Share this
by Shashi Kumar on Aug 25, 2022 12:00:00 AM
Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines. It’s a software development kit (SDK) to define and construct data processing pipelines as well as runners to execute them.
Why Apache Beam?
- Apache Beam handles both batch and streaming data processing applications. It is easy to change stream processing to batch processing or vice versa.
- Apache Beam provides flexibility. Presently there are Java, Python, Golang SDKs available for Apache Beam. We can use any comfortable language of our choice.
- Apache Beam provides portability. The pipeline runners translate the data processing pipeline into the API compatible with the backend of the user’s choice. Currently, these distributed processing backends are supported by
- Apache Flink
- Apache Nemo
- Apache Samza
- Apache Spark
- Google Cloud Dataflow
- Hazelcast Jet
Capability Matrix
The Capability Matrix is trying to say the capabilities of individual runners and also provides a high level view of each runner which supports the Beam model.
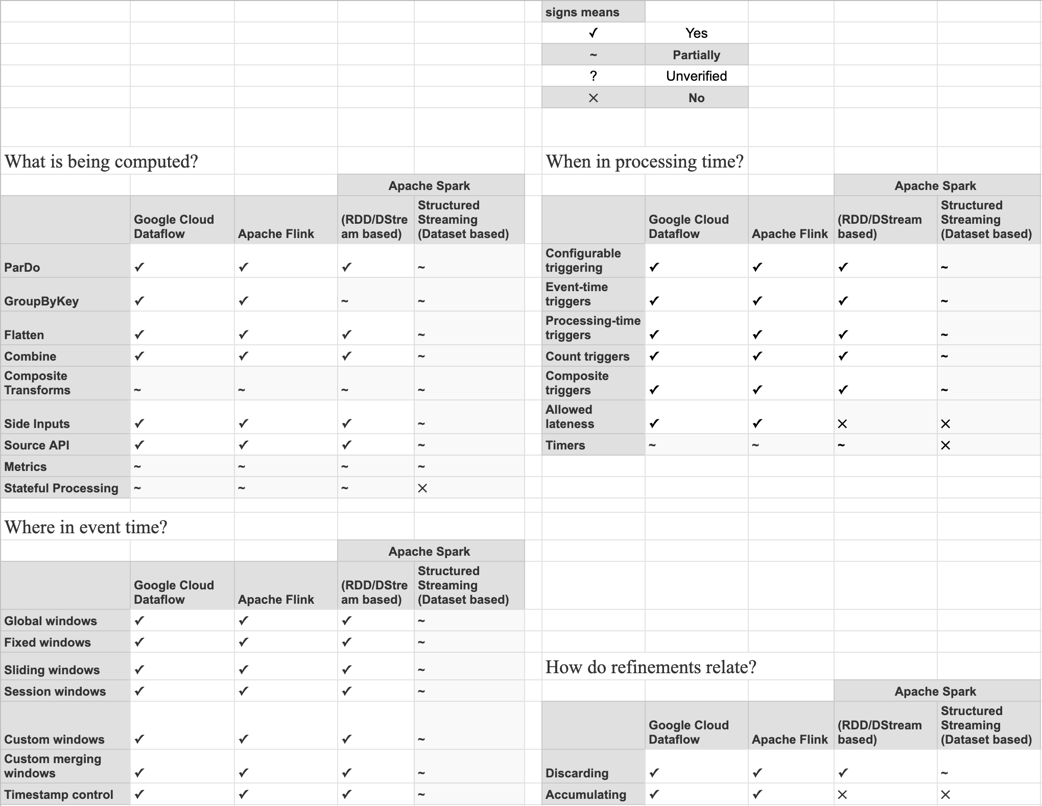
Based on the capability matrix, the user can decide which runner suits his use case.
Case Studies
In the official website, as mentioned there are many use cases with Apache Beam for the reference:
Few details of interesting case studies :
- Real time Machine learning pipelines where it continuous training of ML models with real-time data over windows of desired time frame.
- Real-time feature computation and model executions. Processing events in real-time with a sub-second latency allows our ML models to understand marketplace.
- Using Beam Implementing search engine’s experience of scaling the on-premises infrastructure to learn more about the benefits of byte-based data shuffling and the use cases where Apache Beam portability and abstraction bring the utmost value.
Fundamental Concepts
The key concepts in the programming model are:
- Pipeline – A pipeline is a user-constructed graph(DAG) of transformations that defines the desired data processing operations.It is a combination of a PCollection and a PTransform. Also we can say it will have entire data processing tasks from start to end.
- PCollection – A PCollection is an unordered bag of elements. Each PCollection is a potentially distributed, homogeneous data set or data stream, and is owned by the specific Pipeline. The data set can be either bounded or unbounded.
- PTransform – A PTransform (or transform) represents a data processing operation, or a step, in your pipeline. A transform is applied to zero or more PCollection objects, and produces zero or more PCollection objects.
- PipelineRunner – A runner runs a Beam pipeline using the capabilities of your chosen data processing engine. Most runners are translators or adapters to massively parallel big-data processing systems, such as Direct Runner, Apache Spark or Apache Flink etc.
Simply we can say PipelineRunner executes a Pipeline and a Pipeline consists of PCollection and PTransform.
Understanding of Beam model with examples
Let’s start creating Beam pipelines using Python and Colab. The main focus is batch processing in this blog.
Google Colaboratory (Colab) is a free Jupyter notebook interactive development environment that runs entirely in the cloud.
The initial setup in Colab for running Beam pipelines, go to the new notebook and install apache beam by running the following command in notebook.
!{'pip install apache_beam'}
!{'pip install apache-beam[interactive]'}
![]()
Creating directories and listing in the machine.

Uploading files from local.
from google.colab import files upload = files.upload()
Create a transform example
Source transforms is one of the transform types and it has TextIO.Read and Create. A source transform conceptually has no input.
In the below code we are passing list of elements for creating a Pcollection and writing to text file.
import apache_beam as beam
p3 = beam.Pipeline()
lines1 = (p3
| beam.Create([100,101,102,103,104,105,106,107,108,109])
| beam.io.WriteToText('output/file2')
)
p3.run()
Output: Result of the above program

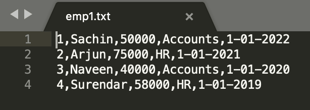
Sample data used for the below examples
- Schema : id,empname, salary, department, dateofJoining
Map/Filter transforms example:
Here we will be fetching the HR department employee count using Map /Filter transformation.
import apache_beam as beam
p1 = beam.Pipeline()
emp_count = (
p1
|beam.io.ReadFromText('emp1.txt')
|beam.Map(lambda record: record.split(','))
|beam.Filter(lambda record: record[3] == 'HR')
|beam.Map(lambda record: (record[3], 1))
|beam.CombinePerKey(sum)
|beam.io.WriteToText('output/emp_output1')
)
p1.run()
Brief explanation of the Pipeline:
- Creating a Beam pipeline which comprises Ptransform and Pcollection.
- ReadFromText (Ptransform) transform returns a PCollection, which reads the text file and PCollection contains all lines from the file.
- Map transform splits the data wrt “,” and returns a list of “,” separated data. For better understanding I have commented and ran the above code and results shown below

- Filter transform is used for filtering data and here I have filtered HR records as Pcollection.

- Once again Map transform is used to map column 4 with appending 1 to it.

- CombinePerKey is used to combine the values wrt to each key. This is final result of the program.

Branching pipeline example:
Branching pipeline is used for running 2 or multiple tasks on the same data.
For better understanding, we are using the same sample data and also we are calculating department wise counts.
In the below code, we are trying to get count of employee in each department
import apache_beam as beam
p = beam.Pipeline()
input_collection = (
p
| "Read from text file" >> beam.io.ReadFromText('emp1.txt')
| "Splitting rows based on delimiters" >> beam.Map(lambda record: record.split(','))
)
accounts_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'Accounts')
| 'Pair each accounts with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Group and sum1' >> beam.CombinePerKey(sum)
#| 'Write the results of ACCOUNTS' >> beam.io.WriteToText('output/emp4')
)
hr_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'HR')
| 'Pair each HR with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Group and sum' >> beam.CombinePerKey(sum)
#| 'Write the results of HR' >> beam.io.WriteToText('output/emp5')
)
empcount = (
input_collection
| 'Pair each dept with 1' >> beam.Map(lambda record: ("ALL_Dept", 1))
| 'Group and sum2' >> beam.CombinePerKey(sum)
#| 'Write the results of all dept' >> beam.io.WriteToText('output/emp7')
)
output =(
(accounts_empcount,hr_empcount,empcount)
| beam.Flatten()
| beam.io.WriteToText('output/emp6')
)
p.run()
- Each operation can be labeled in the pipeline code which helps for debugging purposes especially when you have complex pipelines and where you’re using the same lines of code across the pipeline many times. Each label needs to be unique otherwise, Apache Beam will throw an error.
- In the input_collection Pcollection we are adding common pieces of code (functions) before branching the pipeline, so in this example we are reading data and splitting the data with respect to delimiter .
- In the hr_empcount : Pcollections we are counting the employees with respect to the HR department.

- Accounts_empcount : Pcollections we are counting the employees with respect to the Accounts department.

- empcount Pcollections : we are counting the employees with respect to the all department.

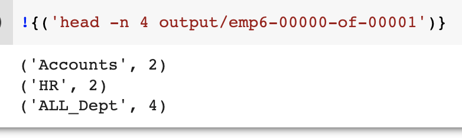
- output Pcollections : Results we got from the code as shown below.
ParDo Transform example:
- ParDo transform takes elements from input Pcollection, performs processing function on it and It can return zero, one, or multiple elements of different types .
- For the ParDo you need to provide the DoFn object. DoFn object is a Beam class that defines a distributed processing function.
- The DoFn class has a number of functions out of which we need to override process functions as per our requirement.
- In the below example we are trying to fetch the employee count of the Accounts department
- As mentioned above in the code for class SplitRow , FilterAccountsEmp, pairDept, empcount where we provide the DoFn object and override the process functions as per our requirement.
import apache_beam as beam
class SplitRow(beam.DoFn):
def process(self, element):
# return type -> list
return [element.split(',')]
class FilterAccountsEmp(beam.DoFn):
def process(self, element):
if element[3] == 'Accounts':
return [element]
class pairDept(beam.DoFn):
def process(self, element):
return [(element[3], 1)]
class empcount(beam.DoFn):
def process(self, element):
(key, values) = element # [Accounts , [1,1] ]
return [(key, sum(values))]
p1 = beam.Pipeline()
account_empcount = (
p1
|beam.io.ReadFromText('emp1.txt')
|beam.ParDo(SplitRow())
|beam.ParDo(FilterAccountsEmp())
|beam.ParDo(pairDept())
| 'Group ' >> beam.GroupByKey()
| 'Sum using ParDo' >> beam.ParDo(empcount())
|beam.io.WriteToText('output/file5')
)
p1.run()
Results we got from the code as shown below.

Composite transform example
- In composite transforms we do group multiple transforms as a single unit.
- In the below example we are creating a class called MyCompositeTransform and in this we need to inherit its corresponding base class and that is Beam.Ptransform.
- Ptransform is the base class of every Ptransform which we use So Ptransform has an expand method which needs to be overridden.
- This method takes a pcollection as input on which a number of transforms is going to be applied and returns the pcollection.
- To use this composite transform, call its object with its own unique tag.
- In the below example we’ll be counting the number of employee counts in each department.
import apache_beam as beam
def SplitRow(element):
return element.split(',')
class MyCompositeTransform(beam.PTransform):
def expand(self, input_coll):
a = (
input_coll
| 'Pair each respective department with 1' >> beam.Map(lambda record: (record[3], 1))
| 'Grouping & sum' >> beam.CombinePerKey(sum)
)
return a
p = beam.Pipeline()
input_collection = (
p
| "Read from text file" >> beam.io.ReadFromText('emp1.txt')
| "Splitting rows based on delimiters" >> beam.Map(SplitRow)
)
accounts_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'Accounts')
| 'accounts MyCompositeTransform' >> MyCompositeTransform()
)
hr_empcount = (
input_collection
| beam.Filter(lambda record: record[3] == 'HR')
| 'hr MyCompositeTransform' >> MyCompositeTransform()
)
output =(
(accounts_empcount,hr_empcount)
| beam.Flatten()
| beam.io.WriteToText('output/emp6')
)
p.run()
Results of the above code:

In this blog i have tried to explain batch processing using Beam Model, in the next blog we will try to cover stream processing using Beam Model.
Conclusion
Apache Beam is a powerful model for data-parallel processing for both streaming and batch. It is also portable and flexible.
The most capable runners at this point in time are clearly Google Cloud Dataflow (for running on GCP) and Apache Flink (for on-premise and non-Google cloud), as detailed by the capability matrix.
Can Apache Beam be the future of data processing? Share your thoughts in the comments and don’t forget to sign up for the next post.
No Comments Yet
Let us know what you think