MongoDB's
database profiler lets us collect some performance data about operations happening on a MongoDB instance. In this post, I will show you how we can enable the profiler, what kind of information it can store for us, how to query this information, and how using it may impact your database's performance. The MongoDB version used in these tests was
3.2.4. While not the latest, I found no reference to improvements or fixes to the profiler in more recent releases. Finally, I'll briefly discuss a couple of alternatives to reduce or eliminate the impact, while still gaining some insight into your MongoDB workload. I want to thank my colleague, Igor Donchovski, for his valuable input while reviewing this post.
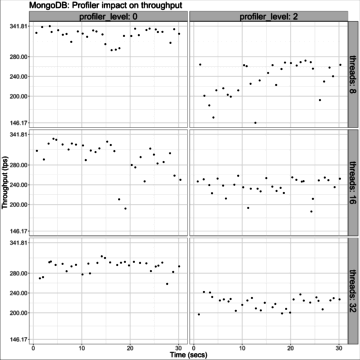 The graph shows that, when logging all operations, profiler impact is not minimal. It would be interesting to see how this sustains over time (for example, by leaving the workload running for several hours), to see if anything noteworthy happens when the profiler cap is reached. For this post, it is enough to say that the manual may be overly optimistic on its assessment of the profiler's impact. I used
pt-pmp to take some aggregated stack traces during the 32 threads runs, and it seems the negative impact could be due to lock contention on the system.profile collection: Here we can see the aggregated stack traces when running with profiler level 0:
The graph shows that, when logging all operations, profiler impact is not minimal. It would be interesting to see how this sustains over time (for example, by leaving the workload running for several hours), to see if anything noteworthy happens when the profiler cap is reached. For this post, it is enough to say that the manual may be overly optimistic on its assessment of the profiler's impact. I used
pt-pmp to take some aggregated stack traces during the 32 threads runs, and it seems the negative impact could be due to lock contention on the system.profile collection: Here we can see the aggregated stack traces when running with profiler level 0:
Enabling the profiler
The profiler can be enabled on a per-database or per-instance basis, and its work is controlled by the Profiling Level we choose. We'll only show the per-database approach, as using the profiler for an entire instance is described by the manual as something one would do on development or testing environments. I suspect this may be due to the impact the profiler may have on performance, something we'll discuss later on this post. Let's say I have a metrics database on my MongoDB instance. To enable profiling for it, I need to execute the following command from the mongo shell:> use metrics
switched to db metrics
> db.setProfilingLevel(1, 50)
{ "was" : 0, "slowms" : 100, "ok" : 1 }
This sets the profiling level for the
metrics database to 1, which means
'log all operations that take more than slowms milliseconds to execute', and at the same time, sets
slowms to 50. This will create a
system.profile
capped collection on the
metrics database, and will write into it performance data about operations on the
metrics database that exceed 50 milliseconds to run. If we want to log all operations instead, we just need to set the profiling level to 2:
> db.setProfilingLevel(2)
{ "was" : 1, "slowms" : 50, "ok" : 1 }
We can see this in action here:
> db.metrics01.insert({device_id: 104935, temp: 28.4})
WriteResult({ "nInserted" : 1 })
> db.metrics01.insert({device_id: 104935, temp: 28.1})
WriteResult({ "nInserted" : 1 })
> db.system.profile.find()
{ "op" : "insert", "ns" : "metrics.metrics01", "query" : { "insert" : "metrics01", "documents" : [ { "_id" : ObjectId("58ac8fbdbac007479c598a16"), "device_id" : 104935, "temp" : 28.4 } ], "ordered" : true }, "ninserted" : 1, "keysInserted" : 1, "numYield" : 0, "locks" : { "Global" : { "acquireCount" : { "r" : NumberLong(1), "w" : NumberLong(1) } }, "Database" : { "acquireCount" : { "w" : NumberLong(1) } }, "Collection" : { "acquireCount" : { "w" : NumberLong(1) } } }, "responseLength" : 29, "protocol" : "op_command", "millis" : 0, "ts" : ISODate("2017-02-21T19:06:37.097Z"), "client" : "127.0.0.1", "appName" : "MongoDB Shell", "allUsers" : [ ], "user" : "" }
{ "op" : "insert", "ns" : "metrics.metrics01", "query" : { "insert" : "metrics01", "documents" : [ { "_id" : ObjectId("58ac8fbfbac007479c598a17"), "device_id" : 104935, "temp" : 28.1 } ], "ordered" : true }, "ninserted" : 1, "keysInserted" : 1, "numYield" : 0, "locks" : { "Global" : { "acquireCount" : { "r" : NumberLong(1), "w" : NumberLong(1) } }, "Database" : { "acquireCount" : { "w" : NumberLong(1) } }, "Collection" : { "acquireCount" : { "w" : NumberLong(1) } } }, "responseLength" : 29, "protocol" : "op_command", "millis" : 0, "ts" : ISODate("2017-02-21T19:06:39.682Z"), "client" : "127.0.0.1", "appName" : "MongoDB Shell", "allUsers" : [ ], "user" : "" }
It is important to mention that MongoDB also writes all operations that take more than slowms milliseconds to run to the mongod.log file, regardless of profiler level. Additionally, if the profiler level is 2, all operations are written both to the system.profile collection and to the log file.
What the profiler tells us
To see what kind of information we can get by using the database profiler, let's query a single entry, and pretty print it while we're at it:> db.system.profile.find().limit(1).pretty()
{
"op" : "insert",
"ns" : "metrics.metrics01",
"query" : {
"insert" : "metrics01",
"documents" : [
{
"_id" : ObjectId("58ac8fbdbac007479c598a16"),
"device_id" : 104935,
"temp" : 28.4
}
],
"ordered" : true
},
"ninserted" : 1,
"keysInserted" : 1,
"numYield" : 0,
"locks" : {
"Global" : {
"acquireCount" : {
"r" : NumberLong(1),
"w" : NumberLong(1)
}
},
"Database" : {
"acquireCount" : {
"w" : NumberLong(1)
}
},
"Collection" : {
"acquireCount" : {
"w" : NumberLong(1)
}
}
},
"responseLength" : 29,
"protocol" : "op_command",
"millis" : 0,
"ts" : ISODate("2017-02-21T19:06:37.097Z"),
"client" : "127.0.0.1",
"appName" : "MongoDB Shell",
"allUsers" : [ ],
"user" : ""
}
We can see that each profiler document contains useful information about an operation. The manual provides a description in
this page. Here are a couple of things to take into consideration:
- The 'query', 'command' and 'updateobj' fields will be truncated if the corresponding document exceeds 50kb.
- the 'millis' field is supposed to be the "time in milliseconds from the perspective of mongod from the beginning of the operation to the end of the operation" (quoting the manual), yet I have found that for very fast operations, a 0 will be displayed even if it takes more than 0 milliseconds. So watch out for potential resolution problems. This could be dependent on the target architecture (I tried this on CentOS running on VirtualBox running on macOS, YMMV), but it is something to take into consideration if you intend to rely on this data point for decision-making. I have obtained more accurate results by measuring response time by sniffing the network.
Impact on performance
The manual states that the profiler has a minor effect on performance, but in some basic tests (sysbench oltp) I have observed a noticeable impact on throughput when the profiler is enabled and configured to log all operations. The following graph shows throughput (in transactions per seconds, in the context of MongoDB, sysbench transactions are just a sequence of operations) over time (in seconds) for varying concurrency levels (client threads) and with profiler level set to 0 (profiler disabled) and 2 (profiler enabled and logging all operations): The graph shows that, when logging all operations, profiler impact is not minimal. It would be interesting to see how this sustains over time (for example, by leaving the workload running for several hours), to see if anything noteworthy happens when the profiler cap is reached. For this post, it is enough to say that the manual may be overly optimistic on its assessment of the profiler's impact. I used
pt-pmp to take some aggregated stack traces during the 32 threads runs, and it seems the negative impact could be due to lock contention on the system.profile collection: Here we can see the aggregated stack traces when running with profiler level 0:
Tue Feb 21 14:05:03 UTC 2017
4 pthread_cond_timedwait,__wt_cond_wait_signal,__wt_cond_auto_wait_signal,__wt_cond_auto_wait,__wt_evict_thread_run,__wt_thread_run,start_thread(libpthread.so.0),clone(libc.so.6)
1 sigwait(libpthread.so.0),mongo::::signalProcessingThread,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 select(libc.so.6),mongo::Listener::initAndListen,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_wait,std::condition_variable::wait,mongo::waitForShutdown,mongo::::_initAndListen,main
1 pthread_cond_wait,std::condition_variable::wait,mongo::DeadlineMonitor::deadlineMonitorThread,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__wt_cond_auto_wait_signal,__wt_cond_auto_wait,__log_wrlsn_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__wt_cond_auto_wait_signal,__log_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__sweep_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__log_file_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__ckpt_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,std::thread::_Impl::_M_run,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::RangeDeleter::doWork,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::::PeriodicTaskRunner::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::FTDCController::doLoop,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepsecs,mongo::TTLMonitor::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepsecs,mongo::ClientCursorMonitor::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepmillis,mongo::WiredTigerKVEngine::WiredTigerJournalFlusher::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
Versus the same when profiler level is 2:
Tue Feb 21 14:05:46 UTC 2017
24 pthread_cond_timedwait,mongo::CondVarLockGrantNotification::wait,mongo::LockerImpl::lockComplete,mongo::Lock::ResourceLock::lock,mongo::Collection::_insertDocuments,mongo::Collection::insertDocuments,mongo::Collection::insertDocument,mongo::profile,mongo::assembleResponse,mongo::ServiceEntryPointMongod::_sessionLoop,std::_Function_handler::_M_invoke,mongo::::runFunc,start_thread(libpthread.so.0),clone(libc.so.6)
8 pthread_cond_timedwait,mongo::CondVarLockGrantNotification::wait,mongo::LockerImpl::lockComplete,mongo::Lock::ResourceLock::lock,mongo::Collection::_insertDocuments,mongo::Collection::insertDocuments,mongo::Collection::insertDocument,mongo::profile,mongo::::finishCurOp[clone.prop.247],mongo::performUpdates,mongo::CmdUpdate::runImpl,mongo::::WriteCommand::run,mongo::Command::run,mongo::Command::execCommand,mongo::runCommands,mongo::::receivedCommand[clone.isra.110][clone.prop.124],mongo::assembleResponse,mongo::ServiceEntryPointMongod::_sessionLoop,std::_Function_handler::_M_invoke,mongo::::runFunc,start_thread(libpthread.so.0),clone(libc.so.6)
4 pthread_cond_timedwait,__wt_cond_wait_signal,__wt_cond_auto_wait_signal,__wt_cond_auto_wait,__wt_evict_thread_run,__wt_thread_run,start_thread(libpthread.so.0),clone(libc.so.6)
1 sigwait(libpthread.so.0),mongo::::signalProcessingThread,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 select(libc.so.6),mongo::Listener::initAndListen,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 sched_yield(libc.so.6),__log_wrlsn_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_wait,std::condition_variable::wait,mongo::waitForShutdown,mongo::::_initAndListen,main
1 pthread_cond_wait,std::condition_variable::wait,mongo::DeadlineMonitor::deadlineMonitorThread,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__wt_cond_auto_wait_signal,__log_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__sweep_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__log_file_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,__wt_cond_wait_signal,__ckpt_server,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,std::thread::_Impl::_M_run,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::RangeDeleter::doWork,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::::PeriodicTaskRunner::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 pthread_cond_timedwait,mongo::FTDCController::doLoop,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepsecs,mongo::TTLMonitor::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepsecs,mongo::ClientCursorMonitor::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
1 nanosleep(libpthread.so.0),mongo::sleepmillis,mongo::WiredTigerKVEngine::WiredTigerJournalFlusher::run,mongo::BackgroundJob::jobBody,execute_native_thread_routine,start_thread(libpthread.so.0),clone(libc.so.6)
I suspect this locking is in place so that writing to the profiler is safe even when mmapv2 is the storage engine in use, but I plan to dig deeper into this and publish my results in another post. It's important to highlight that while the machine used to run these tests has a single disk (a consumer grade SSD), I/O was not the bottleneck, with a maximum utilization of 4% for the tests, regardless of the profile level used. Again, for the time being, the takeaway message is that the profiler does not come for free (what does?), so you should test its impact on your workload and hardware before using it in production.
Alternatives
Currently, I can think of two alternatives to MongoDB's database profiler that either reduce or eliminate its performance impact. One is to use Percona Server for MongoDB, which provides a rate limiting feature for the profiler. This is similar to the rate limit feature Percona implemented for MySQL, so it gives us a way to log all the operations but only for a subset of the sessions. I have not measured how this reduces the performance impact yet, but expect it to at least make the profiler more usable in 'full capture' mode. The second one is to use VividCortex, which lets you monitor a MongoDB workload by sniffing packets. This eliminates the profiler impact, and has the added benefit that you get more accurate response time data than what the profiler gives us (at least at the moment). On the other hand, the 'what does come for free?' question applies here too, as this is not open source software.Conclusion
MongoDB's database profiler can be a useful tool to gain insight into a MongoDB workload, but proper testing should be performed before using it in production to capture all traffic, as its impact on performance is not negligible. Some alternatives (both Open Source and Proprietary) exist, that can mitigate or eliminate the profiler's performance impact, and we can also hope that the overhead will be reduced in future MongoDB releases.On this page
Share this
Share this
Linux Patching and Oracle: Detect RPM conflicts before they happen
![]()
Linux Patching and Oracle: Detect RPM conflicts before they happen
Nov 15, 2011 12:00:00 AM
9
min read
How To Improve SQL Statements Performance: Using SQL Plan Baselines
![]()
How To Improve SQL Statements Performance: Using SQL Plan Baselines
Feb 3, 2014 12:00:00 AM
6
min read
How to find unused indexes and drop them safely in MongoDB
![]()
How to find unused indexes and drop them safely in MongoDB
Sep 27, 2018 12:00:00 AM
2
min read