In the other posts in the series I reviewed four standard handlers provided out of the box. But what if you need more than that? What if you have another platform as a replication target? A good place to start your search is the Oracle Data Integration project on java.net. If you work regularly with ODI or GoldenGate it is one of the sites to save in your bookmarks. On this site you can find software you need, or even join the project and contribute as a developer. All software in the project is distributed under
CDDL license. In this article I am going to test the Oracle GoldenGate Adapter for MongoDB taken from the Oracle Data Integration project. The adapter is supposed to work with Oracle GoldenGate for Big Data, and deliver the same functionality as the standard handlers we have tested before. We already have the source side with extract working on an Oracle 12c database. For those who want to know more, or maybe recall the initial setup, you can read the
first post in the series where the setup details are described. The replication is running from Oracle GoldenGate against on Oracle database to to the GoldenGate for Big Data where we've placed the adapter for MongoDB. The adapter can be downloaded. In the zip file you will find the adapter jar file, source code, and examples for the necessary configuration files. The README on the home page for the adapter will provide some basics about it, and it's not a bad idea to keep it somewhere handy for reference. As a first step I created a directory called "mongo" in my GoldenGate home for Big Data, and unpacked everything there. Later in the excerpts and output the environment variable $OGGBD is used to reference the Oracle GoldenGate Big Data home. [code lang="text"] [oracle@sandbox ~]$ wget https://java.net/projects/oracledi/downloads/download/GoldenGate/Oracle%20GoldenGate%20Adapter%20for%20MongoDB/OGG%20for%20mongodb%20adapter_v1.0.zip .................. [oracle@sandbox ~]$ cd $OGGBD [oracle@sandbox oggbd]$ mkdir mongo [oracle@sandbox oggbd]$ unzip -q /u01/distr/OGG_for_mongodb_adapter_v1.0.zip -d mongo/ [oracle@sandbox oggbd]$ cd mongo/ [oracle@sandbox mongo]$ ll total 36 drwxr-xr-x. 2 oracle oinstall 4096 Mar 15 15:08 bin drwxr-xr-x. 2 oracle oinstall 4096 Feb 18 2016 dirprm -rw-r--r--. 1 oracle oinstall 16621 Feb 25 2016 LICENSE.txt -rw-r--r--. 1 oracle oinstall 2465 Mar 15 15:08 pom.xml drwxr-xr-x. 3 oracle oinstall 4096 Feb 18 2016 src [oracle@sandbox mongo]$ [/code] Now that we have the adapter placed in $OGGBD/mongo/bin, we need a java driver to access the MongoDB instance. You can read how to get the drivers in the
installation guide. This is where we find a “MongoDB driver” which has all interfaces but requires the bson and mongodb-driver-core, and we have “Uber MongoDB Java Driver” containing everything. The latter is what we'll use for our replication. I am creating a new sub-directory "lib" inside the $OGGBD/mongo where I place the driver: [code lang="text"] [oracle@sandbox mongo]$ mkdir lib [oracle@sandbox mongo]$ cd lib [oracle@sandbox lib]$ wget https://oss.sonatype.org/content/repositories/releases/org/mongodb/mongo-java-driver/3.2.2/mongo-java-driver-3.2.2.jar --2016-09-01 11:46:34-- https://oss.sonatype.org/content/repositories/releases/org/mongodb/mongo-java-driver/3.2.2/mongo-java-driver-3.2.2.jar Resolving oss.sonatype.org... 52.22.249.229, 107.23.166.173 Connecting to oss.sonatype.org|52.22.249.229|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 1484724 (1.4M) [application/java-archive] Saving to: “mongo-java-driver-3.2.2.jar” 100%[=====================================================================================================================================================================>] 1,484,724 1.76M/s in 0.8s 2016-09-01 11:46:35 (1.76 MB/s) - “mongo-java-driver-3.2.2.jar” saved [1484724/1484724] [oracle@sandbox lib]$ [/code] The next step is to create our parameter files based on the examples located in $OGGBD/mongo/dirprm . For the MongoDB parameter file I just copied the file mongo.props to $OGGBD/dirprm/mongo.props and adjusted the gg.classpath pointing to our downloaded java driver and the MongoDB adapter while keeping the rest of the file intact: [code lang="text"] [oracle@sandbox oggbd]$ cat $OGGBD/dirprm/mongo.props gg.handlerlist=mongodb gg.handler.mongodb.type=oracle.goldengate.delivery.handler.mongodb.MongoDBHandler gg.handler.mongodb.clientURI=mongodb://localhost:27017/ #gg.handler.mongodb.clientURI=mongodb://ogg:ogg@localhost:27017/?authSource=admin&authMechanism=SCRAM-SHA-1 gg.handler.mongodb.mode=tx goldengate.userexit.timestamp=utc goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=DEBUG gg.report.time=30sec ##CHANGE THE PATH BELOW <strong>gg.classpath=/u01/oggbd/mongo/lib/mongo-java-driver-3.2.2.jar:/u01/oggbd/mongo/bin/ogg-mongodb-adapter-1.0.jar:</strong> javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar: [/code] For an initial load I've created a parameter file irmongo.prm based on sample rmongo.prm from $OGGBD/mongo/dirprm. [code lang="text"] [oracle@sandbox oggbd]$ cat $OGGBD/dirprm/irmongo.prm -- Initial load SPECIALRUN END RUNTIME EXTFILE dirdat/initld TARGETDB LIBFILE libggjava.so SET property=dirprm/mongo.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP ggtest.*, TARGET ggtest.*; [/code] So, GoldenGate is now ready, and we can focus on the MongoDB instance. For demonstration we are using a really simple installation without any special customization. I’ve used the latest community edition of MongoDB 3.2. It can be easily installed to your box using yum service from the MongoDB repository. You can read the step-by-step instruction
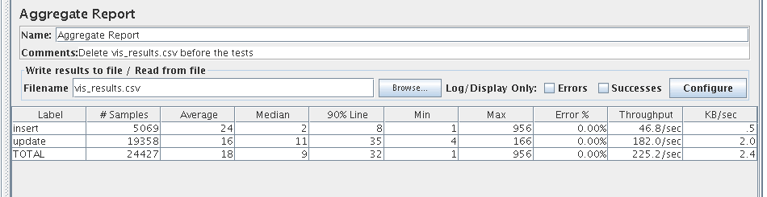
here [code lang="text"] [oracle@sandbox oggbd]$ cat /etc/yum.repos.d/mongodb-org-3.2.repo [mongodb-org-3.2] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.2/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-3.2.asc [oracle@sandbox oggbd]$ [root@sandbox ~]# yum install -y mongodb-org ............ [root@sandbox ~]# rpm -qa | grep mongo mongodb-org-server-3.2.9-1.el6.x86_64 mongodb-org-mongos-3.2.9-1.el6.x86_64 mongodb-org-3.2.9-1.el6.x86_64 mongodb-org-tools-3.2.9-1.el6.x86_64 mongodb-org-shell-3.2.9-1.el6.x86_64 [root@sandbox ~]# service mongod start [root@sandbox ~]# service mongod status mongod (pid 10459) is running... [root@sandbox ~]# [/code] I've made minimal changes in the default mongodb configuration and hence am pretty much using it as it is out of box. From the mongodb shell you can check existing databases and see that nothing has been created so far. [code lang="text"] [oracle@sandbox ~]$ mongo MongoDB shell version: 3.2.9 connecting to: test Server has startup warnings: 2016-08-30T13:17:11.291-0400 I CONTROL [initandlisten] 2016-08-30T13:17:11.291-0400 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. rlimits set to 1024 processes, 64000 files. Number of processes should be at least 32000 : 0.5 times number of files. > show dbs local 0.000GB > [/code] Now that everything is ready to go, I can run the initial load using an OGG trail file. As you can see I’ve used a passive replicat with the parameter file created earlier. [code lang="text"] [oracle@sandbox oggbd]$ ./replicat paramfile dirprm/irmongo.prm reportfile dirrpt/irmongo.rpt [oracle@sandbox oggbd]$ [/code] As result I got a new database in MongoDB with two collections(tables) inside. Exactly what we would expect. [code lang="text"] > show dbs GGTEST 0.000GB local 0.000GB > use GGTEST switched to db GGTEST > show collections TEST_TAB_1 TEST_TAB_2 > db.TEST_TAB_1.find() { "_id" : ObjectId("57c8789452ed9223e6036190"), "ACC_DATE" : "2014-10-26:08:18:58", "USE_DATE" : "2016-02-13:08:34:19", "RND_STR_1" : "BGBXRKJL", "RND_STR_2" : "M6ZSQF4V", "ID" : "1" } { "_id" : ObjectId("57c8789452ed9223e6036191"), "ACC_DATE" : "2014-06-07:21:59:23", "USE_DATE" : "2015-08-17:04:50:18", "RND_STR_1" : "FNMCEPWE", "RND_STR_2" : "K3UUB2TY", "ID" : "2" } { "_id" : ObjectId("57c8789452ed9223e6036192"), "ACC_DATE" : "2014-01-08:05:23:52", "USE_DATE" : "2014-05-15:02:07:09", "RND_STR_1" : "AUVZ87WS", "RND_STR_2" : "FTBZZL47", "ID" : "3" } { "_id" : ObjectId("57c8789452ed9223e6036193"), "ACC_DATE" : "2016-04-23:22:15:12", "USE_DATE" : "2014-02-22:05:46:11", "RND_STR_1" : "J8VOHVEE", "RND_STR_2" : "AF5S2KB4", "ID" : "4" } { "_id" : ObjectId("57c8789452ed9223e6036194"), "ACC_DATE" : "2015-06-04:02:44:23", "USE_DATE" : "2015-07-29:10:54:43", "RND_STR_1" : "VCGGR81W", "RND_STR_2" : "ZOBSEJYH", "ID" : "5" } > [/code] So, the initial load worked perfectly well. We got the database, collections(tables) and data inside. You can see that the new mongodb “_id” key was created for each record and the date format is “YYYY-MM-DD:HH24:MI:SS” which looks like a default date format for GoldenGate. Let's start our ongoing replication and see how it works. To make that happen we need a parameter file for the replicat. I've copied the rmongo.prm from $OGGBD/mongo/dirprm to $OGGBD/dirprm and changed only the schema mapping line without any other modifications. Here is the file: [code lang="text"] [oracle@sandbox oggbd]$ cat $OGGBD/dirprm/rmongo.prm REPLICAT rmongo -- Trail file for this example is located in "AdapterExamples/trail" directory -- Command to add REPLICAT -- add replicat rmongo, exttrail AdapterExamples/trail/tr TARGETDB LIBFILE libggjava.so SET property=dirprm/mongo.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 SOURCECATALOG ORCL MAP GGTEST.*, TARGET GGTEST.*; [oracle@sandbox oggbd]$ [/code] Now I can add the replicat and start it up: [code lang="text"] GGSCI (sandbox.localdomain) 7> add replicat rmongo, exttrail dirdat/or REPLICAT added. GGSCI (sandbox.localdomain) 8> start replicat rmongo Sending START request to MANAGER ... REPLICAT RMONGO starting GGSCI (sandbox.localdomain) 9> info rmongo REPLICAT RMONGO Last Started 2016-09-01 14:45 Status RUNNING Checkpoint Lag 00:00:00 (updated 00:00:00 ago) Process ID 8994 Log Read Checkpoint File dirdat/or000000000 First Record RBA 0 GGSCI (sandbox.localdomain) 12> [/code] The first test was a simple insert of a record into our test table: [code lang="sql"] orcl> insert into ggtest.test_tab_1 values (6,'test_ins',sysdate,'test_ins',sysdate); 1 row created. orcl> commit; Commit complete. orcl> select * from ggtest.test_tab_1 where id=6; ID RND_STR_1 USE_DATE RND_STR_2 ACC_DATE ---------------- ---------- ----------------- ---------- ----------------- 6 test_ins 09/01/16 14:58:41 test_ins 09/01/16 14:58:41 orcl> [/code] It worked perfectly well and we see the record replicated to the collection on MongoDB side. [code lang="text"] > db.TEST_TAB_1.find({"ID":"6"}) { "_id" : ObjectId("57c87a6952ed9223e6036195"), "ACC_DATE" : "2016-09-01:14:58:41", "USE_DATE" : "2016-09-01:14:58:41", "RND_STR_1" : "test_ins", "RND_STR_2" : "test_ins", "ID" : "6" } > [/code] The update worked correctly too: [code lang="sql"] orcl> update ggtest.test_tab_1 set RND_STR_1='test_upd' where id=6; 1 row updated. orcl> commit; Commit complete. orcl> [/code] With all changes successfully replicated over to the MongoDB : [code lang="text"] > db.TEST_TAB_1.find({"ID":"6"}) { "_id" : ObjectId("57c87a6952ed9223e6036195"), "ACC_DATE" : "2016-09-01:14:58:41", "USE_DATE" : "2016-09-01:14:58:41", "RND_STR_1" : "test_upd", "RND_STR_2" : "test_ins", "ID" : "6" } > [/code] And delete : [code lang="sql"] orcl> delete from ggtest.test_tab_1 where id=6; 1 row deleted. orcl> commit; Commit complete. orcl> [/code] On MongoDB : [code lang="text"] > db.TEST_TAB_1.find({"ID":"6"}) > [/code] Let's try some DDL. I will start with indexes. On MongoDB we have only one default index for “_id” key: [code lang="text"] > db.TEST_TAB_1.getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "GGTEST.TEST_TAB_1" } ] > > show collections TEST_TAB_1 > [/code] First I tried to create a new index on the Oracle side: [code lang="sql"] orcl> select index_name,column_name from dba_ind_columns where table_name='TEST_TAB_1'; INDEX_NAME COLUMN_NAME -------------------- -------------------- PK_ID ID orcl> create index ggtest.test_tab_1_udate_idx on ggtest.test_tab_1 (use_date); Index created. orcl> [/code] But it was not replicated to the MongoDB. I still had the only one default index there: [code lang="text"] > db.TEST_TAB_1.getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "GGTEST.TEST_TAB_1" } ] > [/code] When you add a column to the table it will work, but only for newly inserted records. If you try to update one of the old records and put a new value to the new column it is not going to change the old record. [code lang="sql"] orcl> alter table ggtest.test_tab_1 add new_col varchar2(10); Table altered. orcl> update ggtest.test_tab_1 set new_col='Test' where id=1; 1 row updated. orcl> commit; Commit complete. orcl> insert into ggtest.test_tab_1 values(3,dbms_random.string('x', 8),sysdate,dbms_random.string('x', 8),sysdate,'NewColTST'); 1 row created. orcl> commit; Commit complete. orcl> [/code] On MongoDB side you see changes in columns only for the newly inserted row: [code lang="text"] > db.TEST_TAB_1.find() { "_id" : ObjectId("57d047ae52ed927b7f9706c6"), "ACC_DATE" : "2014-10-26:08:18:58", "USE_DATE" : "2016-02-13:08:34:19", "RND_STR_1" : "BGBXRKJL", "RND_STR_2" : "M6ZSQF4V", "ID" : "1" } { "_id" : ObjectId("57d04eed52ed927edfb6a47a"), "ACC_DATE" : "2014-06-07:21:59:23", "USE_DATE" : "2015-08-17:04:50:18", "RND_STR_1" : "FNMCEPWE", "RND_STR_2" : "K3UUB2TY", "ID" : "2" } { "_id" : ObjectId("57d18b4052ed920232108566"), "ACC_DATE" : "2016-09-08:12:00:57", "USE_DATE" : "2016-09-08:12:00:57", "RND_STR_1" : "EZKP841L", "RND_STR_2" : "UGP3R43W", "ID" : "3", "NEW_COL" : "NewColTST" } > [/code] I tried to run c "create a table as select" (CTAS) and received the same error as for any other BD adapters : [code lang="sql"] orcl> create table ggtest.test_tab_3 as select * from ggtest.test_tab_1; Table created. orcl> [/code] [code lang="text"] > show collections TEST_TAB_1 > GGSCI (sandbox.localdomain) 1> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT ABENDED RMONGO 00:01:06 00:00:31 GGSCI (sandbox.localdomain) 2> 2016-09-02 10:43:22 INFO OGG-00987 Oracle GoldenGate Command Interpreter: GGSCI command (oracle): info all. 2016-09-02 10:48:59 ERROR OGG-00453 Oracle GoldenGate Delivery, rmongo.prm: DDL Replication is not supported for this database. 2016-09-02 10:48:59 ERROR OGG-01668 Oracle GoldenGate Delivery, rmongo.prm: PROCESS ABENDING. 2016-09-02 10:49:30 INFO OGG-00987 Oracle GoldenGate Command Interpreter: GGSCI command (oracle): info all. [/code] Of course we can use a workaround by splitting the operation into two steps: creating the table first and inserting all records from the other table after that. This workaround works perfectly well. : [code lang="sql"] orcl> create table ggtest.test_tab_3 (id number,rnd_str_1 varchar2(10),use_date date, rnd_str_2 varchar2(10),acc_date date); Table created. orcl> insert into ggtest.test_tab_3 select * from ggtest.test_tab_1; 5 rows created. orcl> commit; Commit complete. orcl> [/code] As expected, we have the collection and all of the records in MongoDB. [code lang="text"] > show collections TEST_TAB_1 TEST_TAB_3 > db.TEST_TAB_3.find() { "_id" : ObjectId("57c992f352ed92061a074f40"), "ACC_DATE" : "2014-10-26:08:18:58", "USE_DATE" : "2016-02-13:08:34:19", "RND_STR_1" : "BGBXRKJL", "RND_STR_2" : "M6ZSQF4V", "ID" : "1" } { "_id" : ObjectId("57c992f352ed92061a074f41"), "ACC_DATE" : "2014-06-07:21:59:23", "USE_DATE" : "2015-08-17:04:50:18", "RND_STR_1" : "FNMCEPWE", "RND_STR_2" : "K3UUB2TY", "ID" : "2" } { "_id" : ObjectId("57c992f352ed92061a074f42"), "ACC_DATE" : "2014-01-08:05:23:52", "USE_DATE" : "2014-05-15:02:07:09", "RND_STR_1" : "AUVZ87WS", "RND_STR_2" : "FTBZZL47", "ID" : "3" } { "_id" : ObjectId("57c992f352ed92061a074f43"), "ACC_DATE" : "2016-04-23:22:15:12", "USE_DATE" : "2014-02-22:05:46:11", "RND_STR_1" : "J8VOHVEE", "RND_STR_2" : "AF5S2KB4", "ID" : "4" } { "_id" : ObjectId("57c992f352ed92061a074f44"), "ACC_DATE" : "2015-06-04:02:44:23", "USE_DATE" : "2015-07-29:10:54:43", "RND_STR_1" : "VCGGR81W", "RND_STR_2" : "ZOBSEJYH", "ID" : "5" } > db.TEST_TAB_3.getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "GGTEST.TEST_TAB_3" } ] > [/code] Truncates are not replicated and you have to be careful because you may end up with duplicated rows in your MongoDB. I am still not sure why my truncates are not working. According to documentation they have to be replicated and I even see the source code for the truncate operation for the adapter. Maybe I am doing something wrong or maybe it is going to be fixed by a patch/update. [code lang="sql"] orcl> truncate table ggtest.test_tab_1; Table truncated. orcl> insert into ggtest.test_tab_1 select * from ggtest.test_tab_3; 5 rows created. orcl> commit; Commit complete. orcl> [/code] The old data was not wiped out and all the new inserts came through and creating duplicated records in the collection. [code lang="text"] > db.TEST_TAB_1.find() { "_id" : ObjectId("57c8789452ed9223e6036190"), "ACC_DATE" : "2014-10-26:08:18:58", "USE_DATE" : "2016-02-13:08:34:19", "RND_STR_1" : "BGBXRKJL", "RND_STR_2" : "M6ZSQF4V", "ID" : "1" } { "_id" : ObjectId("57c8789452ed9223e6036191"), "ACC_DATE" : "2014-06-07:21:59:23", "USE_DATE" : "2015-08-17:04:50:18", "RND_STR_1" : "FNMCEPWE", "RND_STR_2" : "K3UUB2TY", "ID" : "2" } { "_id" : ObjectId("57c8789452ed9223e6036192"), "ACC_DATE" : "2014-01-08:05:23:52", "USE_DATE" : "2014-05-15:02:07:09", "RND_STR_1" : "AUVZ87WS", "RND_STR_2" : "FTBZZL47", "ID" : "3" } { "_id" : ObjectId("57c8789452ed9223e6036193"), "ACC_DATE" : "2016-04-23:22:15:12", "USE_DATE" : "2014-02-22:05:46:11", "RND_STR_1" : "J8VOHVEE", "RND_STR_2" : "AF5S2KB4", "ID" : "4" } { "_id" : ObjectId("57c8789452ed9223e6036194"), "ACC_DATE" : "2015-06-04:02:44:23", "USE_DATE" : "2015-07-29:10:54:43", "RND_STR_1" : "VCGGR81W", "RND_STR_2" : "ZOBSEJYH", "ID" : "5" } { "_id" : ObjectId("57c9944652ed92061a074f45"), "ACC_DATE" : "2014-10-26:08:18:58", "USE_DATE" : "2016-02-13:08:34:19", "RND_STR_1" : "BGBXRKJL", "RND_STR_2" : "M6ZSQF4V", "ID" : "1" } { "_id" : ObjectId("57c9944652ed92061a074f46"), "ACC_DATE" : "2014-06-07:21:59:23", "USE_DATE" : "2015-08-17:04:50:18", "RND_STR_1" : "FNMCEPWE", "RND_STR_2" : "K3UUB2TY", "ID" : "2" } { "_id" : ObjectId("57c9944652ed92061a074f47"), "ACC_DATE" : "2014-01-08:05:23:52", "USE_DATE" : "2014-05-15:02:07:09", "RND_STR_1" : "AUVZ87WS", "RND_STR_2" : "FTBZZL47", "ID" : "3" } { "_id" : ObjectId("57c9944652ed92061a074f48"), "ACC_DATE" : "2016-04-23:22:15:12", "USE_DATE" : "2014-02-22:05:46:11", "RND_STR_1" : "J8VOHVEE", "RND_STR_2" : "AF5S2KB4", "ID" : "4" } { "_id" : ObjectId("57c9944652ed92061a074f49"), "ACC_DATE" : "2015-06-04:02:44:23", "USE_DATE" : "2015-07-29:10:54:43", "RND_STR_1" : "VCGGR81W", "RND_STR_2" : "ZOBSEJYH", "ID" : "5" } > > db.TEST_TAB_1.count() 10 > [/code] I continued the test by checking performance in different behaviours for the replication. It had been started from a big transaction. Big and lengthy transactions are the problem for many logical replications. Of course I had only limited, not maybe enough powered machines and couldn’t run really big transactions. But, nevertheless, even 1,000,000 insert revealed some interesting results. I did a simple insert to the replicated table for about 1,000,000 records. [code lang="sql"] orcl>insert into ggtest.test_tab_1 with v1 as (select dbms_random.string('x', 8) as rnd_str_1, sysdate-(level+dbms_random.value(0,1000)) as use_date from dual connect by level <1000), v2 as (select dbms_random.string('x', 8) as rnd_str_2, sysdate-(level+dbms_random.value(0,1000)) as acc_date from dual connect by level <1000) 4 select rownum as id,v1.rnd_str_1,v1.use_date,v2.rnd_str_2,v2.acc_date from v1,v2; 998001 rows created. orcl> commit; [/code] The 998,000 records is not an overly huge amount, but even for this volume it took a lot of time to replicate to the MongoDB side using all default parameters. As mentioned, I used all default parameters and achieved a rate about 300,000 records per hour or about 83 ops. Not impressive at all. I switched the "gg.handler.mongodb.mode" parameter in mongo.props file from the default "tx"(transactional) to "op"(operational) and the rate increased to 807 ops. Or about ten times faster in comparison with "tx" mode but still not good enough. After some investigation I found that the most of time was spent writing the debug log for the replicat. Therefore I switched the "gg.log.level" parameter from "DEBUG" to "INFO" which changed everything! My 998,000 records were applied to the MongoDB in less than 2 minutes with rate 9,500 ops! It was really good result from performance side but the replicat was aborted twice by java memory issues. So it seems that when you improve the speed of your replicat, the java Garbage Collector cannot keep up with the pace and hence more heap memory is needed. Here are the errors I was getting when my replicat was aborted: [code lang="text"] "java.lang.OutOfMemoryError: GC overhead limit exceeded." [/code] For operational mode I increased mx for my java heap memory from the default 512M to 1024M and it worked really well. But for for transnational mode even 1024M was not enough and it would still occasionally abort. This does somewhat makes sense since it should keep way more information in memory before committing it to the database. Nevertheless the transaction mode performance also improved significantly with the "INFO" log level. It took just a little over 5 minutes to apply all the inserts including a couple of replicat restarts. The final step was to check how it worked with small transactions. I ran some tests using JMeter applying different OLTP workload. I didn’t find any problems running up to 227 transactions per second with 75% updates. The only issue I noticed were some delays in the reaction to commands to get status or statistics for the replicat process.
Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.
 Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.
Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.
No Comments Yet
Let us know what you think