 In the ever-evolving landscape of AI and Natural Language Processing, OpenAI's GPT models have emerged as a powerful tool for generating human-like text. Microsoft has built a strong partnership with OpenAI and has integrated their models into the Azure OpenAI service. This service includes hosting the models and extra capabilities like fine-tuning through the Azure AI Studio experience. GPT’s true flexibility shines with fine-tuning, where you can customise its behaviour for specific tasks.
In the ever-evolving landscape of AI and Natural Language Processing, OpenAI's GPT models have emerged as a powerful tool for generating human-like text. Microsoft has built a strong partnership with OpenAI and has integrated their models into the Azure OpenAI service. This service includes hosting the models and extra capabilities like fine-tuning through the Azure AI Studio experience. GPT’s true flexibility shines with fine-tuning, where you can customise its behaviour for specific tasks.
In this blog post, we'll explore a demo scenario and showcase the Azure OpenAI studio experience: training a parser with GPT-3.5 to generate structured JSON output from paragraphs. Now, this is a task that could obviously be accomplished with regular NLP computing and even with prompt engineering only, however, it is easy to understand and follow how we want the model to behave and will also give us an easy way to evaluate correctness.
The Use Case: Structured JSON from Text
Imagine a scenario where you need to extract specific information from paragraphs, such as subjects, verbs, sentence and word counts, and character counts. You want to create a parser with GPT that can effortlessly handle this task. Let’s see how we can do this easily with Azure’s OpenAI service by taking advantage of the “Build a custom model” functionality.
Defining the JSON Schema
The first step is to define the JSON schema for the structured output you desire. In our case, it includes:
- `subjects` (an array with the subjects of the sentences in the paragraph)
- `verbs` (an array with the verbs in the sentences in the paragraph)
- `sentence_count` (the number of sentences in the paragraph)
- `word_count` (the number of words in the paragraph)
- `character_count_whitespace` (number of characters in the paragraph, including whitespace)
- `character_count_no_whitespace` (number of characters in the paragraph without whitespace)
Creating Training Examples
Now, let's create training examples that follow the JSON schema. Each example is a conversation with a system message, user input, and assistant output. Here's a sample:
**** begin JSON code block *******
{
"messages": [
{
"role": "system",
"content": "This is a parser GPT. It should generate structured JSON output from a paragraph."
},
{
"role": "user",
"content": "Please parse the following paragraph and provide structured JSON output:"
},
{
"role": "user",
"content": "The quick brown fox jumps over the lazy dog. This is a simple example paragraph."
},
{
"role": "assistant",
"content": {
"subjects": ["fox", "dog", "This"],
"verbs": ["jumps", "is"],
"sentence_count": 2,
"word_count": 11,
"character_count_whitespace": 57,
"character_count_no_whitespace": 47
}
}
]
}
**** end of JSON code block *******
Fine-Tuning with Azure OpenAI
Here's where the magic happens. You can use Azure OpenAI's AI Studio to fine-tune your model with these training examples. The process can be done through the OpenAI API but doing it through the web portal is also extremely simple.
Once you have enough conversation examples, you need to provide your training dataset as a JSON Lines (JSONL) document. For gpt-35-turbo, the fine-tuning dataset must be formatted in the conversational format that is used by the Chat completions API like in the example above. The bare minimum is 10 examples for training, however, OpenAI recommends that you generate at least 50 different example interactions as part of your training and also save some (20%-30%) as validation examples to use later on once the model is trained.
In addition to the JSONL format, training and validation data files must be encoded in UTF-8 and include a byte-order mark (BOM). The file must be less than 100 MB in size but you shouldn’t really need so much text data if you’re fine tuning, remember we are trying to teach a new way to interact or respond, not trying to feed it new knowledge.
First, we upload the file to the “Data Files” section of the Azure AI Studio, this will make it available for custom model deployments.
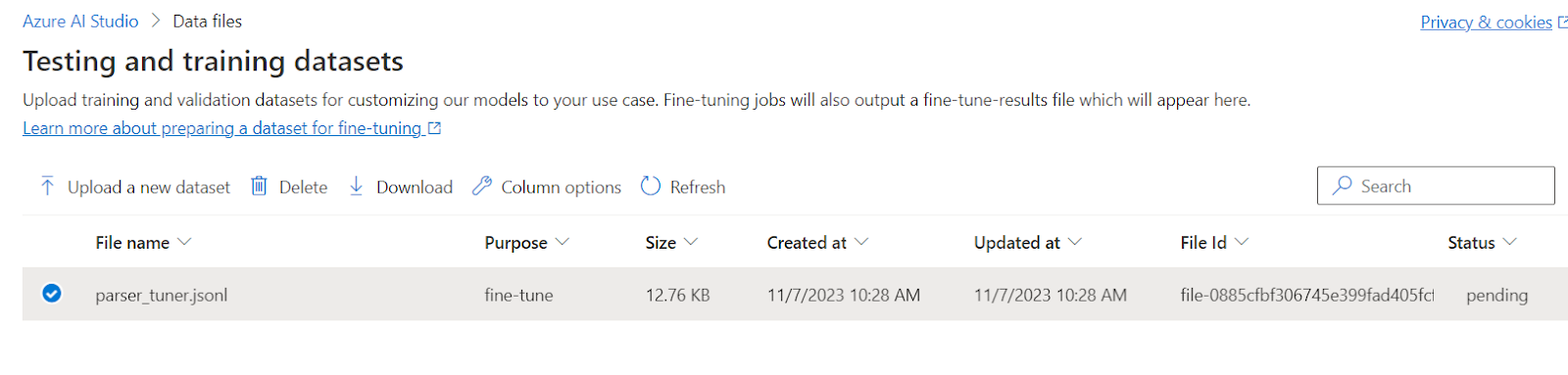
Once the file is uploaded, we can create a custom model on the “Models” page
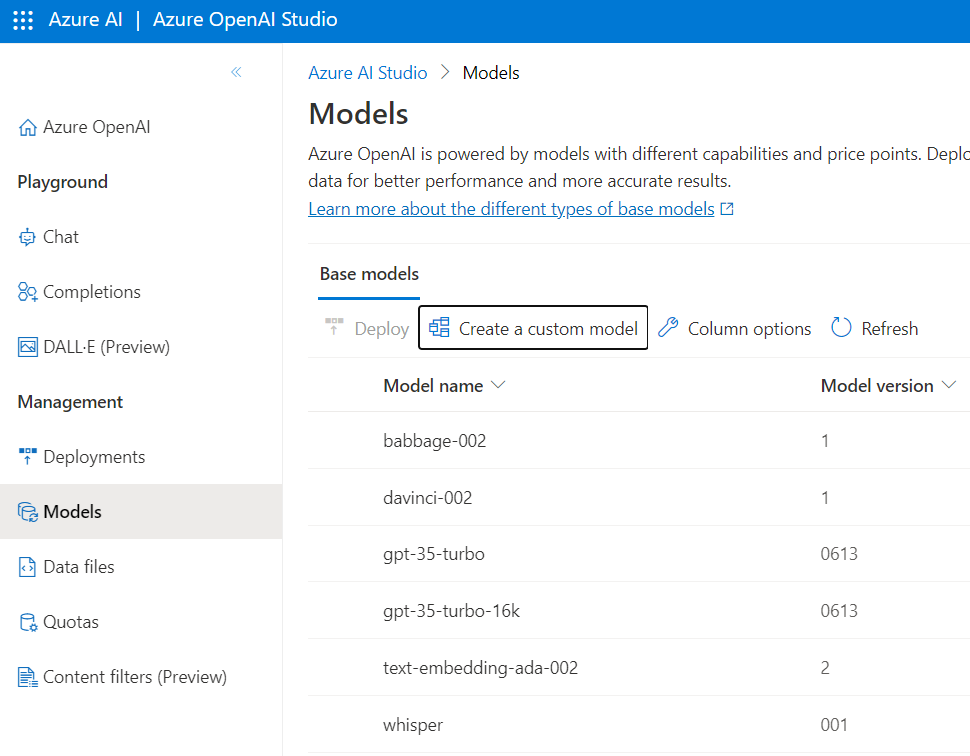
And then run through the steps to add training and validation data to the job. The validation data should be used for testing the results and should not overlap with the training examples.
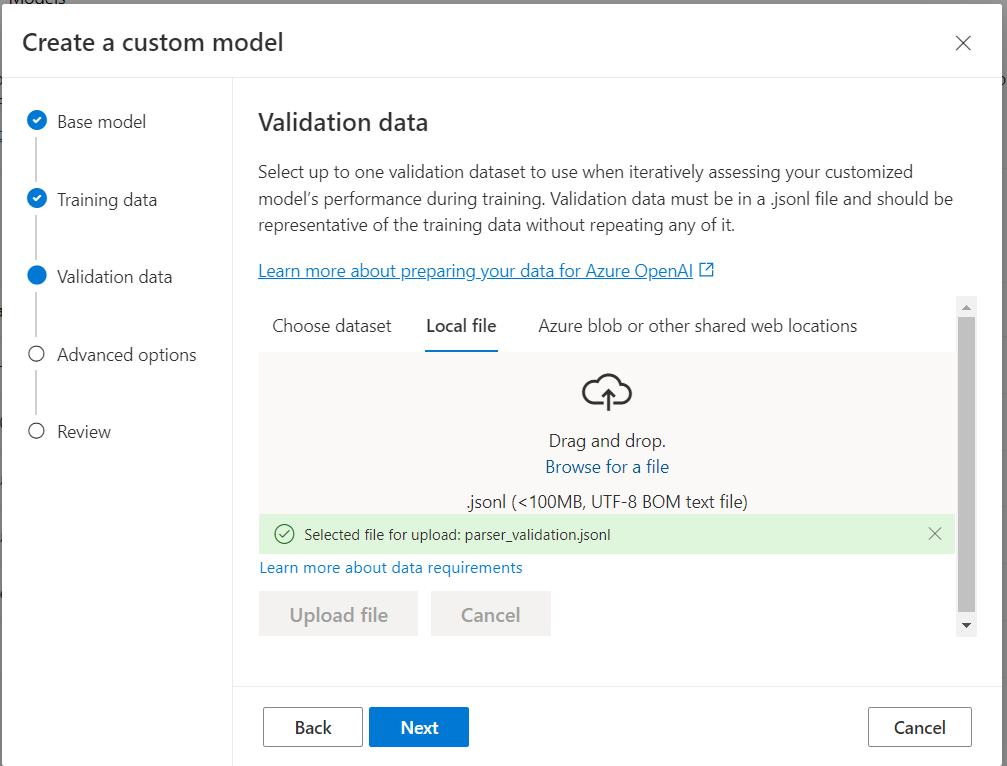
Finally, you can specify custom parameters, in this case it refers to adjusting the number of epochs of the training job. An epoch is one training cycle using the entire training dataset, you can set it as default used by the OpenAI API or specify a different number. The OpenAI API allows for two more hyperparameters: learning rate multiplier and batch size, however these are not exposed by the web portal so you have to use the defaults for these. If you want to read more about these, the official documentation is HERE.
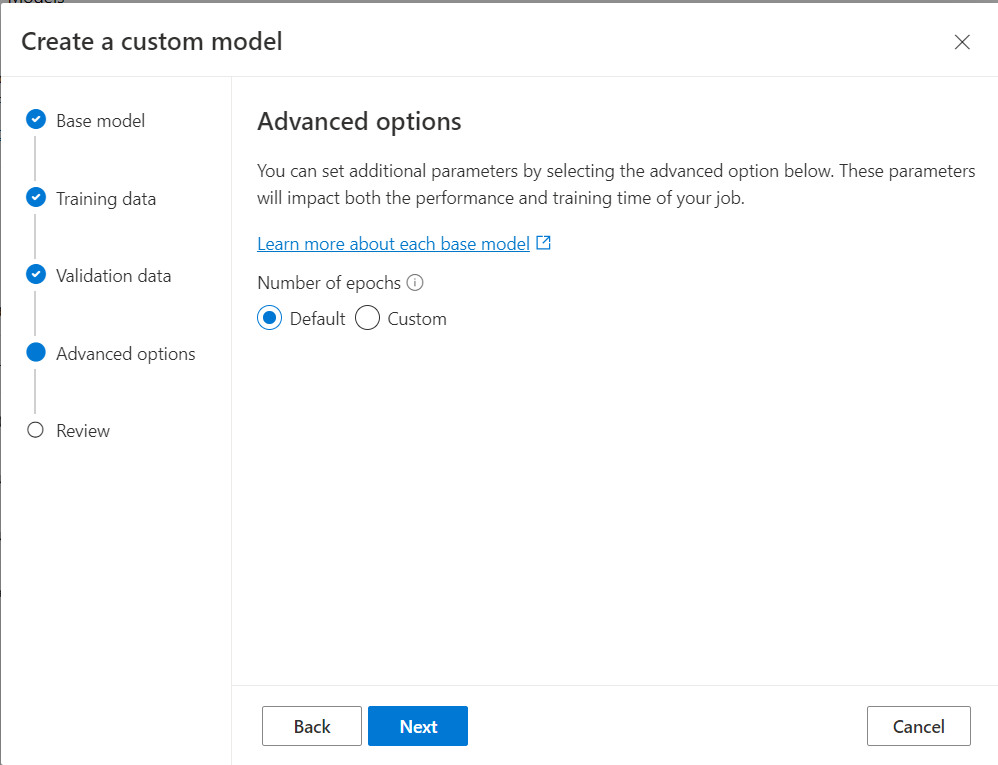
Once that’s done, the job will be kicked off and will start running the training session. This might take a while depending on how much training data you submitted for the job. While the job is running the “Deployable” column will say “No” since the model is not in a state where it can be deployed to run inference.
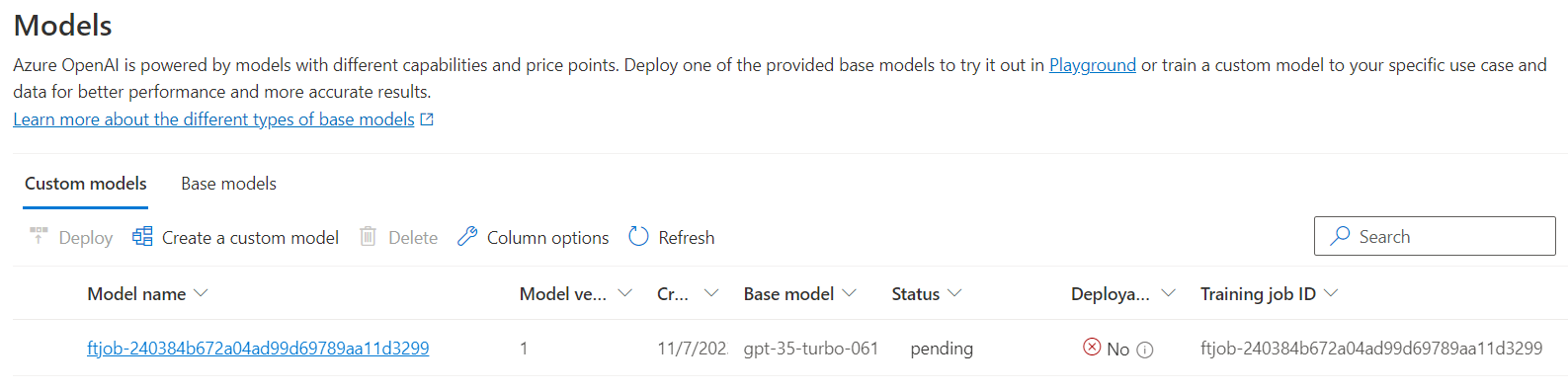
Once the job has completed, we can see our new custom model is available:
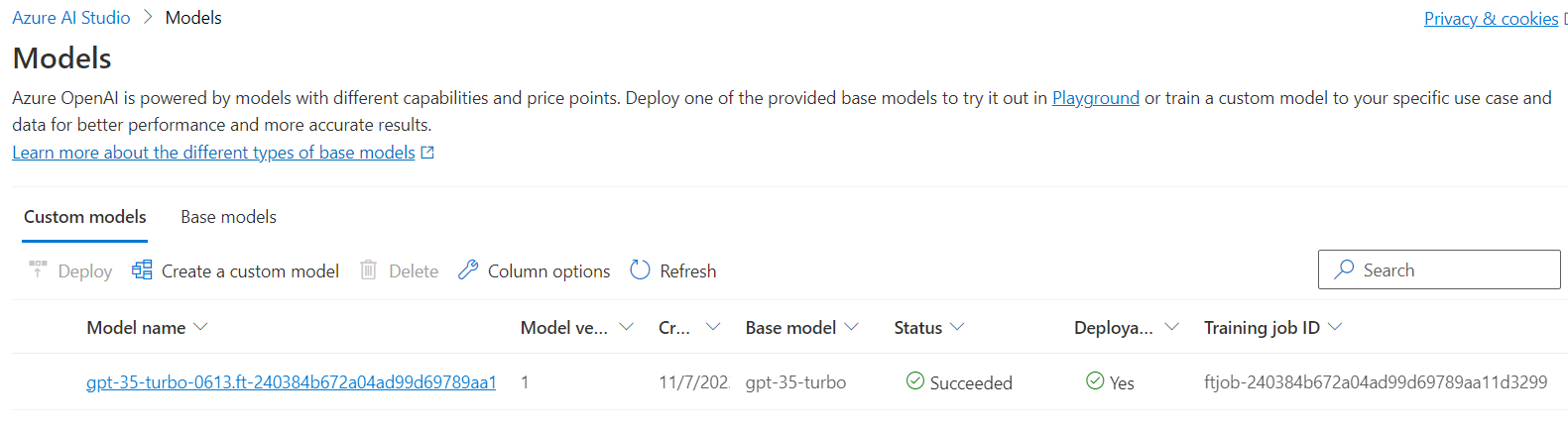
And now we can move forward with doing a deployment and testing it in the playground!
Evaluating the Model
After fine-tuning, it's crucial to evaluate the model's performance. You can test it with various paragraphs to ensure it generates accurate structured JSON outputs and it follows the behaviour we specified through our training examples. If needed, iterate and refine the training examples.
The Azure AI studio offers the chat playground as a very friendly way to simply interact with the custom model and test how it behaves during an interaction.

After being trained, the model outputs a similar JSON but it is not quite to the specification that we trained. The issue here is the size of the dataset as I only created about 15 examples and OpenAI documentation specifies attempting with at least 50. So homework for myself is to generate more training examples to then do another fine-tuning trial run.
If we had a larger training dataset then we would be able to get the exact JSON specification with less guidance from the system prompt and from the user having to specify the desired JSON schema every single time. This immediately translates into shorter conversations with less tokens which makes the interaction faster and more cost-effective.
When to Use Fine-Tuning versus Prompt Engineering
Fine-tuning offers several advantages over prompt engineering, especially when you require specific, structured outputs. While prompt engineering can be effective for simpler tasks, fine-tuning excels for:
- Complex Outputs: fine-tuning is ideal for tasks that demand structured, multifaceted responses, like JSON outputs from paragraphs.
- Custom Behaviour: you can tailor the model's behaviour to your exact requirements, defining specific output formats and content.
- Multimodal Tasks: for tasks involving both text and structured data, fine-tuning is the preferred choice.
- Task-Specific Training: fine-tuning allows you to refine the model's understanding for domain-specific applications.
In general, you can see if prompt engineering is enough to get the behaviour you want, with the understanding that you will be consuming likely more tokens per interaction because of the need to continually pass in a more detailed system prompt or initial instructions. If you have a narrow use case and want to maximise cost efficiency then fine-tuning would be the way to go.
Developing through Fine-Tuning
Fine-tuning is a valid approach to making GPT exhibit custom, very specific behaviour, tailored for an application. You can really make it adaptable to specialised tasks and tweak the responses and output to what you envision for your app.
There is also a performance improvement by using fine-tuning because you will be replacing a lengthy system prompt and more detailed user prompt by simply leveraging the ingrained new behaviour that has been trained into the model. You will also have the added benefit of lowering the cost of each interaction, since the amount of tokens is the main cost driver, if you are able to get the same output with less input tokens then you will start consuming less resources per conversation.
And finally, fine-tuning allows you to save different versions of the model and evaluate them independently based on different input datasets and evaluation prompts. You can try to do something similar through versioning different text prompts but a lot of the time it is hard to explain or reproduce behaviour variances that appear due to changes in the prompt instructions. Fine-tuning on the other hand allows you to always control very strictly the two inputs to the process: examples and test prompts.
Conclusion
In this blog post, we've explored the intriguing world of fine-tuning GPT to create a parser capable of producing structured JSON output from paragraphs. With a defined JSON schema, training examples, and Azure OpenAI's service tooling, you can customise the model for your specific needs. This scenario showcases the adaptability and versatility of GPT models, opening doors to an array of exciting applications as you build specialised GPT agents that follow instructions better based on your dataset example conversations.
AI Consulting Services
Ready to start your AI journey?
Harnessing the Power of GenAI: Advancements, Applications, and Strategies

No Comments Yet
Let us know what you think