UNIQUE
/* expected output:
Added 1 constraint, completed after 92 ms. */
After putting in the constraint to prevent node duplication, we can then import the nodes:
LOAD CSV WITH HEADERS
FROM 'https://docs.google.com/spreadsheets/d/1YBumPLEFMfRQ1kvb4mHkGMH9KH2pVdzjiJOkHDgGmtc/export?format=csv' AS row
MERGE (t:Team {tmdbId: toInteger(row.tmdbId)})
SET
t.tmdbId = toInteger(row.tmdbId),
t.team = toString(row.Tm),
t.win = toInteger(row.W),
t.lost = toInteger(row.L),
t.win_lost_percentage = toInteger(row.WLPer),
t.point_scored = toInteger(row.PF),
t.point_allowed = toInteger(row.PA),
t.point_differential = toInteger(row.PD),
t.conference = toString(row.Conf),
t.division = toString(row.Division),
t.tm_abrv = toString(row.tm_abrv),
t.division_winner = toBoolean(row.division_winner),
t.wild_card = toBoolean(row.wild_card)
/* Expected output: Added 32 labels, created 32 nodes, set 416 properties, completed after 553 ms. */
Having the nodes in the database, we will now establish their relationships. Take our importation of the :PLAYED_FOR relationship for example:
LOAD CSV WITH HEADERS
FROM 'https://docs.google.com/spreadsheets/d/1CYiSZqGNtyhesnN4f4rcEmigSdSfyKoyfpOLsBzPjvY/export?format=csv' AS row
MATCH (p:Player {tmdbId: toInteger(row.tmdbId)})
MATCH (t:Team {tm_abrv: toString(row.Tm)})
MERGE (p)-[:PLAYED_FOR]->(t)
/* Expected output: Created 1417 relationships, completed after 845 ms. */
Here we note that these are samples of our Cypher statements, you see the full list of statements here. Additionally, Neo4j allows us to import data from file storage services, therefore all the data provided here can be loaded to your self-hosted database.
Finally, we have the instance model for the players.

Figure 2: :PLAYED_FOR Relationship Instance Model
Troubleshooting the COACHED_FOR relationship
When importing the coach relationship, I noticed a discrepancy where instead of the expected 35 relationships, I only have 34 relationships. To troubleshoot this, I used the following query to find the coach that wasn't assigned to a team:
MATCH (c:Coach)
WHERE NOT (c)-[:COACHED_FOR]->()
Return c.name, c.tmdbId
/* Output: "Robert Saleh": 122399679603027 */
Robert Saleh is the coach for the New York Jets, it looks like I have a misspelling in my "tm_abrv" column. The following query confirms it:
MATCH (t:Team)
WHERE t.team = "New York Jets"
RETURN t.tm_abrv
/* Output: "NYF" */
To remedy this issue, we can use the SET command:
MATCH (t:Team)
WHERE t.team = "New York Jets"
SET t.tm_abrv = "NYJ"
RETURN t.team, t.tm_abrv
/* Output: "New York Jets": "NYJ" */
Now, we need to delete the relationships and re-import them:
MATCH (c:Coach)-[cf:COACHED_FOR]->(t:Team)
DELETE cf
/* Output: Deleted 34 relationships, completed after 6 ms. */
Rerun, the query to import the coaching relationship above, and we have the following model:
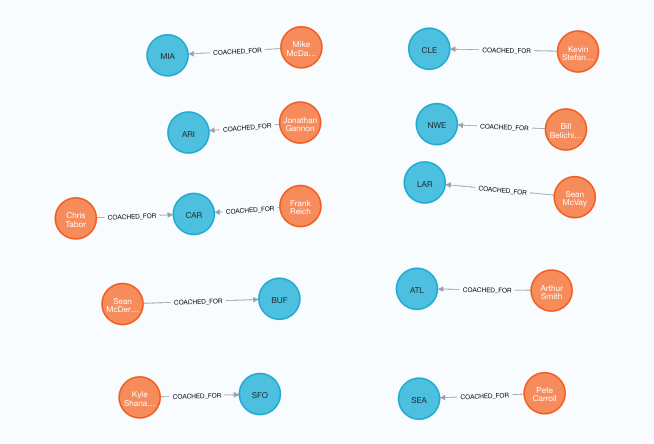
Figure 3: :COACHED_FOR Relationship Instance Model
Testing the Use Cases
Above, we defined a few possible use cases for this database. Let's examine the Cypher query to answer those queries:
1. What team did a player play for? What was their role?
For this query, let's try with the player "Patrick Mahomes" using the following query:
MATCH (p:Player)-[:PLAYED_FOR]->(t:Team)
WHERE p.name = "Patrick Mahomes"
RETURN p.position, t.team
/*Outcome: "QB", "Kansas City Chiefs"
Started streaming 1 records after 10 ms and completed after 17 ms. */
2. How many non-quarterback players throw a touchdown?
The first query is straightforward, but let's try something more complicated. In American football, the quarterback is the one who usually throws the ball, but sometimes teams might draw up trick plays and have a different positional throwing. This query will find all players that are not "QB" and threw for a touchdown:
MATCH (p:Player)-[:PLAYED_FOR]->(t:Team)
WHERE p.passing_touchdowns >= 1 and p.position <> "QB"
RETURN p.name, p.position, p.passing_touchdowns, t.team
/*Outcome: name, position, touchdowns, team
"Devin Singletary" "RB" 1 "Houston Texans"
"Derrick Henry" "RB" 2 "Tennessee Titans"
"Jerick McKinnon" "RB" 1 "Kansas City Chiefs"
"Jakobi Meyers" "WR" 1 "Las Vegas Raiders"
"Keenan Allen" "WR" 1 "Los Angeles Chargers"
Started streaming 5 records after 11 ms and completed after 17 ms. */
3. Who was the player with the most interceptions on the Cowboys?
MATCH (p:Player)-[:PLAYED_FOR]->(t:Team)
WHERE t.team = "Dallas Cowboys" and p.intercepted_reception IS NOT NULL
RETURN p.name, p.intercepted_reception ORDER BY p.intercepted_reception DESC LIMIT 1
/*Outcome: name, interceptions
"DaRon Bland" 9
Started streaming 1 records after 11 ms and completed after 11 ms. */
Planning for Data Growth
Planning ahead for expected data growth is always beneficial when designing a database. We currently only have one year's worth of data, but what if we want to add more years to our database? In that case, we re-design the data model as follows:
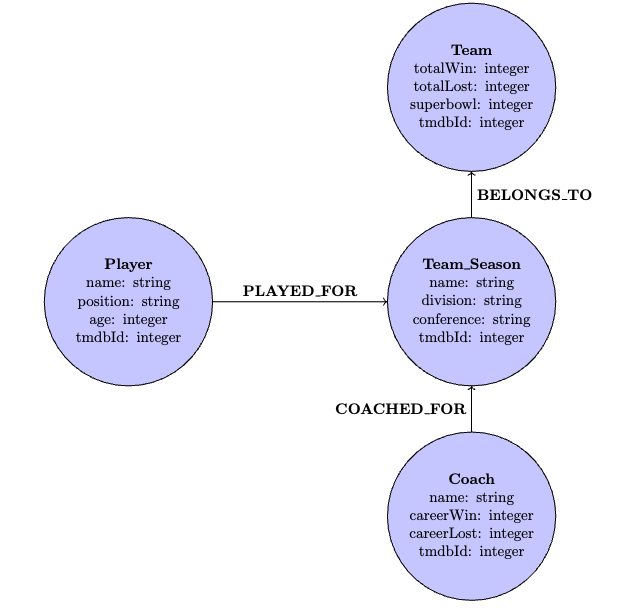
Figure 4: Modified Data Model
Neo4j is optimized for graph traversal, so we want to avoid storing all the years under a team as properties. Instead, it is better to separate yearly data into their own nodes and fetch a team's total records when we need it.
Conclusion
In this blog, we go over the steps in setting up a graph database and how to plan for the growth of a graph database. I was originally intrigued by graph databases due to their elegant queries that allow us to answer questions that would require complex join queries in the relational database model, but with AI dominating the conversation, graph databases have become a hot technology due to their ability to store knowledge graphs to empower LLM by quickly retrieves the information it needs.
References
- Modeling guidelines: https://neo4j.com/docs/getting-started/data-modeling/guide-data-modeling/
- Data source: https://www.pro-football-reference.com/years/2023/
- Encoding tmdbId: https://stackoverflow.com/questions/31701991/string-of-text-to-unique-integer-method/31702461#31702461
Database Consulting Services
Ready to get the database consulting support you need?
Share this
Share this
DUPLICATE from ACTIVE Database Using RMAN, a Step-by-Step Guide
ORA-01156 when adding standy redo log in dataguard configuration
