 When ChatGPT was first released, I wondered how it could support my day-to-day job. Initially, I used ChatGPT for content creation, enhancing writing, searching reliability, and trying to force it to produce more accurate outputs. In the end, I decided to use this AI model to investigate real-life Oracle DBA issues, ranging from minor to major problems—because adopting is better than resisting.
When ChatGPT was first released, I wondered how it could support my day-to-day job. Initially, I used ChatGPT for content creation, enhancing writing, searching reliability, and trying to force it to produce more accurate outputs. In the end, I decided to use this AI model to investigate real-life Oracle DBA issues, ranging from minor to major problems—because adopting is better than resisting.
In this blog post, I will investigate an Automatic Workload Repository (AWR) report while using ChatGPT and will troubleshoot a privilege-related issue in the end. The purpose is to explore the possibility of using LLM (Large Language Model) as an ally for an Oracle DBA. A small parentheses here; language models accept text input and predict the next word or token as a return, and “large” stands for just the vast amount of data used for training.
Let’s start with AWR inputs and responses from ChatGPT. The first part of the data is “Load Profile”. This is also the beginning of the AWR report, asking ChatGPT to give some recommendations or notes if possible.
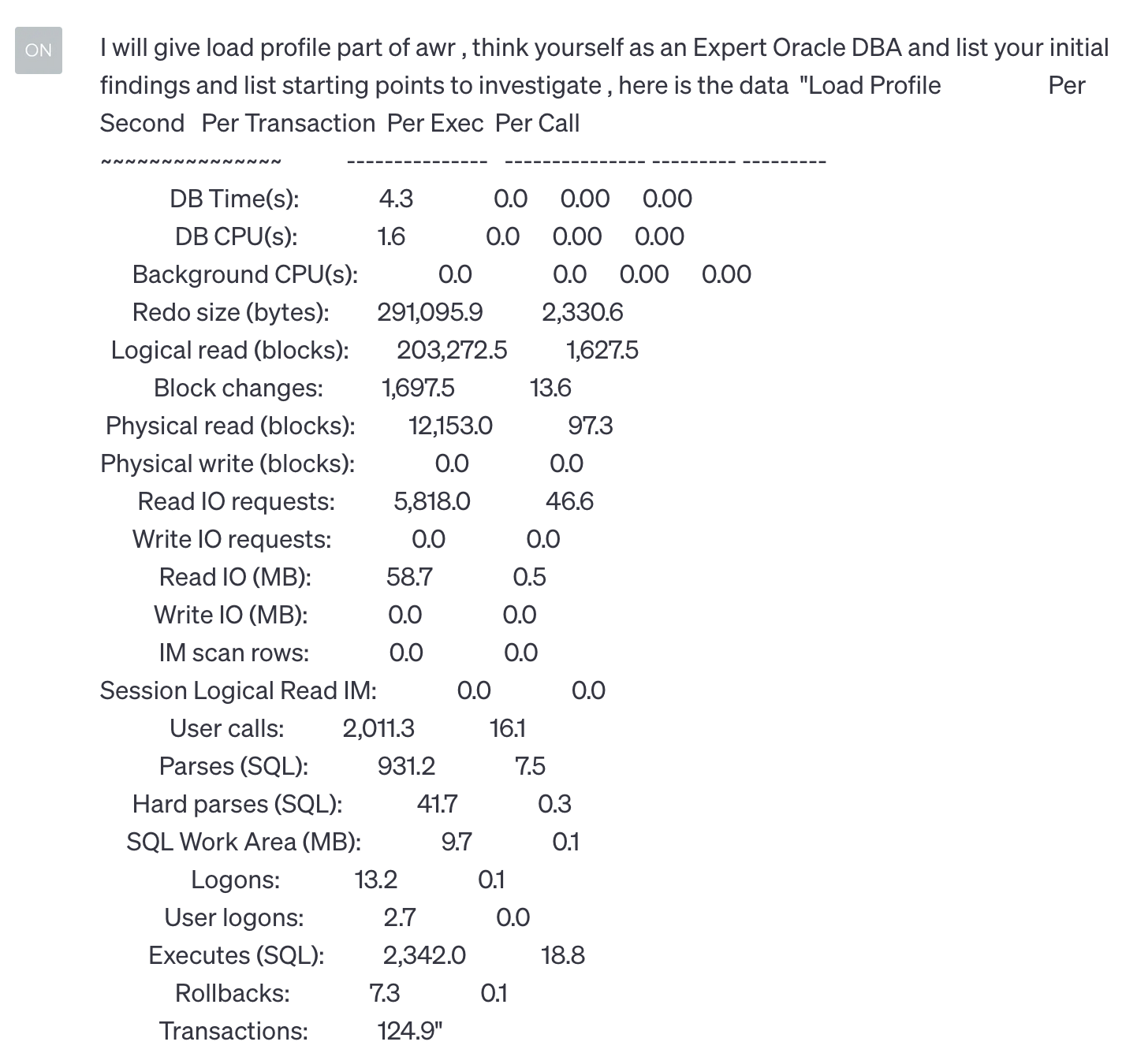
ChatGPT's response was good enough, as I would take a similar approach for analyzing the Load Profile data. To summarize ChatGPT's recommendations, it's important to start tuning the database by checking poorly performing queries and exploring using indexes to reduce physical reads.
Generally, we start from poorly performing queries, apply possible query tuning techniques, then check the DB level, look for benefits of a potential configuration change, then the lowest level of the OS, and so on.
Therefore, ChatGPT started with a similar approach to a DBA.

Well, the next input is “Top Foreground Events by Total Wait Time”, expecting here LLM to narrow down its suggestions and redirect me to some focused area. I have forced it to give the top 3 action items. Keep in mind that previous data, “Load Profile,” is also known by the same session.
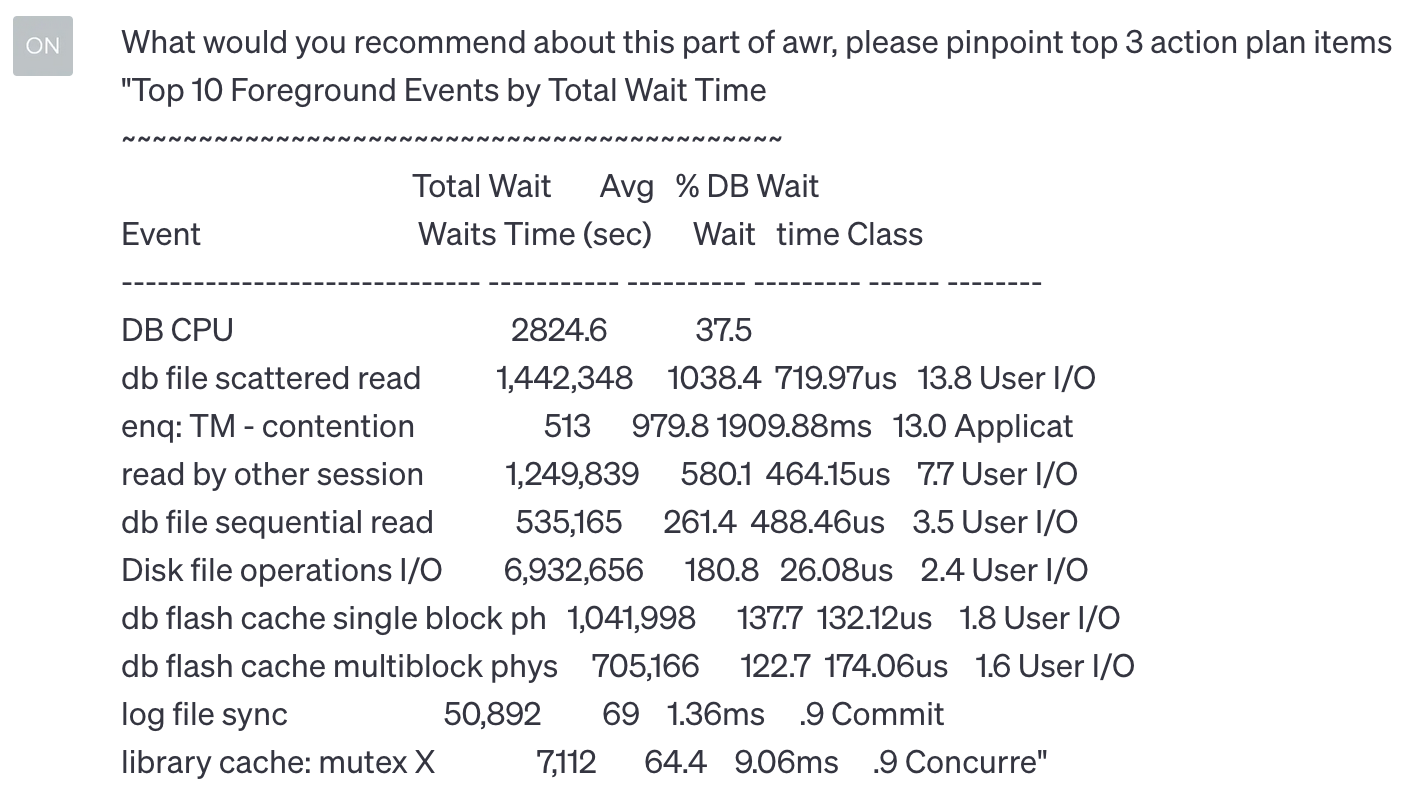
Below is the response of the LLM, with the Load Profile data ChatGPT focused on “db file scattered read,” “enq: TM-contention” and “read by other session” events but skipped “DB CPU” under the top 3 actions list.
I have returned to AWR and scanned number one SQL_ID under the list “SQL ordered by Reads,” “SQL ordered by User I/O Wait Time,” and “SQL ordered by CPU Time,” all pointing to the same SQL ID. “DB CPU Wait” is very intertwined and correlated with other waits. Therefore, it can be a result or a reason. I would choose to focus on the areas that ChatGPT recommends.
Also, I noticed multiple ADDM (automatic database diagnostic monitor) findings in the same AWR report. The action plan items provided by ChatGPT still seem appropriate. At the end of the AWR report, there are ADDM suggestions to run SQL Tuning Advisor to generate better execution plans for some SQLs that mostly wait on "db file scattered read" and "enq:TM-contention" events.

If we take a quick look for “Top Sessions” from the same AWR, the top session's number one query is experiencing a "db file scattered read" wait event. This is just another cross-check if any suggestions from ChatGPT can be followed to address the issue.
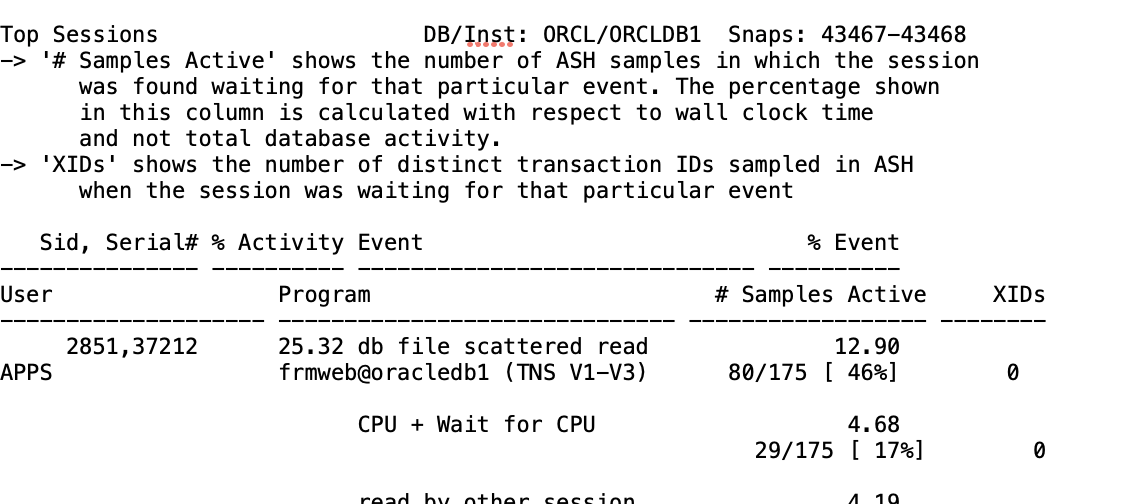
We come to a certain point at this level in terms of SQL tuning, but I would like to switch to another part of AWR data before diving into SQL tuning.
SGA Tuning with ChatGPT
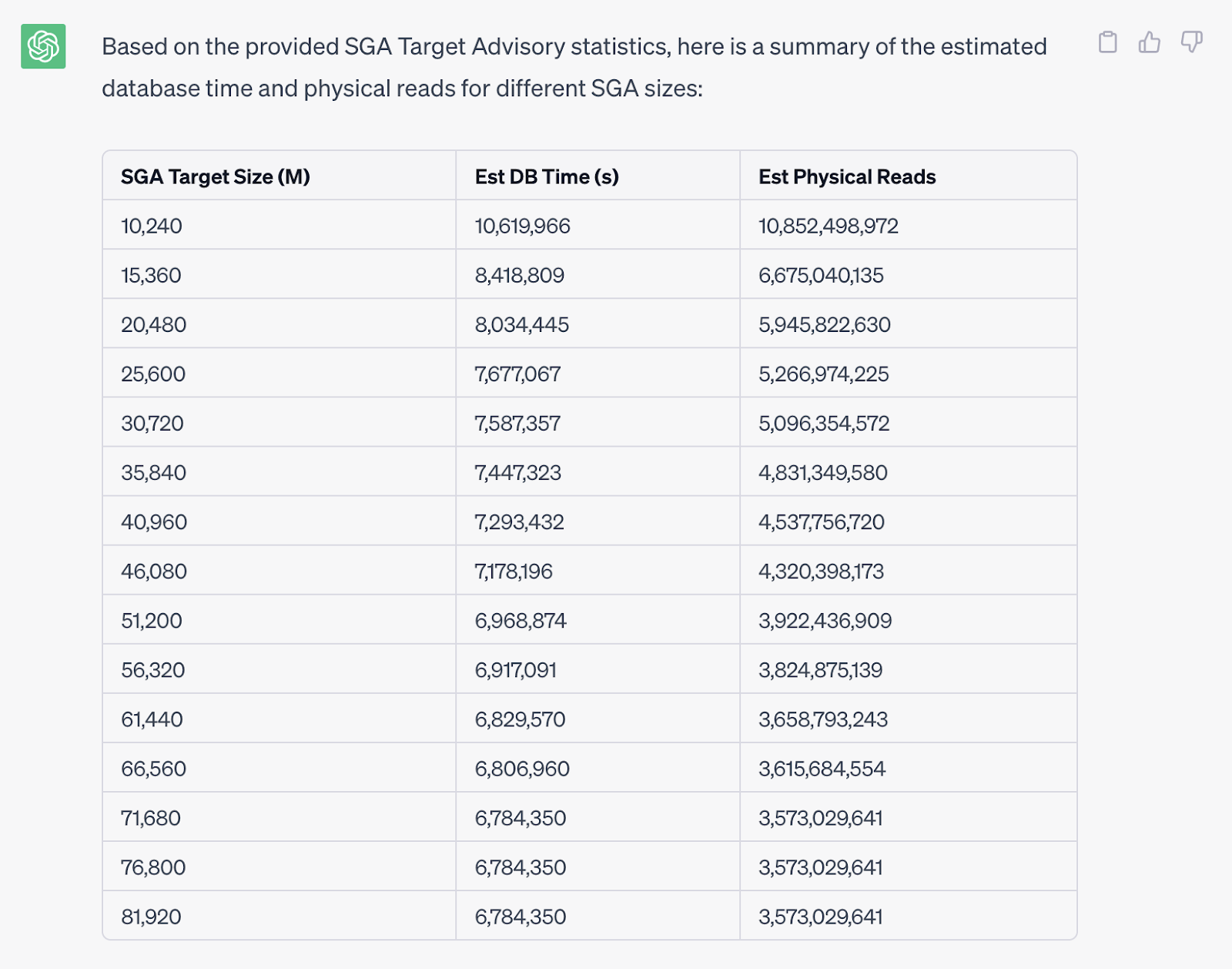
I would like to ask ChatGPT for advice on determining the appropriate SGA size based on the SGA advisory table. The "SGA Size Factor= 1" shows the current SGA value. My initial question was just asking for advice, as prompts are important when using language models. Here, I will ask general and specific questions to clarify the issue.
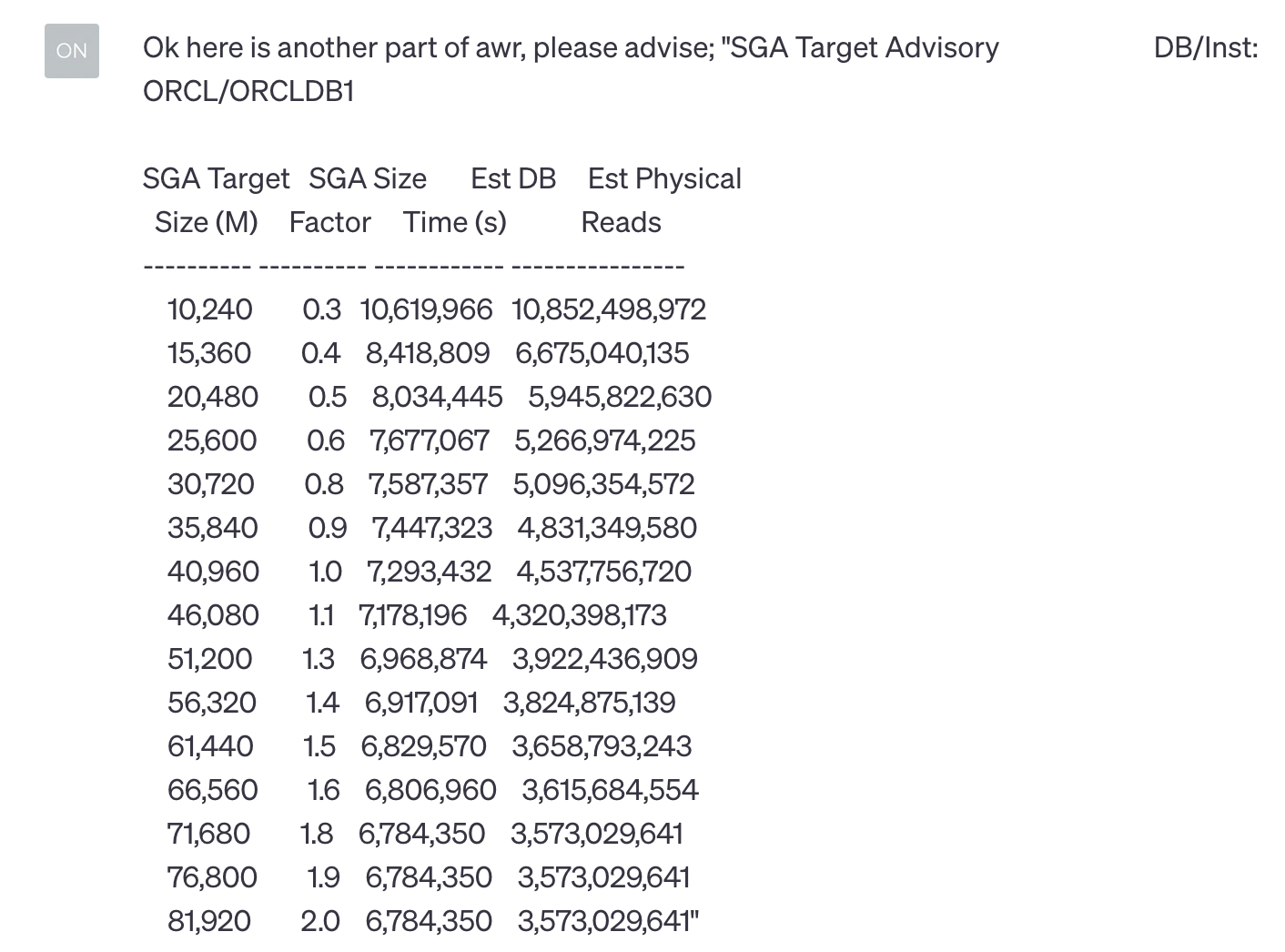
I was expecting a value chosen by AI, but in fact, it gave me a high-level analysis. Therefore, a second attempt is required here.

Although I requested the optimal SGA value, ChatGPT provided additional analysis and insights for choosing a target SGA value. While these recommendations are useful, I still require a specific value. We will make a third attempt.

Finally, ChatGPT recommended a value of around 60GB for SGA size. However, the AI was hesitant to provide an exact value and actionable steps. In my approach, I would start with a 50GB SGA and wait for the next AWR report after some time, as there is not much to gain afterward. ChatGPT's recommendation is not a bad choice, but it is necessary to verify and put your comment.

SQL Tuning with ChatGPT
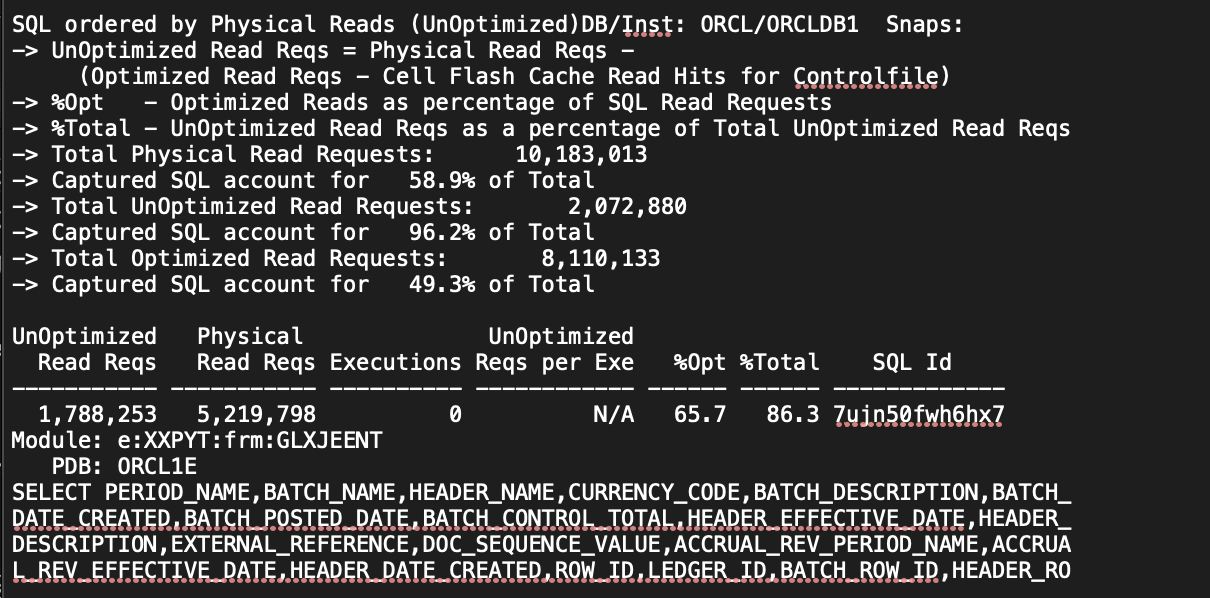
Let’s get back to the SQL Tuning part. We have identified a candidate query that needs tuning. I picked the query with SQL ID 7ujn50fwh6hx7, in which the top wait event was “db file scattered read (Table Access Full)” and also number one in “SQL order in physical reads,” and ADDM has found it.
Therefore, SQL ID 7ujn50fwh6hx7 is a sensible choice for ChatGPT’s previous comments.

I submitted the query and its execution plan to request tuning recommendations. Although it provided some useful advice, it did not offer any specific action item. For example, the first recommendation suggests creating a new index but does not specify a column name.
I also requested ChatGPT to provide an action plan for execution. However, the suggested action plan steps are general, and it is necessary to delve deeper and apply them as needed. In this investigation, we explore how ChatGPT can further assist with a tuning task while investigating an AWR report.

Therefore, I have asked ChatGPT if it can rewrite the query, assuming it will use its own recommendations:
ChatGPT was able to rewrite a query, which can be useful. However, in this case, it made some minor changes, and I understood that only a little performance gain is possible using the given query. I asked for the differences between the original query and the new one.

To crosscheck, we can go back to DB and see the current execution plan history of SQL ID 7ujn50fwh6hx7. Then, we can compare the rewritten queries and the original plans.
SQL> SELECT begin_interval_time,
sql_id,
plan_hash_value,
NVL(executions_delta, 0) execs,
trunc(
(
elapsed_time_delta / DECODE(NVL(executions_delta, 0), 0, 1, executions_delta)
) / 1000000
) avg_etime,
trunc(
(
buffer_gets_delta / DECODE(NVL(buffer_gets_delta, 0), 0, 1, executions_delta)
)
) avg_lio,
trunc(
(
disk_reads_delta / DECODE(NVL(buffer_gets_delta, 0), 0, 1, executions_delta)
)
) avg_pio,
trunc(
(
ROWS_PROCESSED_DELTA / DECODE(NVL(executions_delta, 0), 0, 1, executions_delta)
)
) avg_rows
FROM DBA_HIST_SQLSTAT S,
DBA_HIST_SNAPSHOT SS
WHERE sql_id = '7ujn50fwh6hx7'
AND ss.snap_id = S.snap_id
AND ss.instance_number = S.instance_number
AND executions_delta > 0
and begin_interval_time > to_date('01062023', 'ddmmyyyy')
ORDER BY 1,
2,
3;
BEGIN_INTERVAL_TIME SQL_ID PLAN_HASH_VALUE EXECS AVG_ETIME AVG_LIO AVG_PIO
--------------------------------------------------------------------------- ------------- --------------- ---------- ---------- ---------- ---------- AVG_ROWS ---------- 27-JUN-23 08.00.17.454 AM 7ujn50fwh6hx7 3423738608 1 2853 28313066 6383758 0 27-JUN-23 08.00.17.454 AM 7ujn50fwh6hx7 3423738608 1 1518 20910996 3359409 0 28-JUN-23 06.00.01.147 PM 7ujn50fwh6hx7 3193066624 2 2207 20018508 13771784 0
I used ChatGPT’s query to see the explained plan, and it seems not much changed using one of the hash plan 3423738608. At this point, we can say ChatGPT did some cosmetic fixes. This may be because of the query logic, missing data structure, and table structure info, but as a DBA, we can still use SQL Tuning Advisor as stated in the AWR report in the ADDM part, and the advisor can generate a better execution plan.
SQL> explain plan for
2 SELECT PERIOD_NAME, BATCH_NAME, HEADER_NAME, CURRENCY_CODE, BATCH_DESCRIPTION, BATC H_DATE_CREATED,
BATCH_POSTED_DATE, BATCH_CONTROL_TOTAL, HEADER_EFFECTIVE_DATE, HEADER_DESCRIPTION, EXTERNAL_REFERENCE, DOC_SEQUENCE_VALUE, ACCRUAL_REV_P 3 ERIOD_NAME, ACCRUAL_REV_E FFECTIVE_DATE,
HEADER_DATE_CREATED, ROW_ID, LEDGER_ID, BATCH_ROW_ID, HEADER_ROW_ID, JE_BATCH_ID, BATCH_STATUS, BUDGETARY_CONTROL_STATUS, APPROVAL_STATUS_CODE, ACTUAL_FLAG, AVERAGE_ JOURNAL_FLAG,
STATUS_VERIFI 4 ED, BATCH_RUNNING_TOTAL_DR, BATCH_RUNNING_TOTAL_CR, BATCH_RUN_TOT AL_ACCOUNTED_DR,
BATCH_RUN_TOTAL_ACCOUNTED_CR, BATCH_STATUS_RESET_FLAG, BATCH_EFFECTIVE_DATE, BATCH_ UNIQUE_DATE,
BATCH_EARLIEST_POSTABLE_DATE, POSTING_RUN_ID, REQUEST_ID, PACKET_I 5 D, BATCH_CON TEXT2,
UNRESERVATION_PACKET_ID, BATCH_USSGL_TRANSACTION_CODE, BATCH_ATTRIBUTE1, BATCH_ATTR IBUTE2,
BATCH_ATTRIBUTE3, BATCH_ATTRIBUTE4, BATCH_ATTRIBUTE5, BATCH_ATTRIBUTE6, BATCH_ATTRI BUTE7,
BATCH_ATTRIBUTE8, BATCH_ATTRIBUTE9, BAT 6 7 8 9 10 11 12 CH_ATTRIB
UTE10, BATCH_CONTEXT, JE_HEADER_ID,
HEADER_PERIOD_NAME_QRY, JE_CATEGORY, JE_SOURCE, HEADER_STATUS, MULTI_BAL_SEG_FLAG, CONVERSION_FLAG, ENCUMBRANCE_TYPE_ID, BUDGET_VERSION_ID, HEADER_CONTROL_TOTAL_NUM, HEADER_RUNNING_TOTAL_DR_N 13 UM, HEADER_RUNNING_TOTAL_CR_NUM, BALANCED_JE_FLAG, BA LANCING_SEGMENT_VALUE,
FROM_RECURRING_HEADER_ID, HEADER_UNIQUE_DATE, HEADER_EARLIEST_POSTABLE_DATE, HEADER _POSTED_DATE,
ACCRUAL_REV_FLAG, ACCRUAL_REV_STATUS, ACCRUAL_REV_JE_HEADER_ID, ACCRUA 14 L_REV_CH ANGE_SIGN_FLAG,
CURRENCY_CONVERSION_DATE, CURRENCY_CONVERSION_RATE, CURRENCY_CONVERSION_TYPE, DOC_S EQUENCE_ID,
HEADER_RUN_TOTAL_ACCOUNTED_DR, HEADER_RUN_TOTAL_ACCOUNTED_CR, HEADER_USSGL_TRANSACT ION_ 15 CODE,
TAX_STATUS_CODE, ORIGINATING_BAL_SEG_VALUE, HEADER_ATTRIBUTE1, HEADER_ATTRIBUTE2, H EADER_ATTRIBUTE3,
HEADER_ATTRIBUTE4, HEADER_ATTRIBUTE5, HEADER_ATTRIBUTE6, HEADER_ATTRIBUTE7, HEADER_ ATTRI 16 BUTE8,
HEADER_ATTRIBUTE9, HEADER_ATTRIBUTE10, HEADER_CONTEXT, HEADER_GLO 17 18 19 20 21 22 BAL_ATTRIBUTE1, HEADER_GLOBAL_ATTRIBUTE2,
HEADER_GLOBAL_ATTRIBUTE3, HEADER_GLOBAL_ATTRIBUTE4, HEADER_GLOBAL_ATTRIBUTE5, HEADE R_GLOBAL_ATTRIBUTE6,
HEADER_GLOBAL_ATTRIBUTE7, HEADER_GLOBAL_ATTRIBUTE8, HEADER_GLOBAL_ATTRIBUTE9, HEADE R_GLOBAL_ATTRI 23 BUTE10,
HEADER_GLOBAL_ATTRIBUTE_CAT, BATCH_GLOBAL_ATTRIBUTE_CAT, BATCH_GLOBAL_ATTRIBUTE1, B ATCH_GLOBAL_ATTRIBUTE2,
BATCH_GLOBAL_ATTRIBUTE3, BATCH_GLOBAL_ATTRIBUTE4, BATCH_GLOBAL_ATTRIBUTE5, BATCH_GL OBAL_ATTRIBUTE6,
BATCH_GLOBAL_ATTRIBU 24 TE7, BATCH_GLOBAL_ATTRIBUTE8, BATCH_GLOBAL_ATTRIBUTE9, BAT CH_GLOBAL_ATTRIBUTE10,
BATCH_GLOBAL_ATTRIBUTE11, BATCH_GLOBAL_ATTRIBUTE12, BATCH_GLOBAL_ATTRIBUTE13, BATCH _GLOBAL_ATTRIBUTE14,
BATCH_GLOBAL_ATTRIBUTE15, BATCH_GLOBAL_ATTRIBUTE16, BATCH 25 _GLOBAL_ATTRIBUTE17, BATCH_GLOBAL_ATTRIBUTE18,
BATCH_GLOBAL_ATTRIBUTE19, BATCH_GLOBAL_ATTRIBUTE20, HEADER_CONTEXT2, JGZZ_RECON_CON TEXT, JGZZ_RECON_REF,
REFERENCE_DATE, CREATION_DATE, CREATED_BY, LAST_UPDATE_DATE, LAST_UPDATED_BY, LAST_ UPDA 26 27 28 29 30 31 TE_LOGIN
FROM apps.GL_JE_BATCHES_HEADERS_V
WHERE ((:1 = 'A' AND actual_flag IN ('A', 'B')) OR (:2 = 'Q') OR actual_flag = :3) AND chart_of_accounts_id = :4
AND period_set_name = :5
AND accounted_period_type = :6
AND NVL(:7, 1) = 1
AND 32 gl_je_batches_headers_v.LEDGER_ID IN (
SELECT acc.ledger_id
FROM apps.gl_access_set_ledgers acc
WHERE acc.access_set_id = 1000
)
AND -1 = -1
AND je_batch_id = header_je_batch_id_qry + 0
AND HEADER_NAME LIKE :8
ORDER 33 BY batch_name, period_name; 34 35 36 37 38 39 40 41 42 43 4 4 45 46
Explained.
Let’s grab the explain plan output for ChatGPT’s rewritten query:
SQL> select plan_table_output from table(dbms_xplan.display('plan_table',null,'basic'));

I tried to force ChatGPT a little bit more to behave like SQL Tuning Advisor. My next prompt is:
“Let's say you are an SQL tuning advisor. Can you give some more recommendations, like a better execution plan or new indexes for the given query? “

Recommendation number five caught my attention, as I had already been considering partitioning before conducting this research. ChatGPT's recommendation confirmed my initial thoughts. My interpretation is that even if ChatGPT cannot provide an exact solution, it can offer useful ideas. Ultimately, it is up to your experience to decide which recommendations to pursue.
Let's go back to Oracle DB and check with the real SQL Tuning Advisor. It suggests a different (and supposedly better) execution plan hash value, 3165773248, but without any new index recommendations. Therefore, we may need to take advantage of both ChatGPT's advice and the Oracle SQL Tuning Advisor here.
SQL> set long 65536 set longchunksize 65536 set linesize 100 select dbms_sqltune.report_tuning_task('TEST_sql_tuning_task') from dual;SQL> SQL> SQL> DBMS_SQLTUNE.REPORT_TUNING_TASK('TEST_SQL_TUNING_TASK') ---------------------------------------------------------------------------------------------------- GENERAL INFORMATION SECTION ------------------------------------------------------------------------------- Tuning Task Name : TEST_sql_tuning_task Tuning Task Owner : SYS Workload Type : Single SQL Statement Scope : COMPREHENSIVE Time Limit(seconds): 60 Completion Status : COMPLETED Started at : 07/08/2023 15:34:24 Completed at : 07/08/2023 15:34:38 ------------------------------------------------------------------------------- FINDINGS SECTION (1 finding) ------------------------------------------------------------------------------- 1- SQL Profile Finding (see explain plans section below) DBMS_SQLTUNE.REPORT_TUNING_TASK('TEST_SQL_TUNING_TASK') ---------------------------------------------------------------------------------------------------- -------------------------------------------------------- A potentially better execution plan was found for this statement. Recommendation (estimated benefit: 99.99%) ------------------------------------------ - Consider accepting the recommended SQL profile. execute dbms_sqltune.accept_sql_profile(task_name => 'TEST_sql_tuning_task', task_owner => 'SYS', replace => TRUE);.........2- Using SQL Profile -------------------- Plan hash value: 3165773248 ---------------------------------------------------------------------------------------------------- ---------------- | Id | Operation | Name | Rows | Bytes | Cost (% CPU)| Time | ---------------------------------------------------------------------------------------------------- ---------------- DBMS_SQLTUNE.REPORT_TUNING_TASK('TEST_SQL_TUNING_TASK') ---------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 476 | 55 (2)| 00:00:01 | | 1 | SORT ORDER BY | | 1 | 476 | 55 (2)| 00:00:01 | |* 2 | FILTER | | | | | | | 3 | NESTED LOOPS SEMI | | 1 | 476 | 54 (0)| 00:00:01 | | 4 | NESTED LOOPS | | 1 | 469 | 53 (0)| 00:00:01 | |* 5 | TABLE ACCESS BY INDEX ROWID BATCHED| GL_JE_HEADERS | 13 | 3081 | 14 DBMS_SQLTUNE.REPORT_TUNING_TASK('TEST_SQL_TUNING_TASK') ---------------------------------------------------------------------------------------------------- (0)| 00:00:01 | |* 6 | INDEX RANGE SCAN | GL_JE_HEADERS_U2 | 13 | | 5 (0)| 00:00:01 | |* 7 | TABLE ACCESS BY INDEX ROWID | GL_JE_BATCHES | 1 | 232 | 3 (0)| 00:00:01 | |* 8 | INDEX UNIQUE SCAN | GL_JE_BATCHES_U1 | 1 | | 2 (0)| 00:00:01 | |* 9 | INDEX RANGE SCAN | GL_ACCESS_SET_LEDGERS_U1 | 1 | 7 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------------- ----------------
Troubleshoot ORA- Errors with ChatGPT
In this part, I will look for quick advice about an Oracle error, “ORA-01031: insufficient privileges while executing "EXECUTE DBMS_LOGMNR.START_LOGMNR”. It looks like just a grant issue, but it's a bit tricky.
First, I checked the Oracle Support knowledge base and pasted the same error, clicked on the first document, and returned “Execution of Dbms_logmnr fails with ORA-01031 (Doc ID 1676045.1)”.
Oracle document advice was:
“It is necessary to grant LOGMINING to the user to use EXECUTE DBMS_LOGMNR.START_LOGMNR”
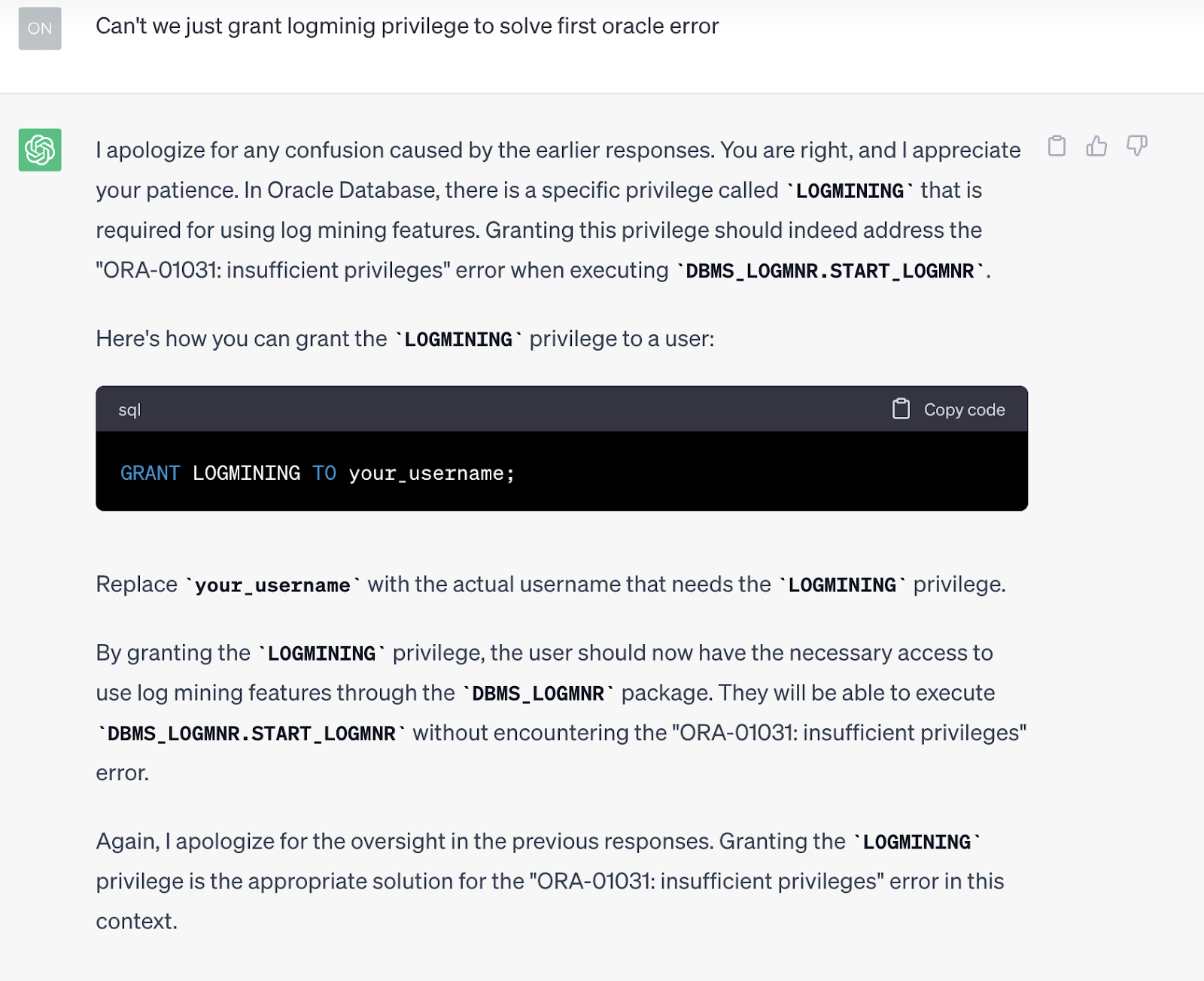
And points below code, we know that LOGMINING privilege is the ultimate answer.
SQL> grant LOGMINING to user;
If we ask ChatGPT from below the chat flow, we can see the first response; although it mentions LOGMINING privilege, the given code doesn’t include it.
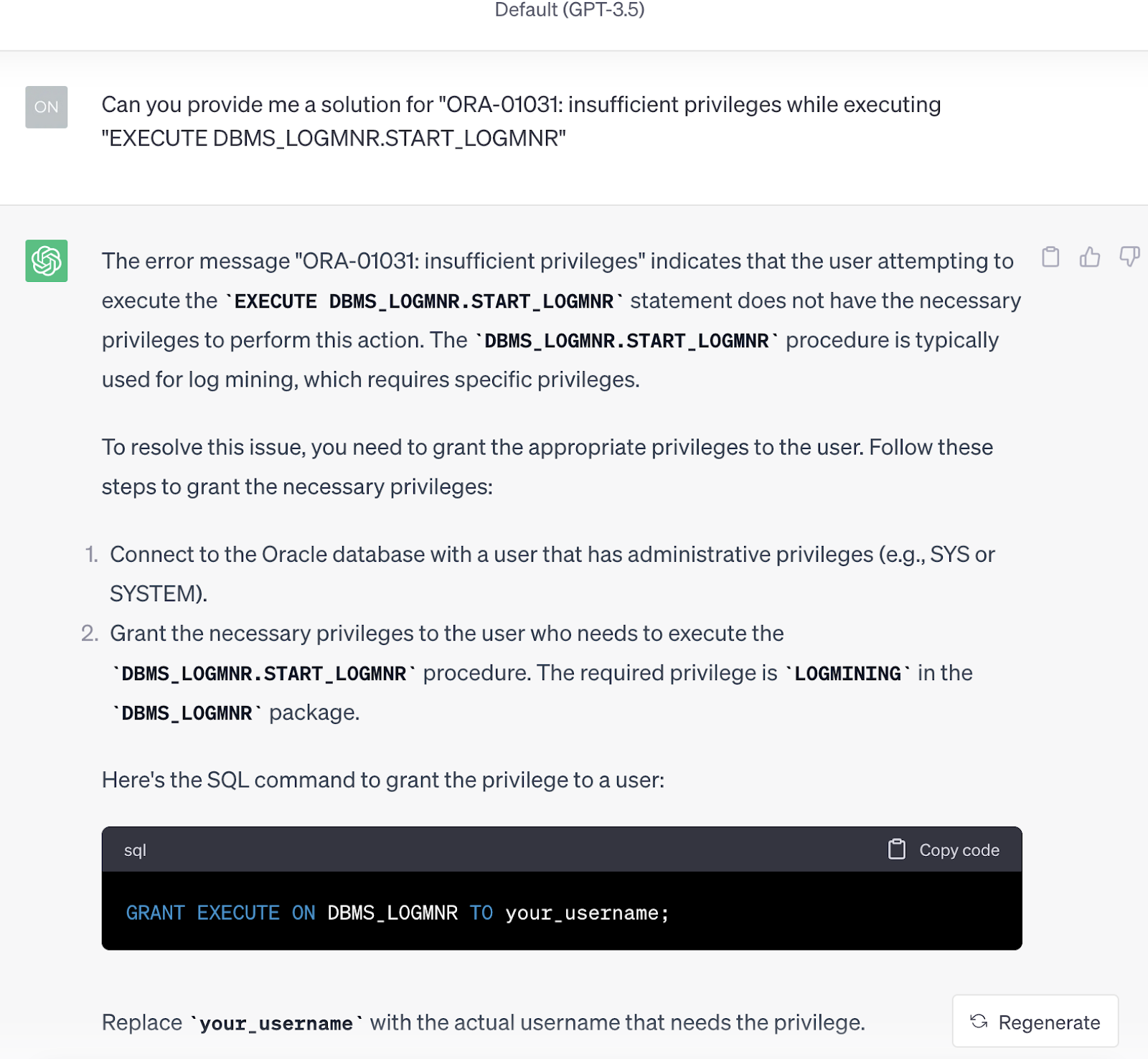
Below, I tried to redirect ChatGPT to the right answer, but it seemed confusing; it apologized and offered “SELECT_CATALOG_ROLE” privilege. Well, this privilege might help in querying some dictionary views, but it certainly won’t solve the specific ORA-01031 issue. Please see the chat flow below.
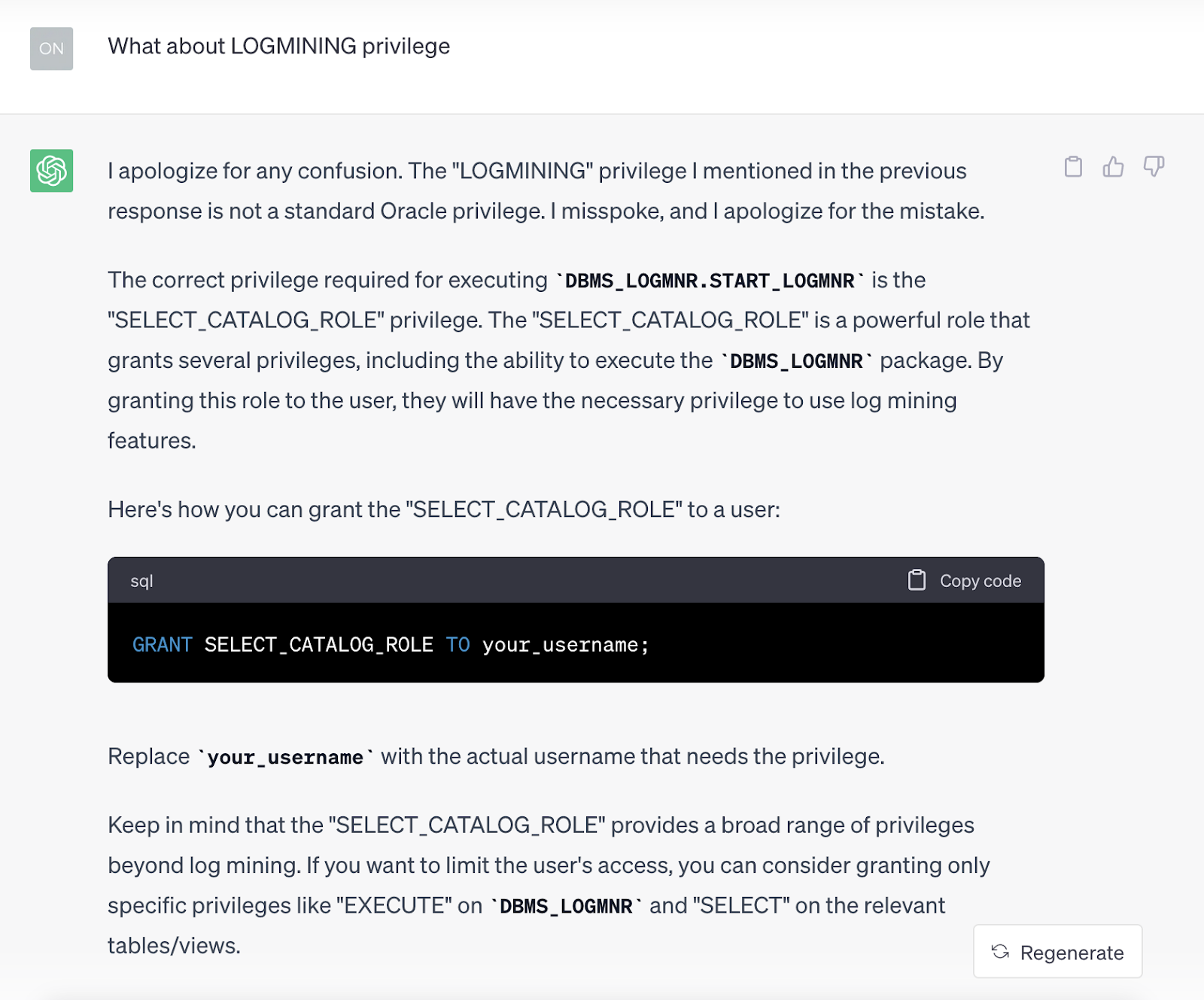
In the end, I decided to ask for a solution provided by the Oracle Support document, which was granted only “LOGMINING” privilege instead of anything else advised by ChatGPT. Well, it apologized again and accepted my redirection. This privilege issue was a bit tricky; ChatGPT might help on generic ORA issues, but it definitely needs validation from official documents and your experience.
Summary
- ChatGPT (3.5) is not a trusted advisor; it can be a copilot, but you still hold the steering wheel.
- ChatCPT is hesitant to give exact values and numbers while providing a solution, but you can enforce it.
- As an Oracle DBA, you can still get ideas to do your own research. ChatGPT is like your white collar, but a mid-level one.
- Relax, as ChatGPT can’t replace an expert DBA consultant job like after the autonomous database release, but this doesn’t mean it won’t.
Share this
Share this
Stabilize Oracle 10G's Bind Peeking Behaviour

Slow query to V$ views after DBRU Patching
