Overview
When working with Amazon AWS Aurora, there are some steps to consider when trying to get data out of an active Aurora master into a slave, potentially into a EC2 instance or offsite in another data centre. Creating an external mysql to Aurora gives the option to move out of Aurora, or to have the flexibility to move data around as desired. With AWS RDS instances this task is pretty simple because you can do the following :- Create a read replica
- Stop the slave process
- Capture the positioning
- Dump the database
Amazon AWS Documentation
In AWS's documentation on step "3. Create a snapshot of your replication master", it states that a slave can be created that is external to AWS Aurora such as an EC2 instance, or an RDS MySQL or Maria DB instance by following these steps.- Create a snapshot of your Aurora Instance
- Create a new Aurora cluster from the snapshot
- Apply the proper parameters file to enable bin logs to be able to replicate
- Connect to the instance and perform "SHOW MASTER STATUS"
- The new Aurora instance has to be rebooted to apply a custom parameters file in order to enable bin logs. Without rebooting the "SHOW MASTER STATUS" is empty
- Rebooting the Aurora instance flushes the logs and moves to the next bin log file
Documentation Correction
To correct the documentation the following can be performed:- Create a snapshot of your Aurora Instance
- Create a new Aurora cluster from the snapshot
- Apply the proper parameters file to enable bin logs to be able to replicate
- Connect to the instance and perform "SHOW BINARY LOGS"
- Record the last bin log file and the size of the bin log which is in fact the correct positioning to use to configure slave replication.
- Perform a MySQL dump
- Restore the MySQL dump into your new server
- Use the bin log file and the size as the position for slave replication.
Example Steps
To prove that this works I have performed the steps and have captured the following data.Step 1. I Create an AWS Aurora instance with data being updated and bin logging turned on. Step 2. I Created a snapshot of the Aurora instance Step 3. Restored the snapshot into a new Aurora Instance. (Default parameters file is applied automatically) Step 4. Connected and executed "SHOW MASTER STATUS"[code lang="sql"] mysql> show master status; Empty set (0.00 sec) [/code]
Step 5. Applied the parameters that are currently applied to my original AWS Aurora instance using MIXED bin logs Step 6. Rebooted the instance Step 7. I connected and executed "SHOW MASTER STATUS". This shows the new bin log file and position.[code lang="sql"] mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000696 Position: 120 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) [/code]
Step 8. Executed "SHOW BINARY LOGS". This shows the last bin log and the correct positioning before the bin log files were rotated. The file and position to use in this example are mysql-bin-changelog.000695 and 101168877[code lang="sql"] mysql> SHOW BINARY LOGS; +----------------------------+-----------+ | Log_name | File_size | +----------------------------+-----------+ | mysql-bin-changelog.000693 | 134217926 | | mysql-bin-changelog.000694 | 134218631 | | mysql-bin-changelog.000695 | 101168877 | | mysql-bin-changelog.000696 | 120 | +----------------------------+-----------+ [/code]
Step 9. Performed a MySQL dump of the restored AWS Aurora instance Step 10. Restored the MySQL dump into a new MySQL instance Step 11. Configured replication using mysql-bin-changelog.000695 as the file and 101168877 as the bin log position.[code lang="sql"] CHANGE MASTER TO MASTER_HOST = 'test-master.cru25zyvfc.us-east-1.rds.amazonaws.com', MASTER_USER = 'repl', MASTER_PASSWORD = '', MASTER_LOG_FILE = 'mysql-bin-changelog.000695', MASTER_LOG_POS = 101168877;</pre> [/code]
Proof
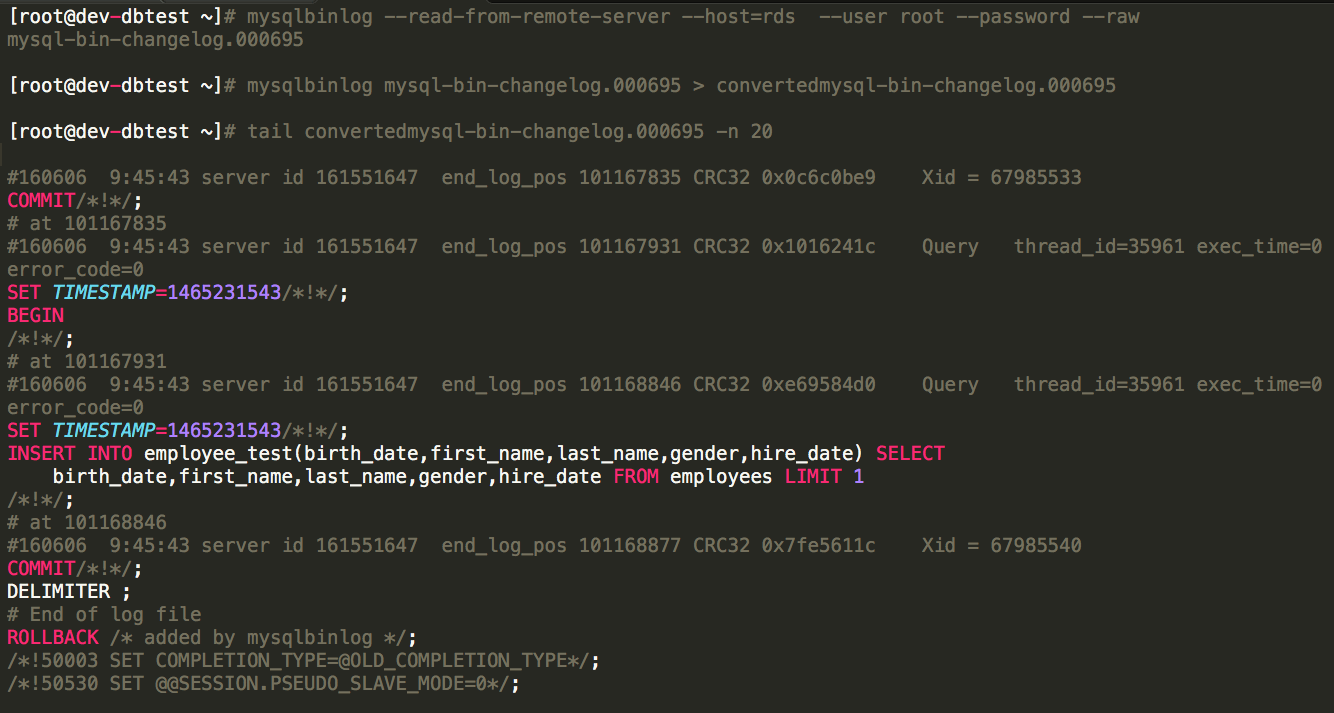
Some people do not know that the bin log positioning and the file size of the bin log file are one in the same. The position in a bin log is based upon the file size of the bin log file at the time the transaction is added. Examples will be provided.End of mysql-bin-changelog.000695 from snapshot restore
The key items that we want to take away from the end of the bin log file are the following- With each transaction there is a BEGIN, STATEMENT, and a COMMIT that happen in three different positions
- BEGIN = # at 101167835
- STATEMENT = # at 101167931
- COMMIT = # at 101168846
mysql-bin-changelog.000695 from AWS Aurora Master
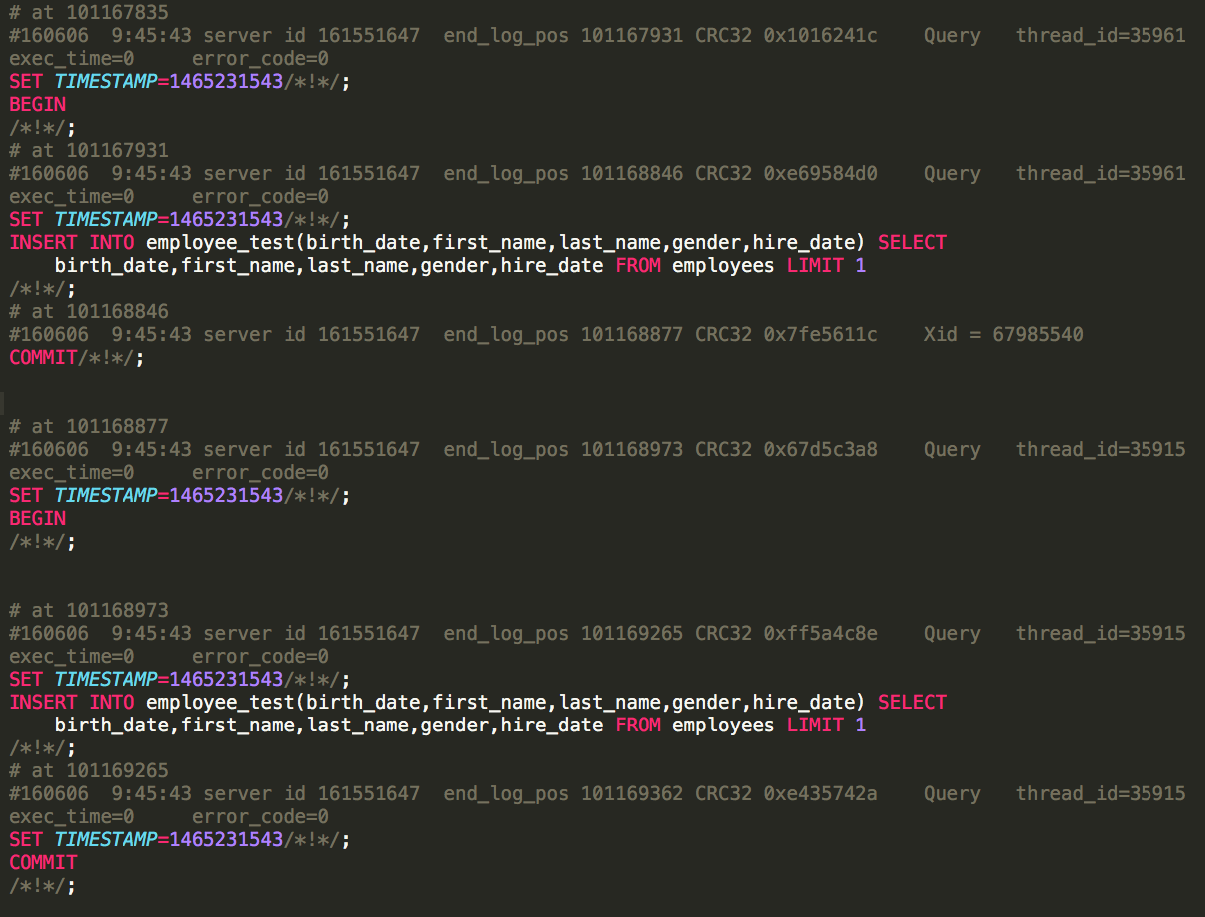
Conclusion
When setting up an external slave for an Aurora master the File_size of the previous bin log can be safely used as the slave replication position when using a snapshot of an Amazon AWS Aurora instance. This way you can setup a slave outside of RDS if you would like.
On this page
Share this
Share this
gh-ost with Amazon RDS / Aurora
![]()
gh-ost with Amazon RDS / Aurora
Jan 30, 2018 12:00:00 AM
4
min read
Planning for MySQL 5.7 End of Life with AWS Aurora

Planning for MySQL 5.7 End of Life with AWS Aurora
Jul 22, 2024 3:31:53 PM
3
min read
pt-online -schema corner case: When you don’t want to replicate your alter activities across the whole cluster.
![]()
pt-online -schema corner case: When you don’t want to replicate your alter activities across the whole cluster.
Nov 21, 2022 12:00:00 AM
5
min read