Batches are one of the most misunderstood features of Apache Cassandra. They rarely improve performance. In fact, while using batches, performance may degrade. To set the stage, let’s take a look at how Cassandra handles individual mutations.
Individual mutations (insert, update, and delete operations) in Cassandra are atomic and isolated at row level.
Atomicity: It implies that either an operation takes place or nothing occurs.
Isolation: Any data that has been partially altered is hidden from other operations.
Cassandra uses batches to apply all the Data Manipulating Language (DML) statements (insertions, updates, and deletions) as a group to achieve atomicity and isolation for a single-partition batch operation or only atomicity for a multi-partition batch operation. In the context of batches, atomicity means that if at least one operation in a batch succeeds, all subsequent operations in the batch will eventually succeed as well.
In this post I would like to explain two main types of batches, each of which offers various assurances and supports different use cases:
- Single-partition batch
- Multi-partition batch
Single-partition batch
A single-partition batch is an atomic batch in which all operations are performed on the same partition and can be executed as a single write operation under the hood. As a result, single-partition batches ensure atomicity and isolation (only at the partition level within a single replica, with no cross-node isolation). A well-designed batch that targets a single partition can reduce client-server traffic and update a table with a single operation more quickly CASSANDRA-6737.
The diagram below shows that when we submit individual inserts that target the same partition we get a nice evenly distributed workload but more client-server traffic:
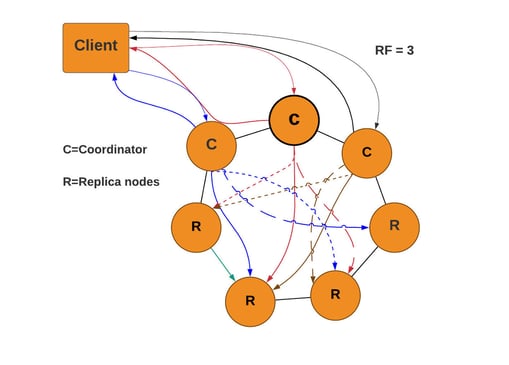
The diagram below shows the set of operations submitted as Cassandra batch, reducing client-server traffic and overall more time efficiency for the totality of operations. Single partition batches should however be limited in size (less than 5KB) to minimize heap impact. When oversized, batches can overload the coordinator nodes, making them unresponsive.
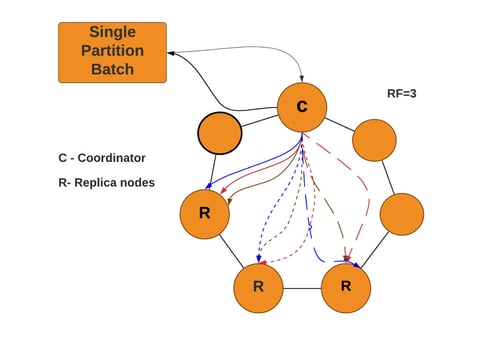
Note: When two separate tables in the same keyspace have the same partition key, this scenario also can be referred to as a single partition batch.
Multi-partition batch
A multi-partition batch is an atomic batch in which mutations are performed on different partitions of the same or different tables. Batches with multiple partitions only ensure atomicity, not isolation. One of the use cases to use a multi-partition batch is to update the same data duplicated across multiple tables due to denormalization. The use of multi-partition batches should be discouraged under most circumstances as they can significantly impact performance on the coordinator node and heap memory.
In the diagram below, a multi-partition batch actually puts a great deal of burden on a single coordinator. That’s because the coordinator must send each individual insert to the appropriate replicas. Because you’re inserting different partitions in a single round trip to the database, the coordinator will need to coordinate with a greater set of replicas–in this case, with a set of three replicas for each of the partitions. This can easily lead to a coordinator needing to send mutations to all the nodes in the cluster as we increase the number of partitions within a batch:
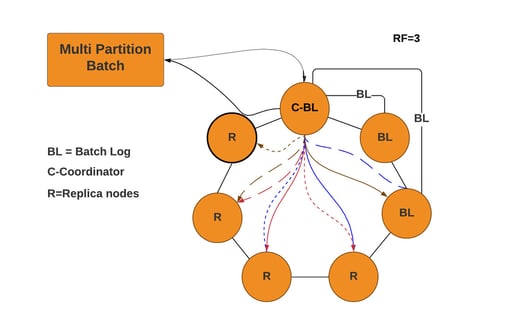
Multi-Partition Batch Execution Workflow
1. On the client side
Batches are supported on all modern client APIs, where we can group a list of statements that can be executed as a batch. If a batch fails while executing, the client can receive one of two types of exceptions:
- UnavailableException – There are not enough nodes alive to fulfill any of the updates with the specified batch Consistency Level.
- WriteTimeoutException – Timeout while either writing the batch log or applying any of the updates within the batch. This can be checked by reading the write type value of the exception (either BATCH_LOG or BATCH).
If a timeout occurs when a batch is executed, the developer has different options depending on the type of write that timed out:
- BATCH_LOG: A timeout occurred while the coordinator was waiting for the batchlog replicas to acknowledge the log. If you receive this timeout, you might need to check any underlying issues on nodes and try the batch query again.
- BATCH: If the batch is logged successfully, Cassandra applies all the statements in the batch. If for whatever reason some of the batch statements are unsuccessful, it throws a timeout exception with write type BATCH, but Cassandra replays the batch log until all statements have been applied successfully. This is how Cassandra will ensure that this batch will get eventually written to the appropriate replicas and the developer doesn’t have to do anything.
Note: Multi-partition batches ensure eventual consistency, but no isolation. This means that in a multi-partition batch the clients can read the first updated rows from the batch, while other rows are still being updated on the node.
2. On the coordinator side
When a batch is sent out to a coordinator node, each batch execution starts by creating a log entry with the complete batch on two random nodes other than the coordinator. After the coordinator is able to submit the batch log to the other nodes, it will start executing the actual statements in the batch. While the batch is executing, even if writes throw a WriteTimeoutException, it can be handled by the client as described above.
Upon successful execution, the coordinator issues a batch log deletion message to nodes containing the batch log, so that all created batch logs will be removed.
3. On the batch log replica nodes
To give you higher availability for batch operations, the coordinator sends a batchlog to two other nodes. The batch log replica nodes will check periodically if there are any pending batches to replay in the local batchlog table that haven’t been deleted by the coordinator.
Single-Partition Batch Execution Workflow
For single partition batches, no batch log is written. Because everything goes into a single partition, the coordinator doesn’t have any extra work coordinating different sets of replicas (as with multi-partition writes).
1. On the client side
If a batch fails while executing, the client can receive one of two types of exceptions:
- UnavailableException – There are not enough nodes alive to fulfill any of the updates with the specified batch Consistency Level.
- WriteTimeoutException – Timeout while applying any of the updates within the batch. In this case, the Cassandra driver replays the batch based on the retry policy.
2. On the coordinator side and replica side
The atomicity is coordinator-based. This means that when you make an atomic batch mutation, it will go to one coordinator. If one of the mutations in your batches fails because the replica responsible for it is dead, the coordinator will write a hint for that replica and will deliver it when the dead node is back up.
If the coordinator fails in the middle, the client will retry the batch by connecting to any other node in the cluster immediately.
Below is an example where all three INSERT statements in the batch below must complete successfully in order for the basket state to be right, we can use batches in such scenarios where atomicity is truly important:
CREATE TABLE basket (
username TEXT,
item_name TEXT,
price DECIMAL,
basket_total DECIMAL STATIC,
PRIMARY KEY ((username), item_name)
);
BEGIN BATCH
INSERT INTO basket(username, item_name, price) VALUES ('Sarma','cassandra cookbook', 2000);
INSERT INTO basket(username, item_name, price) VALUES ('Sarma','torch light', 1000);
INSERT INTO Basket (username, basket_total) VALUES ('Sarma', 3000)
APPLY BATCH;
Below is an anti-pattern of using batches:
CREATE TABLE users_title (
email_id text,
first_name text,
last_name text,
rating int,
title text,
PRIMARY KEY (title,email_id)
) ;
BEGIN BATCH
INSERT INTO users_email (email_id, first_name, last_name, rating,title)
VALUES ('sarma@gmail.com','sarma','kumar',9, 'Avatar');
INSERT INTO users_title (email_id, first_name, last_name, rating,title)
VALUES ('payal@gmail.com','payal','grover',9, 'Avatar');
INSERT INTO users_title (email_id, first_name, last_name, rating,title)
VALUES ('anil@gmail.com','anil','mittana',9, 'Avatar');
APPLY BATCH;
Final Recommendations
Cassandra batches are not designed to optimize performance. In fact, while using batches performance can, and will often suffer. The batch keyword in Cassandra is not a speed boost for mixing groups of mutations for bulk loads. Batches should be used to group mutations when you expect them to occur together. Batches guarantee that if a single part of your batch is successful, the entire batch is successful, but using batches for the sake of grouping usually results in performance degradation.
I hope you found this post useful. Please drop your questions in the comments and don’t forget to sign up for the next post.
Share this
Share this

Useful CQLSH Commands for Everyday Use
How to Perform (UDC) User-Defined Compactions in Cassandra
