On this page
Share this
Share this
Lightweight transactions in Cassandra
![]()
Lightweight transactions in Cassandra
Mar 28, 2018 12:00:00 AM
2
min read
Backup strategies in Cassandra
![]()
Backup strategies in Cassandra
May 25, 2018 12:00:00 AM
4
min read
Cassandra as a time series database
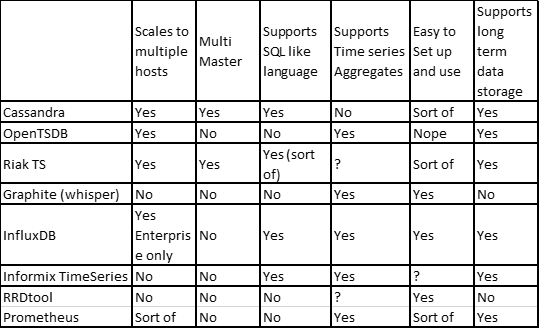
Cassandra as a time series database
Mar 23, 2018 12:00:00 AM
6
min read