In this article, we'll cover the functionality available in SQL Server 2014 for textual research known as Full-Text Search, its installation and implementation. Additionally, we will see how to develop textual searches using the predicates CONTAINS, CONTAINSTABLE, FREETEXT and FREETEXTTABLE, and use the FILESTREAM feature to improve the research and storage of binary data in tables. The research based on words and phrases is one of the main features of the search tools on the web, like Google, and digital document management systems. To perform these searches efficiently, many developers create highly complex applications that do not have the necessary intelligence to find terms and phrases in the columns that store text and digital documents in the database tables. What the vast majority of these professionals don't know is that SQL Server has an advanced tool for textual research, the
Full-Text Search (FTS). FTS has been present in SQL Server since version 7, and through use textual searches can be performed both in columns that store characters, and in columns that store documents (for example, Office documents and PDFs), in its native form. With options like searches for words and phrases, recognition of different languages, derivation of words (for example: play, played and playing), the possibility of developing a thesaurus, the creation of ranked results, and elimination of stopwords for search, FTS becomes a powerful tool for textual searches. As main factors for the use of textual searches we have:
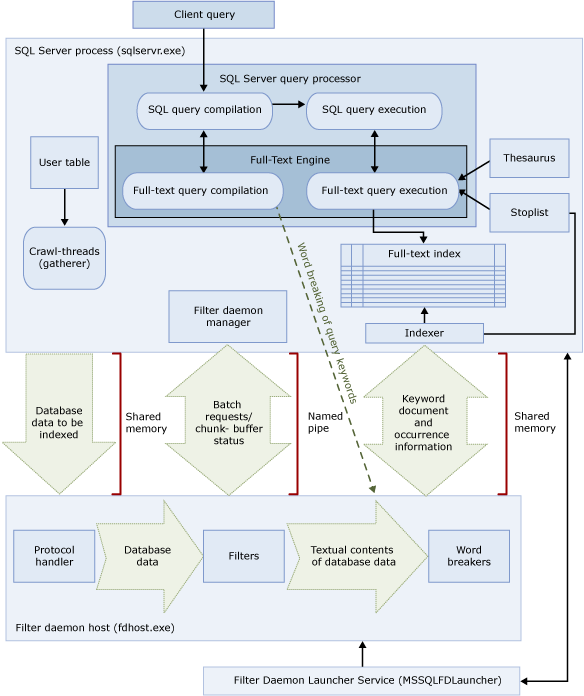 Figure 1. Architecture of FTS. For the better understanding of the process of creation, use and maintenance of the structure of full-text indexes, you must also know the meaning of some important concepts. They are:
Figure 1. Architecture of FTS. For the better understanding of the process of creation, use and maintenance of the structure of full-text indexes, you must also know the meaning of some important concepts. They are:
- The current databases are increasingly used as repositories of digital documents;
- The cost for storage of information has slowed considerably, enabling the storage of Gigabytes, Terabytes and even Petabytes;
- New types of digital documents are constantly being created, and the requirements for their storage, and subsequent research, are becoming larger and more complex;
- Developers need a robust and reliable interface for performing textual research intelligence.
- Textual research based on linguistics. A linguistic research is based on words or phrases in a particular language, taking into consideration the verb conjugation, derived words, accent, among other features. Unlike the LIKE predicate, FTS uses an efficient indexing structure to perform textual research;
- Automatic removal of stopwords informed in a textual research. The following are considered stopwords ones that don't add to the result of the survey, such as from, to, the, the, a, an;
- Assigning weights to the terms searched, making certain words are more important than others within the same textual research;
- Generation of prioritization, allowing a better view of the documents that are most relevant according to the research carried out;
- Indexing and searching in the most diverse types of digital documents. With FTS you can carry out searches in text files, spreadsheets, ZIP files, among others.
FTS architecture
The architecture of the FTS has several components working in conjunction with the SQL Server query processor to perform textual research efficiently. The Figure 1 illustrates the major components of the architecture of the FTS. Let's look at some of them:- Client Consultation: The client application sends the textual queries to the SQL Server query processor. It is the responsibility of the client application to ensure that the textual queries are written in the right way by following the syntax of FTS;
- SQL Server Process (sqlservr.exe): The SQL Server process contains the query processor and also the engine of the FTS, which compiles and executes the textual queries. The integration between SQL Server and process the FTS offers a significant performance boost because it allows the query processor lot more efficient execution plans for textual searches;
- SQL Server Query Processor: The query processor has multiple subcomponents that are responsible for validating the syntax, compile, generate execution plans and execute the SQL queries;
- Full-Text Engine: When the SQL Server query processor receives a query FTS, it forwards the request to the FTS Engine. The Engine is responsible for validating FTS the FTS query syntax, check the full-text index, and then work together with the SQL Server query processor to return the textual search results;
- Indexer: The indexer works in conjunction with other components to populate the full-text index;
- Full-Text Index: The full-text index contains the most relevant words and their respective positions within the columns included in the index;
- Stoplist: A stoplist is a list of stopwords for textual research. The indexer stoplist query during the indexing process and implementation of textual research to eliminate the words that don't add value to the survey. SQL Server 2014 stores the stoplists within the database itself, thus facilitating their administration;
- Thesaurus: The thesaurus is an XML file (stored externally to the database) in which you can define a list of synonyms that can be used for the textual research. The thesaurus must be based on the language that will be used in the search. The full-text engine reads the thesaurus file at the time of execution of research to verify the existence of synonyms that can increase the quality and comprehensiveness of the same;
- Filter daemon host (fdhost.exe): Is responsible for managing the processes of filtering, word breaker and stemmer;
- SQL Full-Text Filter Daemon Launcher (fdlauncher.exe): Is the process that starts the Filter daemon host (Fdhost.exe) when the full-text engine needs to use some of the processes managed by the same.
Figure 1. Architecture of FTS. For the better understanding of the process of creation, use and maintenance of the structure of full-text indexes, you must also know the meaning of some important concepts. They are:
- Term: The word, phrase or character used in textual research;
- Full-Text Catalog: A group of full-text indexes;
- Word breaker: The process that is the barrier every word in a sentence, based on the grammar rules of the language selected for the creation of full-text index;
- Token: A word, phrase or character defined by the word breaker;
- Stemmer: The process that generates different verb forms for the words, based on the grammar rules of the language selected for the creation of full-text index;
- Filter: Component responsible for extracting textual information from documents stored with the data type varbinary(max) and send this information to the process word breaker.
Indexing process
The indexing process is responsible for the initial population of a full-text index and update of this index when the data modifications occur on the columns that have been indexed by FTS. This initialization process and update the full-text index named crawl. When the crawl process is started, the FTS component known as protocol handler accesses the data in the table being indexed and begins the process to load into memory the existing content in this table, also known as streaming. To have access to data which are stored on disk, the protocol handler allows FTS to communicate with the Storage Engine. After the end of streaming the filter daemon host process performs data filtering, and initiates the processes of w ord breaker and stemmer for the filling in of the full-text index. During the indexing process the stoplist is queried to remove stopwords, and so fill the structure of the full-text index with words that are meaningful to the textual research. The last step of the indexing process is known as a master merge, in which every word indexed are grouped in a single full-text index. Despite the indexing process requires a high i/o consumption, it is not necessary to the blocking of the data being indexed. However a query performed using a full-text index during the indexing process can generate a result incomplete.Full-Text query processing
For the full-text query processing are used the same words and phrases limiters that were defined by the Word breaker during the indexing process. You can also use additional components, as for example, the stemmer and the thesaurus, depending on the full-text predicates ( CONTAINS or FREETEXT) used in the textual research. The use of full-text predicates will be discussed later in this article. The process stemmer generates inflectional forms of the searched words. For example, from the term "play" is searched also the terms "played", "play", "play" beyond the term itself "play". Through rules created in the thesaurus file you can use synonyms to replace or expand the searched terms. For example, when performing a textual search using the term "Ruby" , the full-text engine can replace it by the synonym "red", or else expand the research considering the terms automatically "red", "wine", "Scarlet" and also "Ruby". After processing of the full-text query, the full-text engine provides information to SQL query processor that assist in creating an execution plan optimized for textual research. There is a greater integration between the full-text engine and the query processor of SQL (both are components of the SQL Server process), enabling textual searches are conducted in a more optimized. In the next post of this 4 part series, we will learn how to install the FTS and how to use it. Stay tuned!Share this
The Value of AI Enterprise Search

The Value of AI Enterprise Search
Apr 15, 2025 9:03:40 AM
3
min read
What is Enterprise AI Search?

What is Enterprise AI Search?
Apr 28, 2025 4:35:24 PM
3
min read
Thoughts on Texas Cyber Summit 2023

Thoughts on Texas Cyber Summit 2023
Oct 2, 2023 9:14:04 AM
3
min read
No Comments Yet
Let us know what you think