On this page
Share this
Share this
OCI Dashboard – A Single pane of Glass to your OCI Workloads – Part 1
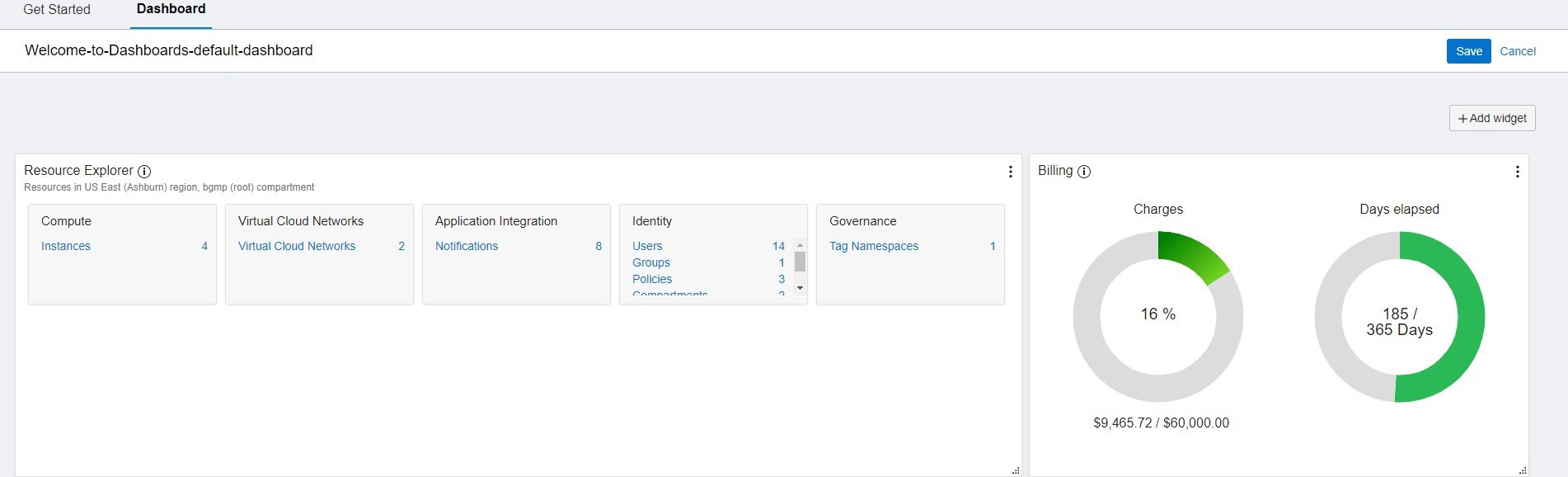
OCI Dashboard – A Single pane of Glass to your OCI Workloads – Part 1
Jun 1, 2022 12:00:00 AM
3
min read
Four Factors Not to Skip in Your Cloud Migration Strategy
![]()
Four Factors Not to Skip in Your Cloud Migration Strategy
Jan 28, 2021 12:00:00 AM
2
min read
Five Best Practices for Setting Dispatchers on Shared Connections
![]()
Five Best Practices for Setting Dispatchers on Shared Connections
Mar 15, 2021 12:00:00 AM
1
min read