Share this
by Evan Seabrook on Jun 9, 2021 12:00:00 AM
Apache Beam is an SDK (software development kit) available for Java, Python, and Go that allows for a streamlined ETL programming experience for both batch and streaming jobs. It’s the SDK that GCP Dataflow jobs use and it comes with a number of I/O (input/output) connectors that let you quickly read from and write to popular data sources.
Today, we’ll be building a very basic I/O connector that we can use to fetch tweets from Twitter’s API. As an added bonus, we’ll also look at loading those tweets into BigQuery and deploying our job to GCP Dataflow.
Beam abstractions and hierarchy
Before digging into the code, let’s familiarize ourselves with the abstractions provided by Beam and how they work together:
- Pipeline: A pipeline is the outermost model that we’re going to deal with. It represents the entire flow of the pipeline and can be configured with PipelineOptions.
- PipelineOptions: PipelineOptions is an interface provided by Apache Beam that you implement to provide runtime arguments to your pipeline. This is helpful for passing along variables and to drive the behavior of your pipeline.
- PCollection: A PCollection is a distributed dataset that is produced and consumed by steps in your pipeline.
- PTransform: A PTransform is a data processing step that occurs in your pipeline. A pipeline typically has multiple PTransforms, each one outputting a PCollection as input to the next.
- DoFn: A DoFn is a step that’s applied per element. One or more DoFn functions are applied to the data passed into a PTransform.
Getting started
To follow along with the code examples, check out the code here: https://github.com/evanseabrook/TwitterFetcher.
Please note that if you want to build the project and deploy it, you’ll need to:
- Create a Google Cloud Platform project.
- Have the latest version of the gcloud CLI tools.
- Set up a Twitter API app in the Twitter Developer Portal.
- Install JDK 8 and Maven 3.8.1.
Building the I/O connector
With the basics covered, we can now focus on the fun stuff—building the I/O connector! To do this, we’ll need to create two new classes:
- A new DoFn, which will fetch the Tweets for us, and
- A new PTransform, which is going to call our DoFn and encode the results into a serializable model that we can use later in our pipeline.
Building our DoFn class
static class ListTweetsFn extends DoFn<String, TweetObject> {
private transient TwitterClient client;
private ValueProvider<String> apiKey;
private ValueProvider<String> apiSecretKey;
private ValueProvider<String> accessToken;
private ValueProvider<String> accessTokenSecret;
private final Logger logger = LoggerFactory.getLogger(ListTweetsFn.class);
ListTweetsFn(
ValueProvider<String> apiKey,
ValueProvider<String> apiSecretKey,
ValueProvider<String> accessToken,
ValueProvider<String> accessTokenSecret
) {
this.apiKey = apiKey;
this.apiSecretKey = apiSecretKey;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
}
@Setup
public void initClient() {
TwitterCredentials creds = TwitterCredentials.builder()
.apiKey(this.apiKey.get())
.apiSecretKey(this.apiSecretKey.get())
.accessToken(this.accessToken.get())
.accessTokenSecret(this.accessTokenSecret.get())
.build();
this.client = new TwitterClient(creds);
}
@ProcessElement
public void listTweets(
@Element String twitterHandle,
OutputReceiver<TweetObject> outputReceiver
) {
// Fetch Tweets for our twitterHandle that have been created in the past 7 days.
List<Tweet> tweets = this.client.searchForTweetsWithin7days(String.format("from:%s", twitterHandle));
for (Tweet t : tweets ) {
logger.debug(String.format("Received tweet: %s", t.getText()));
outputReceiver.output(new TweetObject(
t.getId(),
new String(t.getText().getBytes(), StandardCharsets.UTF_8),
t.getAuthorId(),
t.getRetweetCount(),
t.getLikeCount(),
t.getReplyCount(),
t.getQuoteCount(),
t.getCreatedAt(),
t.getLang()
));
}
}
}
There are a couple of things going on in this DoFn implementation:
- In the constructor, we’re initializing several properties; these are runtime variables that we’re passing in the driver.
- We have a method, initClient, that’s annotated with DoFn.Setup. In this method, we set up our Twitter API client. Methods annotated with DoFn.Setup let Apache Beam know to call that method automatically at runtime.
- Our main logic is in listTweets, which is annotated with DoFn.ProcessElement. This annotation tells Apache Beam that this is the method to call on each element as the main DoFn entrypoint.
Our method makes the call to the Twitter API and outputs the results to our OutputReceiver, which is how DoFns handle output. In this example, we’re only gathering the last seven days’ worth of tweets for a single user. If we were extracting more data, we might want to use a Splittable DoFn (SDF), which would introduce parallelism, but add a bit more complexity.
Building our PTransform class
public static class ListTweets extends PTransform<PBegin, PCollection<TweetObject>> {
private final ValueProvider<String> twitterHandle;
private final ValueProvider<String> apiKey;
private final ValueProvider<String> apiSecretKey;
private final ValueProvider<String> accessToken;
private final ValueProvider<String> accessTokenSecret;
ListTweets(ValueProvider<String> twitterHandle,
ValueProvider<String> apiKey,
ValueProvider<String> apiSecretKey,
ValueProvider<String> accessToken,
ValueProvider<String> accessTokenSecret
) {
this.twitterHandle = twitterHandle;
this.apiKey = apiKey;
this.apiSecretKey = apiSecretKey;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
}
public PCollection<TweetObject> expand(PBegin input) {
return input
.apply(Create.ofProvider(this.twitterHandle, StringUtf8Coder.of()))
.apply(ParDo.of(new ListTweetsFn(this.apiKey, this.apiSecretKey, this.accessToken, this.accessTokenSecret)))
.setCoder(SerializableCoder.of(TweetObject.class));
}
}
If we have a look at our expand() method (which is an abstract method of PTransform), we:
- Create a PCollection containing the Twitter handle we want to download tweets from.
- Pass that PCollection into our DoFn (called using ParDo).
- Encode the tweet models into a serializable model, allowing us to work more easily with the BigQuery I/O later on.
Here’s the code for the serializable model:
package ca.evanseabrook.twitter.model;
import javax.annotation.Nullable;
import java.time.LocalDateTime;
import java.util.Objects;
public class TweetObject implements java.io.Serializable {
public String tweetId;
public String tweetBody;
public String authorId;
public int retweetCount;
public int likeCount;
public int replyCount;
public int quoteCount;
public LocalDateTime createdAt;
public String lang;
public TweetObject(
@Nullable String tweetId,
@Nullable String tweetBody,
@Nullable String authorId,
int retweetCount,
int likeCount,
int replyCount,
int quoteCount,
@Nullable LocalDateTime createdAt,
@Nullable String lang
) {
this.tweetId = tweetId;
this.tweetBody = tweetBody;
this.authorId = authorId;
this.retweetCount = retweetCount;
this.likeCount = likeCount;
this.replyCount = replyCount;
this.quoteCount = quoteCount;
this.createdAt = createdAt;
this.lang = lang;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
TweetObject that = (TweetObject) o;
return retweetCount == that.retweetCount &&
likeCount == that.likeCount &&
replyCount == that.replyCount &&
quoteCount == that.quoteCount &&
Objects.equals(tweetId, that.tweetId) &&
Objects.equals(tweetBody, that.tweetBody) &&
Objects.equals(authorId, that.authorId) &&
Objects.equals(createdAt, that.createdAt) &&
Objects.equals(lang, that.lang);
}
@Override
public int hashCode() {
return Objects.hash(tweetId, tweetBody, authorId, retweetCount, likeCount, replyCount, quoteCount, createdAt, lang);
}
}
And here’s the code for the entire “TwitterReader” class, which includes our DoFn and PTransform from above:
package ca.evanseabrook.twitter.io;
import com.github.redouane59.twitter.TwitterClient;
import com.github.redouane59.twitter.dto.tweet.*;
import com.github.redouane59.twitter.signature.TwitterCredentials;
import ca.evanseabrook.twitter.model.TweetObject;
import org.apache.beam.sdk.coders.*;
import org.apache.beam.sdk.options.ValueProvider;
import org.apache.beam.sdk.transforms.Create;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.PTransform;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.values.*;
import java.nio.charset.StandardCharsets;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TwitterReader {
public static ListTweets read(ValueProvider<String> apiKey,
ValueProvider<String> apiSecretKey,
ValueProvider<String> accessToken,
ValueProvider<String> accessTokenSecret,
ValueProvider<String> twitterUser) {
return new ListTweets(
twitterUser,
apiKey,
apiSecretKey,
accessToken,
accessTokenSecret
);
}
public static class ListTweets extends PTransform<PBegin, PCollection<TweetObject>> {
private final ValueProvider<String> twitterHandle;
private final ValueProvider<String> apiKey;
private final ValueProvider<String> apiSecretKey;
private final ValueProvider<String> accessToken;
private final ValueProvider<String> accessTokenSecret;
ListTweets(ValueProvider<String> twitterHandle,
ValueProvider<String> apiKey,
ValueProvider<String> apiSecretKey,
ValueProvider<String> accessToken,
ValueProvider<String> accessTokenSecret
) {
this.twitterHandle = twitterHandle;
this.apiKey = apiKey;
this.apiSecretKey = apiSecretKey;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
}
public PCollection<TweetObject> expand(PBegin input) {
return input
.apply(Create.ofProvider(this.twitterHandle, StringUtf8Coder.of()))
.apply(ParDo.of(new ListTweetsFn(this.apiKey, this.apiSecretKey, this.accessToken, this.accessTokenSecret)))
.setCoder(SerializableCoder.of(TweetObject.class));
}
}
static class ListTweetsFn extends DoFn<String, TweetObject> {
private transient TwitterClient client;
private ValueProvider<String> apiKey;
private ValueProvider<String> apiSecretKey;
private ValueProvider<String> accessToken;
private ValueProvider<String> accessTokenSecret;
private final Logger logger = LoggerFactory.getLogger(ListTweetsFn.class);
ListTweetsFn(
ValueProvider<String> apiKey,
ValueProvider<String> apiSecretKey,
ValueProvider<String> accessToken,
ValueProvider<String> accessTokenSecret
) {
this.apiKey = apiKey;
this.apiSecretKey = apiSecretKey;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
}
@Setup
public void initClient() {
TwitterCredentials creds = TwitterCredentials.builder()
.apiKey(this.apiKey.get())
.apiSecretKey(this.apiSecretKey.get())
.accessToken(this.accessToken.get())
.accessTokenSecret(this.accessTokenSecret.get())
.build();
this.client = new TwitterClient(creds);
}
@ProcessElement
public void listTweets(
@Element String twitterHandle,
OutputReceiver<TweetObject> outputReceiver
) {
List<Tweet> tweets = this.client.searchForTweetsWithin7days(String.format("from:%s", twitterHandle));
for (Tweet t : tweets) {
logger.debug(String.format("Received tweet: %s", t.getText()));
outputReceiver.output(new TweetObject(
t.getId(),
new String(t.getText().getBytes(), StandardCharsets.UTF_8),
t.getAuthorId(),
t.getRetweetCount(),
t.getLikeCount(),
t.getReplyCount(),
t.getQuoteCount(),
t.getCreatedAt(),
t.getLang()
));
}
}
}
}
Building the pipeline
Now that we have all of our building blocks set up, let’s take a look at our pipeline:
package ca.evanseabrook.twitter;
import ca.evanseabrook.twitter.io.TwitterReader;
import com.google.api.services.bigquery.model.TableRow;
import ca.evanseabrook.twitter.options.TwitterFetcherOptions;
import ca.evanseabrook.twitter.utils.Utils;
import ca.evanseabrook.twitter.model.TweetObject;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.PipelineResult;
import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.commons.io.FileUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.net.URISyntaxException;
import java.util.Objects;
public class TwitterRecentTweetFetcher {
private static final Logger logger = LoggerFactory.getLogger(TwitterRecentTweetFetcher.class);
public static void runTwitterFetcher(TwitterFetcherOptions options) throws URISyntaxException, IOException {
Pipeline p = Pipeline.create(options);
p.apply("ReadTweets", TwitterReader.read(options.getApiKey(),
options.getApiSecret(),
options.getAccessToken(),
options.getAccessTokenSecret(),
options.getTwitterHandle()))
.apply("LoadToBq", BigQueryIO.<TweetObject>write().to(options.getSinkBQTable())
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_TRUNCATE)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
.withFormatFunction(
(TweetObject t) ->
new TableRow().set("tweet_id", t.tweetId)
.set("tweet", t.tweetBody)
.set("author_id", t.authorId)
.set("retweet_count", t.retweetCount)
.set("like_count", t.likeCount)
.set("reply_count", t.replyCount)
.set("quote_count", t.quoteCount)
.set("lang", t.lang)
.set("created_at", Utils.buildBigQueryDateTime(t.createdAt))
)
.withJsonSchema(FileUtils.readFileToString(new File(Objects.requireNonNull(TwitterRecentTweetFetcher.class.getClassLoader().getResource("schema_tweets.json")).toURI()), "UTF-8"))
.withCustomGcsTempLocation(options.getTemporaryBQLocation())
);
PipelineResult result = p.run();
try {
result.getState();
result.waitUntilFinish();
} catch (UnsupportedOperationException e) {
// Do nothing. This will be raised when generating the template, since we're waiting for the pipeline to finish.
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
TwitterFetcherOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(TwitterFetcherOptions.class);
try {
runTwitterFetcher(options);
} catch (URISyntaxException | IOException e) {
logger.error(String.format("There was an error reading the BQ schema: %s", e.getMessage()));
System.exit(1);
}
}
}
Let’s break down what’s going on in this class:
- main parses the arguments into TwitterFetcherOptions. This is a custom class that gives us our runtime arguments (or ValueProviders) from before. We then pass this to runTwitterFetcher.
- runTwitterFetcher builds our pipeline, passing in our TwitterFetcherOptions, and then chains together some transforms:
- We apply our ListTweets transform (which is what TwitterRead.read returns). This will then return a PCollection of TweetObjects, which is our custom serializable class from before.
- We run a BigQueryIO.write transform, which will take our PCollection of TweetObjects, run a format function to map our tweets to table rows, then insert the tweets into our BigQuery table after truncating/creating it.
We’re using a JSON file to describe the BigQuery schema written to by BigQueryIO—here’s what that looks like:
{
"fields": [
{
"name": "tweet_id",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "tweet",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "author_id",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "retweet_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "like_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "reply_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "quote_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "lang",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "created_at",
"type": "DATETIME",
"mode": "NULLABLE"
}
]
}
Then we have our TwitterFetcherOptions. This class extends PipelineOptions, which is Apache Beam’s model for providing arguments to the pipeline.
All of our types are ValueProvider generics, which signals to Apache Beam that these variables will be available at run-time, and not compile-time.
package ca.evanseabrook.twitter.options;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.Validation;
import org.apache.beam.sdk.options.ValueProvider;
public interface TwitterFetcherOptions extends PipelineOptions {
@Description("The handle of the Twitter user to pull Tweets for.")
@Validation.Required
ValueProvider<String> getTwitterHandle();
void setTwitterHandle(ValueProvider<String> value);
@Description("The API key to use with the Twitter API.")
@Validation.Required
ValueProvider<String> getApiKey();
void setApiKey(ValueProvider<String> value);
@Description("The API Secret to use with the Twitter API.")
@Validation.Required
ValueProvider<String> getApiSecret();
void setApiSecret(ValueProvider<String> value);
@Description("The Access token to use with the Twitter API.")
@Validation.Required
ValueProvider<String> getAccessToken();
void setAccessToken(ValueProvider<String> value);
@Description("The Access Token Secret to use with the Twitter API.")
@Validation.Required
ValueProvider<String> getAccessTokenSecret();
void setAccessTokenSecret(ValueProvider<String> value);
@Description("The path to the staging directory used by BQ prior to loading the data.")
@Validation.Required
ValueProvider<String> getTemporaryBQLocation();
void setTemporaryBQLocation(ValueProvider<String> value);
@Description("The fully qualified name of the table to be inserted into.")
@Validation.Required
ValueProvider<String> getSinkBQTable();
void setSinkBQTable(ValueProvider<String> value);
}
Deploying our Beam pipeline to GCP
To deploy our pipeline to GCP, we have to:
- Create a BigQuery dataset to house our ingested tweets.
- Set up Google Cloud Storage to facilitate our Dataflow job.
- Create our custom Dataflow template using Maven.
- Create and execute our Dataflow job.
Preparing our GCP project
First, go ahead and create a GCP project if you don’t have one yet. You can create one for free using the Google Console.
Cloud storage
Now let’s go ahead and set up our cloud storage components. You’ll need to:
- Create a bucket—you can call it anything.
- In that bucket, create three directories:
- temp: Used by Dataflow to store its temporary files at runtime.
- tempbq: Used by the pipeline itself to store files that BigQueryIO produces during its load process to BigQuery.
- templates: Where our template ends up when we run Maven to build our template.
- Create a new file called TWITTER_FETCHER_metadata, copy and paste this snippet into it, and upload it to your templates directory:
{
"description": "A pipeline that gathers recent Tweets for a given Twitter handle and stores it in BigQuery.",
"name": "Twitter Fetcher",
"parameters": [
{
"name": "apiKey",
"helpText": "The API key used to authenticate against the Twitter API.",
"label": "Twitter API Key"
},
{
"name": "apiSecret",
"helpText": "The API secret used to authenticate against the Twitter API.",
"label": "Twitter API Secret"
},
{
"name": "accessToken",
"helpText": "The access token used to authenticate against the Twitter API.",
"label": "Twitter Access Token"
},
{
"name": "accessTokenSecret",
"helpText": "The token secret used to authenticate against the Twitter API.",
"label": "Twitter Access Token Secret"
},
{
"name": "twitterHandle",
"helpText": "The Twitter handle to download Tweets for (e.g. pythian).",
"label": "Twitter Handle"
},
{
"name": "temporaryBQLocation",
"helpText": "The GCS location in which to stage data to load into BQ (e.g. gs://your-bucket/temp).",
"label": "Temporary BQ Location"
},
{
"name": "sinkBQTable",
"helpText": "The fully qualified BigQuery table name to insert into (e.g. project.dataset.table).",
"label": "BigQuery Sink"
}
]
}
This JSON file will let Dataflow know about the arguments defined in TwitterFetcherOptions.
BigQuery
This is a pretty easy step—you’ll just need to create a BigQuery dataset in your project.
You won’t need to create a table; the job will automatically create it for you.
Building the Dataflow template
To build our Dataflow template from our Beam pipeline, run the following in your project directory:
gcloud auth login --update-adc # You can skip this step if you've already set up gcloud locally
export template_location=gs://<YOUR_BUCKET>/templates/TWITTER_FETCHER
export project_id=<YOUR_PROJECT_ID>
mvn compile exec:java \
-Dexec.mainClass=ca.evanseabrook.twitter.TwitterRecentTweetFetcher \
-Dexec.args="--runner=DataflowRunner \
--project=${project_id} \
--templateLocation=${template_location} \
--region=us-central1"
This will build the template for your Dataflow job and place it in the bucket/templates directory we just created.
Creating and running your Dataflow job
To begin, navigate to Dataflow using either the search bar or the navigation menu. Then, click on Create Job from Template at the top of the page.
From there, we need to specify our new template. Under “Dataflow template,” choose “Custom template,” then select the template location used when running the Maven command. By the end, your Dataflow job should look something like this:
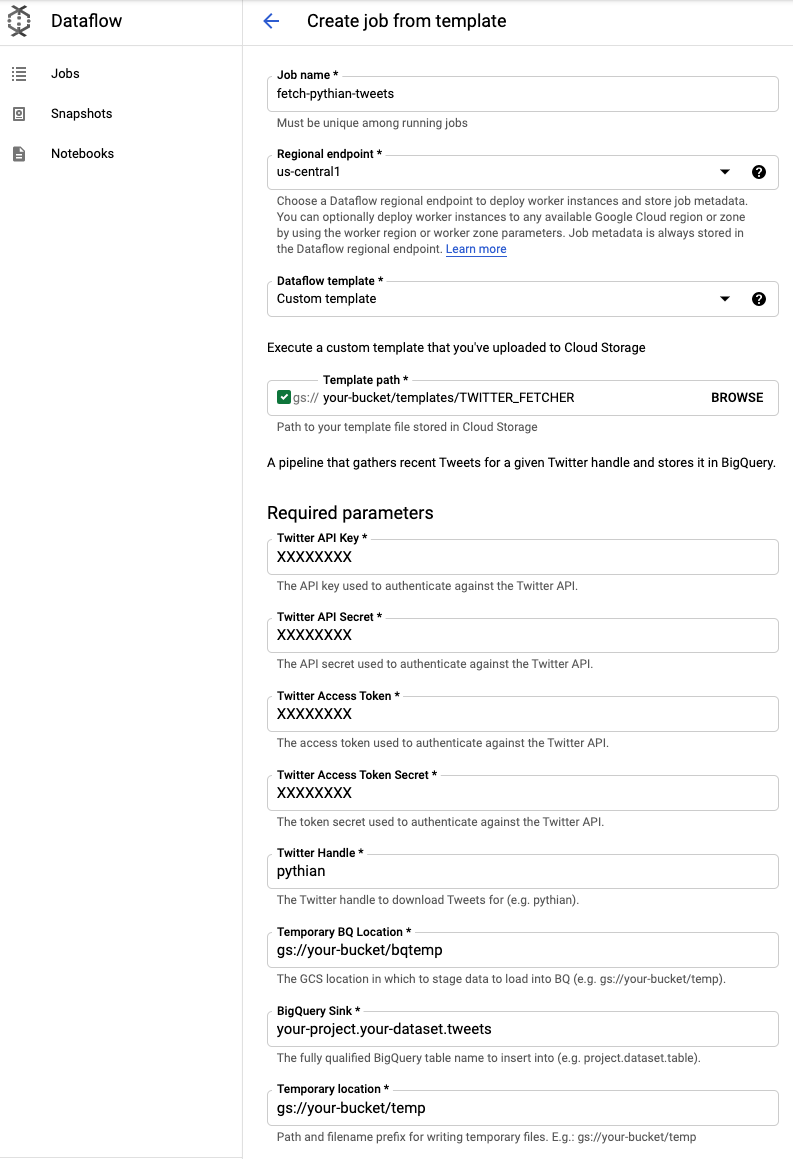
Once everything is looking good, you should be able to hit “Run Job” at the bottom of the page and have tweets loaded into your BigQuery sink table.
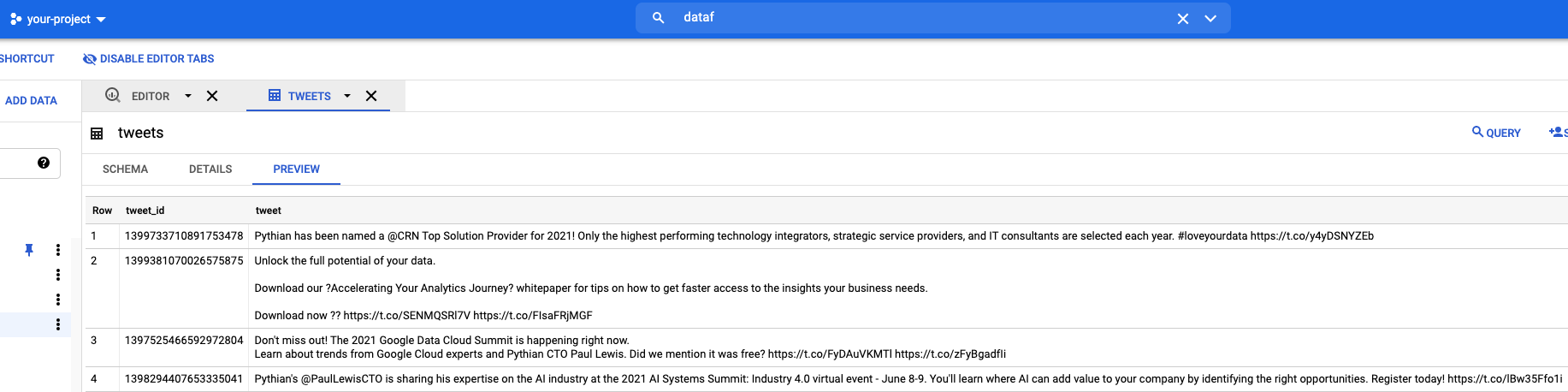
I hope you found this helpful. If you have any thoughts or questions, please leave them in the comments!
No Comments Yet
Let us know what you think